Topic-Guided Reinforcement Learning with LLMs for Enhancing Multi-Document Summarization
作者: Chuyuan Li, Austin Xu, Shafiq Joty, Giuseppe Carenini
分类: cs.CL
发布日期: 2025-09-11
💡 一句话要点
提出主题引导的强化学习方法,利用LLM提升多文档摘要生成效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多文档摘要 强化学习 大型语言模型 主题引导 文本生成
📋 核心要点
- 多文档摘要面临整合多源信息并保持主题一致性的挑战,现有方法难以兼顾信息量和连贯性。
- 论文提出主题引导的强化学习方法,通过主题标签提示和主题奖励机制,提升摘要的主题相关性。
- 实验表明,该方法在Multi-News和Multi-XScience数据集上优于现有基线,验证了主题引导的有效性。
📝 摘要(中文)
多文档摘要(MDS)的一个关键挑战是如何有效地整合来自多个来源的信息,同时保持连贯性和主题相关性。尽管大型语言模型(LLM)在单文档摘要方面表现出了令人印象深刻的结果,但它们在MDS上的性能仍有改进空间。本文提出了一种主题引导的强化学习方法,以改进MDS中的内容选择。我们首先证明,使用主题标签显式地提示模型可以增强生成摘要的信息量。基于这一洞察,我们在Group Relative Policy Optimization(GRPO)框架内提出了一种新的主题奖励,以衡量生成摘要与源文档之间的主题对齐程度。在Multi-News和Multi-XScience数据集上的实验结果表明,我们的方法始终优于强大的基线,突出了在MDS中利用主题线索的有效性。
🔬 方法详解
问题定义:多文档摘要旨在从多个文档中提取关键信息,生成简洁、连贯且主题相关的摘要。现有方法在处理多文档时,难以有效整合信息并保持主题一致性,导致摘要信息量不足或主题偏移。
核心思路:论文的核心思路是利用主题信息引导摘要生成过程。通过显式地向模型提供主题标签,并设计基于主题对齐的奖励函数,鼓励模型生成与源文档主题更相关的摘要。这种方法旨在提升摘要的信息量和主题一致性。
技术框架:该方法基于Group Relative Policy Optimization (GRPO) 框架。首先,利用主题标签提示大型语言模型生成候选摘要。然后,通过主题奖励函数评估候选摘要与源文档的主题对齐程度。最后,使用GRPO算法优化策略,使模型能够生成更高质量的摘要。主要模块包括:主题标签提取模块、摘要生成模块和主题奖励计算模块。
关键创新:关键创新在于引入了主题引导的强化学习方法,将主题信息显式地融入到摘要生成过程中。与传统的强化学习方法相比,该方法能够更有效地利用主题信息,提升摘要的主题相关性和信息量。主题奖励的设计是另一个创新点,它能够准确地衡量摘要与源文档之间的主题对齐程度。
关键设计:主题奖励函数的设计是关键。该函数衡量生成摘要与源文档在主题上的相似度,并将其作为强化学习的奖励信号。具体实现可能涉及计算摘要和源文档的主题分布,并使用KL散度或余弦相似度等指标来衡量它们之间的相似度。此外,主题标签的提取方法和LLM的prompt设计也会影响最终的摘要质量。
🖼️ 关键图片
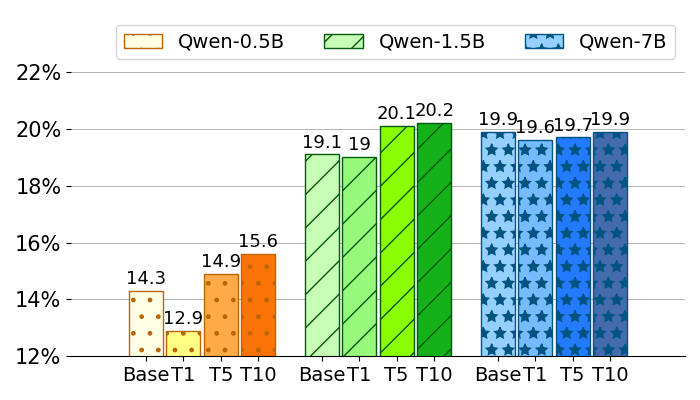

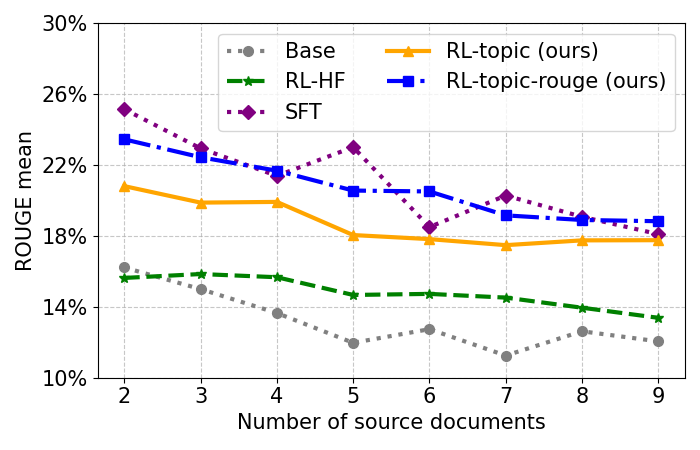
📊 实验亮点
实验结果表明,该方法在Multi-News和Multi-XScience数据集上均取得了显著的性能提升。与现有基线方法相比,该方法在ROUGE指标上取得了明显的优势,证明了主题引导的强化学习在多文档摘要任务中的有效性。具体提升幅度取决于数据集和评价指标,但总体趋势是优于现有方法。
🎯 应用场景
该研究成果可应用于新闻摘要、科研文献综述、金融报告分析等领域。通过自动生成高质量的多文档摘要,可以帮助用户快速了解大量信息,提高信息获取效率。未来,该方法有望应用于更广泛的文本摘要任务,并与其他技术(如知识图谱、信息检索)相结合,实现更智能化的信息处理。
📄 摘要(原文)
A key challenge in Multi-Document Summarization (MDS) is effectively integrating information from multiple sources while maintaining coherence and topical relevance. While Large Language Models have shown impressive results in single-document summarization, their performance on MDS still leaves room for improvement. In this paper, we propose a topic-guided reinforcement learning approach to improve content selection in MDS. We first show that explicitly prompting models with topic labels enhances the informativeness of the generated summaries. Building on this insight, we propose a novel topic reward within the Group Relative Policy Optimization (GRPO) framework to measure topic alignment between the generated summary and source documents. Experimental results on the Multi-News and Multi-XScience datasets demonstrate that our method consistently outperforms strong baselines, highlighting the effectiveness of leveraging topical cues in MDS.