GrACE: A Generative Approach to Better Confidence Elicitation in Large Language Models
作者: Zhaohan Zhang, Ziquan Liu, Ioannis Patras
分类: cs.CL
发布日期: 2025-09-11
备注: 20 pages, 11 figures
💡 一句话要点
GrACE:一种生成式方法,提升大语言模型置信度评估的可靠性与可扩展性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 置信度评估 AI安全 生成式方法 模型校准
📋 核心要点
- 现有大语言模型置信度评估方法计算成本高昂或校准效果差,限制了其在高风险场景的应用。
- GrACE通过比较模型隐藏状态与特殊token嵌入的相似度来实时生成置信度,无需额外计算。
- 实验表明,GrACE在开放式生成任务中优于现有方法,并能有效减少测试时所需的样本数量。
📝 摘要(中文)
本文提出了一种名为GrACE的生成式方法,旨在为大语言模型(LLMs)提供可扩展且可靠的置信度评估,以提升AI在高风险应用(如医疗和金融)中的安全性。现有方法要么计算开销巨大,要么校准效果不佳,难以在实际场景中应用。GrACE采用了一种新颖的机制,模型通过最后一个隐藏状态与词汇表中附加的特殊token的嵌入之间的相似性来实时表达置信度。通过微调模型,并使用与准确率相关的校准目标来校准置信度。在三个LLM和两个基准数据集上的实验表明,GrACE产生的置信度在开放式生成任务中实现了最佳的区分能力和校准效果,优于六种竞争方法,且无需额外的采样或辅助模型。此外,本文还提出了两种基于GrACE置信度来改进测试时扩展的策略。实验结果表明,使用GrACE不仅提高了最终决策的准确性,还显著减少了测试时扩展方案中所需的样本数量,表明GrACE有潜力成为一种实用的解决方案,用于部署具有可扩展、可靠和实时置信度估计的LLM。
🔬 方法详解
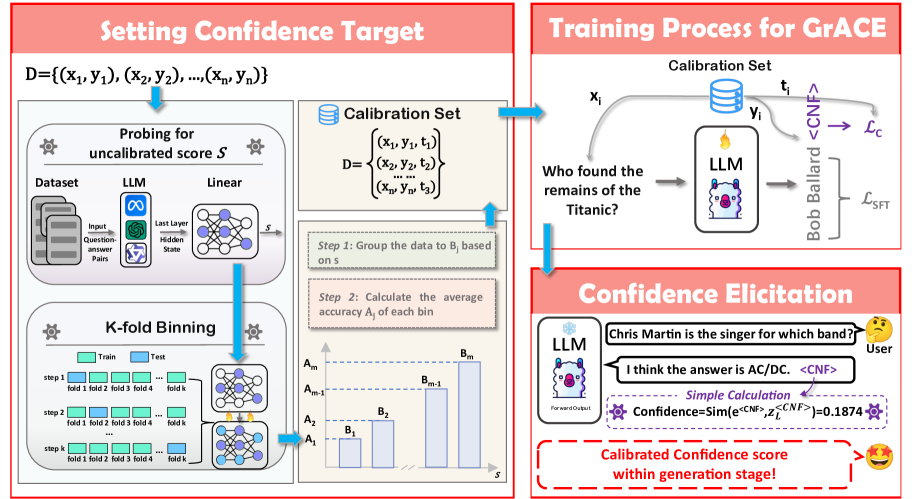
问题定义:现有大语言模型(LLMs)的置信度评估方法存在两个主要问题。一是计算开销大,例如需要进行多次采样或使用额外的辅助模型。二是校准效果不佳,即模型给出的置信度与其真实准确率不匹配,导致在高风险场景下做出错误决策。这些问题限制了LLMs在实际应用中的可靠性和安全性。
核心思路:GrACE的核心思路是利用模型自身的隐藏状态来直接生成置信度,而无需额外的计算或模型。具体来说,GrACE在模型的词汇表中添加一个特殊的token,并通过比较模型最后一个隐藏状态与该token的嵌入之间的相似度来表示置信度。这种方法的优势在于可以实时生成置信度,并且计算开销很小。
技术框架:GrACE的整体框架包括以下几个步骤:1) 在LLM的词汇表中添加一个特殊的token。2) 在训练过程中,使用与准确率相关的校准目标来微调模型,使得模型能够生成与真实准确率相匹配的置信度。3) 在推理过程中,模型通过比较最后一个隐藏状态与特殊token的嵌入之间的相似度来实时生成置信度。4) 利用生成的置信度来改进测试时扩展策略,例如减少所需的样本数量。
关键创新:GrACE的关键创新在于提出了一种基于模型自身隐藏状态的置信度生成方法,该方法无需额外的计算或模型,并且可以实时生成置信度。此外,GrACE还提出了一种基于准确率相关的校准目标来微调模型的方法,使得模型能够生成与真实准确率相匹配的置信度。
关键设计:GrACE的关键设计包括:1) 特殊token的选择:选择一个与任务无关的token,例如一个随机生成的字符串。2) 相似度度量:使用余弦相似度来度量最后一个隐藏状态与特殊token的嵌入之间的相似度。3) 校准目标:使用交叉熵损失函数来校准置信度,其中目标标签是根据模型的准确率生成的。4) 测试时扩展策略:使用置信度来指导样本的选择,例如选择置信度高的样本进行推理。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GrACE在三个LLM和两个基准数据集上均取得了显著的性能提升。具体来说,GrACE在开放式生成任务中实现了最佳的区分能力和校准效果,优于六种竞争方法,且无需额外的采样或辅助模型。此外,使用GrACE可以显著减少测试时扩展方案中所需的样本数量,例如在某些情况下可以减少高达50%的样本数量。
🎯 应用场景
GrACE具有广泛的应用前景,尤其是在需要高可靠性和安全性的领域,如医疗诊断、金融风险评估、自动驾驶等。通过提供可靠的置信度评估,GrACE可以帮助用户更好地理解和信任LLM的决策,从而降低风险并提高效率。未来,GrACE可以进一步扩展到其他类型的模型和任务,并与其他技术相结合,以实现更安全、可靠和可信赖的人工智能系统。
📄 摘要(原文)
Assessing the reliability of Large Language Models (LLMs) by confidence elicitation is a prominent approach to AI safety in high-stakes applications, such as healthcare and finance. Existing methods either require expensive computational overhead or suffer from poor calibration, making them impractical and unreliable for real-world deployment. In this work, we propose GrACE, a Generative Approach to Confidence Elicitation that enables scalable and reliable confidence elicitation for LLMs. GrACE adopts a novel mechanism in which the model expresses confidence by the similarity between the last hidden state and the embedding of a special token appended to the vocabulary, in real-time. We fine-tune the model for calibrating the confidence with calibration targets associated with accuracy. Experiments with three LLMs and two benchmark datasets show that the confidence produced by GrACE achieves the best discriminative capacity and calibration on open-ended generation tasks, outperforming six competing methods without resorting to additional sampling or an auxiliary model. Moreover, we propose two strategies for improving test-time scaling based on confidence induced by GrACE. Experimental results show that using GrACE not only improves the accuracy of the final decision but also significantly reduces the number of required samples in the test-time scaling scheme, indicating the potential of GrACE as a practical solution for deploying LLMs with scalable, reliable, and real-time confidence estimation.