Bridging the Capability Gap: Joint Alignment Tuning for Harmonizing LLM-based Multi-Agent Systems
作者: Minghang Zhu, Zhengliang Shi, Zhiwei Xu, Shiguang Wu, Lingjie Wang, Pengjie Ren, Zhaochun Ren, Zhumin Chen
分类: cs.CL
发布日期: 2025-09-11
备注: EMNLP 2025 Findings
💡 一句话要点
提出MOAT框架,通过联合对齐调整优化LLM多智能体系统协作能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 联合对齐 迭代优化 能力差距 工具使用 规划智能体 执行智能体
📋 核心要点
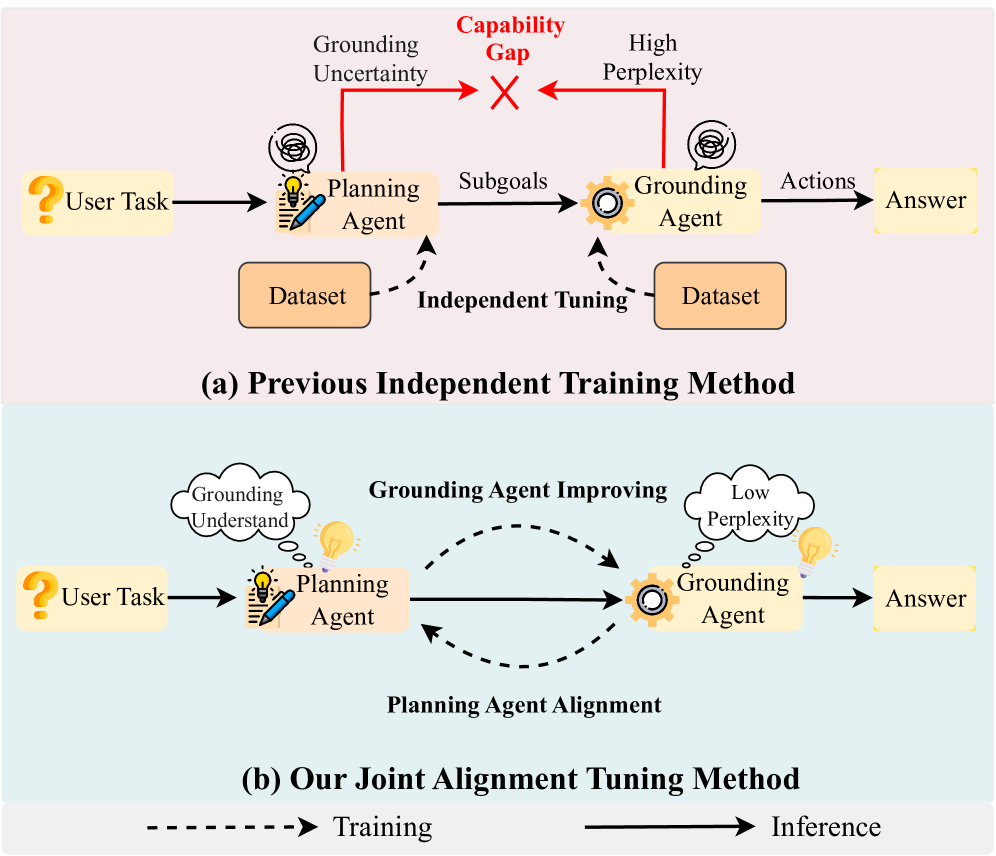
- 现有方法独立微调LLM多智能体系统中的各个智能体,导致智能体间能力不匹配,协作困难。
- MOAT框架通过迭代对齐规划智能体和执行智能体,优化子目标生成和动作执行,提升整体协作能力。
- 实验结果表明,MOAT在多个基准测试中显著优于现有方法,在已见和未见任务上均有提升。
📝 摘要(中文)
大型语言模型(LLMs)的发展使得构建多智能体系统成为可能,通过将复杂任务分解为专门的智能体来解决,例如规划智能体用于生成子目标,执行智能体用于执行工具使用动作。现有方法通常独立地微调这些智能体,导致智能体之间存在能力差距,协作效果不佳。为了解决这个问题,我们提出了MOAT,一个多智能体联合对齐调整框架,通过迭代对齐来提高智能体之间的协作。MOAT在两个关键阶段之间交替进行:(1)规划智能体对齐,优化规划智能体以生成更好地指导执行智能体的子目标序列;(2)执行智能体改进,使用智能体自身生成的各种子目标-动作对来微调执行智能体,以增强其泛化能力。理论分析证明,MOAT确保了一个非递减和逐渐收敛的训练过程。在六个基准测试上的实验表明,MOAT优于最先进的基线,在已见任务上平均提高了3.1%,在未见任务上平均提高了4.4%。
🔬 方法详解
问题定义:现有基于LLM的多智能体系统通常独立训练各个智能体,例如规划智能体和执行智能体。这种独立训练方式导致智能体之间的能力不对齐,规划智能体生成的子目标可能对执行智能体来说难以实现,或者执行智能体无法有效地利用规划智能体提供的子目标,从而降低了整体系统的性能。因此,需要一种方法来协调不同智能体的训练过程,弥合它们之间的能力差距。
核心思路:MOAT的核心思路是通过联合对齐调整来优化多智能体系统的协作能力。具体来说,MOAT迭代地优化规划智能体和执行智能体,使得规划智能体生成的子目标能够更好地指导执行智能体,同时执行智能体能够更好地利用规划智能体提供的子目标。这种迭代优化过程可以逐步弥合智能体之间的能力差距,提高整体系统的性能。
技术框架:MOAT框架包含两个主要阶段:规划智能体对齐和执行智能体改进。在规划智能体对齐阶段,MOAT优化规划智能体,使其生成更适合执行智能体执行的子目标序列。在执行智能体改进阶段,MOAT使用规划智能体生成的子目标-动作对来微调执行智能体,提高其泛化能力。这两个阶段交替进行,直到系统收敛。
关键创新:MOAT的关键创新在于其联合对齐调整策略,通过迭代优化规划智能体和执行智能体,弥合它们之间的能力差距。与现有方法独立训练智能体的方式不同,MOAT考虑了智能体之间的相互依赖关系,从而能够更有效地提高整体系统的性能。此外,MOAT还通过理论分析证明了其训练过程的非递减性和逐渐收敛性。
