Improving LLM Safety and Helpfulness using SFT and DPO: A Study on OPT-350M
作者: Piyush Pant
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-10
备注: 17 pages, 3 figures. Code and dataset available at https://github.com/PiyushWithPant/Improving-LLM-Safety-and-Helpfulness-using-SFT-and-DPO
💡 一句话要点
SFT与DPO结合提升LLM安全性与有用性:OPT-350M实证研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 大型语言模型 安全性 有用性 监督微调 直接偏好优化 模型对齐 OPT-350M
📋 核心要点
- 现有LLM对齐方法在安全性和有用性之间存在trade-off,且对噪声数据敏感,需要更鲁棒的对齐策略。
- 论文提出结合SFT和DPO的训练方法,利用SFT快速学习,DPO优化偏好,实现优势互补。
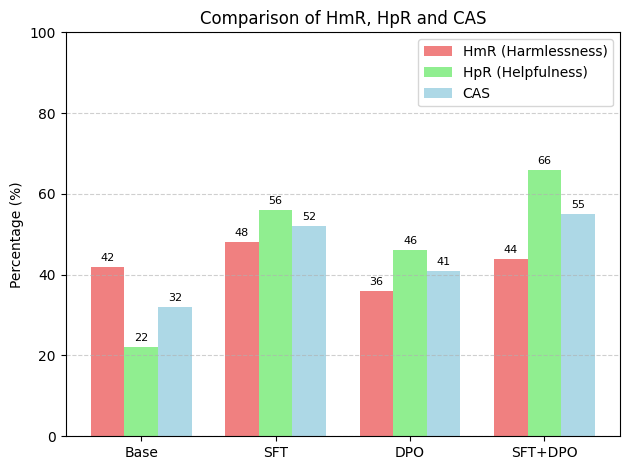
- 实验表明,SFT+DPO模型在无害率、有用率和组合对齐得分上均优于单独使用SFT或DPO的模型。
📝 摘要(中文)
本研究探讨了对齐技术,即监督微调(SFT)、直接偏好优化(DPO)以及SFT+DPO组合方法,在提升OPT-350M语言模型的安全性和有用性方面的有效性。我们利用Anthropic Helpful-Harmless RLHF数据集,训练并评估了四个模型:基础OPT350M模型、SFT模型、DPO模型以及SFT和DPO组合训练的模型。我们引入了三个关键评估指标:无害率(HmR)、有用率(HpR)和组合对齐得分(CAS),所有这些指标均来自奖励模型输出。结果表明,虽然SFT优于DPO,但SFT+DPO组合模型在所有指标上均优于其他模型,证明了这些技术的互补性。我们的研究结果还强调了噪声数据、有限的GPU资源和训练约束所带来的挑战。本研究全面展示了微调策略如何影响模型对齐,并为未来更强大的对齐流程奠定了基础。
🔬 方法详解
问题定义:论文旨在解决如何有效提升大型语言模型(LLM)的安全性(Harmlessness)和有用性(Helpfulness)的问题。现有方法,如单独使用监督微调(SFT)或直接偏好优化(DPO),可能无法同时兼顾这两个目标,或者对训练数据中的噪声过于敏感,导致模型性能下降。
核心思路:论文的核心思路是将SFT和DPO两种方法结合起来,利用SFT快速学习目标任务的知识,并利用DPO根据人类偏好进行优化,从而在安全性和有用性之间找到更好的平衡点。这种结合旨在利用两种方法的优势,克服各自的局限性。
技术框架:整体框架包括以下几个主要阶段:1) 使用Anthropic Helpful-Harmless RLHF数据集;2) 分别训练SFT模型、DPO模型和SFT+DPO组合模型;3) 使用奖励模型评估模型的无害率(HmR)、有用率(HpR)和组合对齐得分(CAS);4) 对比不同模型的性能,分析SFT和DPO的互补性。SFT+DPO模型首先使用SFT进行微调,然后使用DPO进行偏好优化。
关键创新:论文的关键创新在于提出了SFT+DPO的组合训练方法,并验证了其在提升LLM安全性和有用性方面的有效性。与单独使用SFT或DPO相比,该方法能够更好地利用两种方法的优势,从而获得更好的性能。此外,论文还提出了组合对齐得分(CAS)这一综合评估指标。
