Steering MoE LLMs via Expert (De)Activation
作者: Mohsen Fayyaz, Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Ryan Rossi, Trung Bui, Hinrich Schütze, Nanyun Peng
分类: cs.CL, cs.LG
发布日期: 2025-09-11
💡 一句话要点
SteerMoE:通过专家激活调控MoE LLM的安全性与可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: MoE 大型语言模型 行为调控 安全性 可靠性 专家激活 对抗攻击 对齐伪造
📋 核心要点
- MoE LLM通过专家路由token,但缺乏对专家行为的细粒度控制,导致安全性和可靠性问题。
- SteerMoE通过检测并选择性激活/停用与特定行为相关的专家,实现对MoE模型行为的精准调控。
- 实验表明,SteerMoE显著提升了MoE LLM在安全性与可靠性方面的表现,并揭示了潜在的安全漏洞。
📝 摘要(中文)
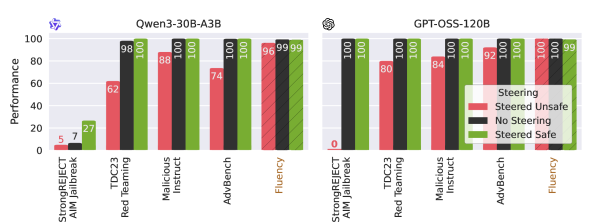
本文提出SteerMoE框架,通过检测和控制行为相关的专家来调控MoE模型。该方法识别在具有对比行为的配对输入中具有不同激活模式的专家。通过在推理过程中选择性地(停)激活这些专家,可以在不重新训练或修改权重的情况下控制诸如可靠性和安全性等行为。在11个基准测试和6个LLM上,SteerMoE将安全性提高了高达+20%,可靠性提高了高达+27%。在对抗攻击模式下,单独使用SteerMoE可使安全性降低-41%,与现有越狱方法结合使用时,安全性降低-100%,绕过所有安全防护措施,并暴露了隐藏在专家内部的对齐伪造的新维度。
🔬 方法详解
问题定义:MoE LLM虽然参数量大,但由于其路由机制,每个token只通过部分专家,这使得模型在安全性和可靠性方面存在潜在问题。现有方法难以对特定专家的行为进行细粒度控制,无法有效提升模型的安全性和可靠性,也难以发现隐藏在专家中的安全漏洞。
核心思路:SteerMoE的核心思路是通过识别与特定行为(例如,安全或不安全)相关的专家,并在推理时选择性地激活或停用这些专家,从而控制模型的整体行为。这种方法无需重新训练模型或修改权重,即可实现对模型行为的精准调控。
技术框架:SteerMoE框架包含两个主要阶段:专家检测和专家调控。在专家检测阶段,首先构建具有对比行为的配对输入(例如,安全提示和不安全提示)。然后,通过分析这些输入在不同专家上的激活模式,识别与特定行为相关的专家。在专家调控阶段,根据期望的行为,选择性地激活或停用这些专家。
关键创新:SteerMoE的关键创新在于提出了一种无需重新训练即可调控MoE LLM行为的方法。通过分析专家激活模式,可以识别与特定行为相关的专家,并利用这些信息来控制模型的输出。这种方法不仅可以提升模型的安全性和可靠性,还可以用于发现隐藏在专家中的安全漏洞。
关键设计:专家检测阶段的关键在于构建具有代表性的配对输入,并选择合适的激活度量来区分不同专家的行为。专家调控阶段的关键在于确定激活或停用哪些专家,以及如何平衡不同专家之间的影响。论文中使用了多种激活度量和调控策略,并进行了实验评估。
🖼️ 关键图片


📊 实验亮点
SteerMoE在11个基准测试和6个LLM上进行了评估,结果表明,SteerMoE可以将安全性提高高达+20%,可靠性提高高达+27%。在对抗攻击模式下,单独使用SteerMoE可使安全性降低-41%,与现有越狱方法结合使用时,安全性降低-100%。这些结果表明,SteerMoE是一种有效的调控MoE LLM行为的方法。
🎯 应用场景
SteerMoE可应用于各种需要安全可靠的LLM应用的场景,例如:内容审核、金融风控、医疗诊断等。通过调控模型的行为,可以有效防止模型生成有害或不准确的内容,提高模型的可靠性和安全性。此外,SteerMoE还可以用于发现和修复LLM中的安全漏洞,提升模型的整体安全性。
📄 摘要(原文)
Mixture-of-Experts (MoE) in Large Language Models (LLMs) routes each token through a subset of specialized Feed-Forward Networks (FFN), known as experts. We present SteerMoE, a framework for steering MoE models by detecting and controlling behavior-linked experts. Our detection method identifies experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors. By selectively (de)activating such experts during inference, we control behaviors like faithfulness and safety without retraining or modifying weights. Across 11 benchmarks and 6 LLMs, our steering raises safety by up to +20% and faithfulness by +27%. In adversarial attack mode, it drops safety by -41% alone, and -100% when combined with existing jailbreak methods, bypassing all safety guardrails and exposing a new dimension of alignment faking hidden within experts.