关键设计:MOAT的具体实现细节包括:(1) 使用特定的损失函数来优化规划智能体,使其生成的子目标更易于执行智能体理解和执行;(2) 使用数据增强技术来生成更多样化的子目标-动作对,以提高执行智能体的泛化能力;(3) 设计合适的迭代停止条件,以确保系统能够收敛到最优解。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MOAT在六个基准测试中均优于最先进的基线方法。具体来说,MOAT在已见任务上平均提高了3.1%,在未见任务上平均提高了4.4%。这些结果表明,MOAT能够有效地提高多智能体系统的协作能力和泛化能力。
🎯 应用场景
MOAT框架可应用于各种需要多智能体协作的复杂任务,例如机器人控制、自动化流程设计、智能客服等。通过优化智能体之间的协作,可以提高任务完成的效率和质量,降低人工干预的需求,具有广泛的应用前景和实际价值。未来,可以将MOAT扩展到更多类型的智能体和更复杂的任务场景。
📄 摘要(原文)
The advancement of large language models (LLMs) has enabled the construction of multi-agent systems to solve complex tasks by dividing responsibilities among specialized agents, such as a planning agent for subgoal generation and a grounding agent for executing tool-use actions. Most existing methods typically fine-tune these agents independently, leading to capability gaps among them with poor coordination. To address this, we propose MOAT, a Multi-Agent Joint Alignment Tuning framework that improves agents collaboration through iterative alignment. MOAT alternates between two key stages: (1) Planning Agent Alignment, which optimizes the planning agent to generate subgoal sequences that better guide the grounding agent; and (2) Grounding Agent Improving, which fine-tunes the grounding agent using diverse subgoal-action pairs generated by the agent itself to enhance its generalization capablity. Theoretical analysis proves that MOAT ensures a non-decreasing and progressively convergent training process. Experiments across six benchmarks demonstrate that MOAT outperforms state-of-the-art baselines, achieving average improvements of 3.1% on held-in tasks and 4.4% on held-out tasks.