关键设计:论文使用了OPT-350M作为基础模型,并使用Anthropic Helpful-Harmless RLHF数据集进行训练。SFT使用标准的交叉熵损失函数,DPO使用标准的DPO损失函数。实验中,作者还探讨了不同训练参数对模型性能的影响,并分析了噪声数据对训练的影响。具体参数设置未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
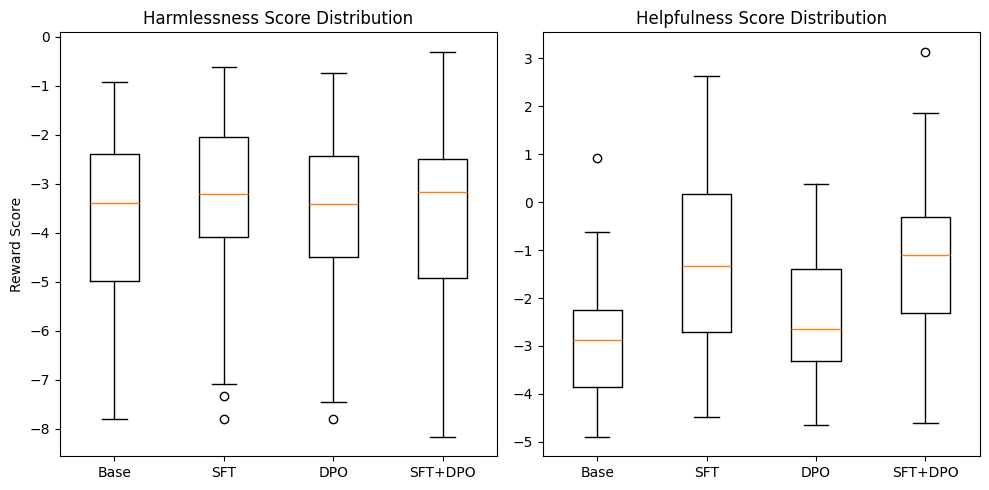
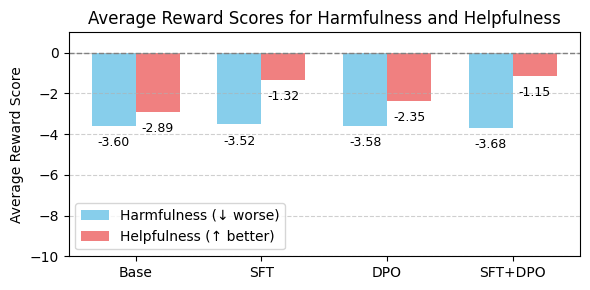
实验结果表明,SFT+DPO组合模型在所有评估指标上均优于单独使用SFT或DPO的模型。具体而言,SFT+DPO模型在无害率、有用率和组合对齐得分上均取得了显著提升,证明了SFT和DPO的互补性。虽然摘要中没有给出具体的性能数据,但结论明确表明了组合方法的优越性。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的LLM的场景,例如智能客服、内容生成、教育辅导等。通过提升LLM的安全性和有用性,可以提高用户满意度,降低潜在风险,并促进LLM在更广泛领域的应用。未来的研究可以探索更有效的SFT和DPO结合方式,以及如何应对噪声数据和有限计算资源带来的挑战。
📄 摘要(原文)
This research investigates the effectiveness of alignment techniques, Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and a combined SFT+DPO approach on improving the safety and helpfulness of the OPT-350M language model. Utilizing the Anthropic Helpful-Harmless RLHF dataset, we train and evaluate four models: the base OPT350M, an SFT model, a DPO model, and a model trained with both SFT and DPO. We introduce three key evaluation metrics: Harmlessness Rate (HmR), Helpfulness Rate (HpR), and a Combined Alignment Score (CAS), all derived from reward model outputs. The results show that while SFT outperforms DPO, The combined SFT+DPO model outperforms all others across all metrics, demonstrating the complementary nature of these techniques. Our findings also highlight challenges posed by noisy data, limited GPU resources, and training constraints. This study offers a comprehensive view of how fine-tuning strategies affect model alignment and provides a foundation for more robust alignment pipelines in future work.