Building High-Quality Datasets for Portuguese LLMs: From Common Crawl Snapshots to Industrial-Grade Corpora
作者: Thales Sales Almeida, Rodrigo Nogueira, Helio Pedrini
分类: cs.CL
发布日期: 2025-09-10
💡 一句话要点
提出葡萄牙语LLM高质量数据集构建方法,性能媲美工业级语料库
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 葡萄牙语 数据集构建 数据清洗 持续预训练 自然语言处理 多语言模型
📋 核心要点
- 现有LLM训练数据构建工作主要集中在英语,缺乏针对其他语言有效训练语料库的构建方法。
- 本文探索了构建基于Web的LLM语料库的可扩展方法,重点关注数据选择和预处理策略。
- 实验结果表明,特定于语言的过滤管道能有效提升模型性能,验证了高质量、特定语言数据的重要性。
📝 摘要(中文)
大型语言模型(LLM)的性能深受其训练数据的质量和组成的影响。虽然现有的工作主要集中在英语上,但对于如何构建其他语言的有效训练语料库仍然存在差距。本文探索了构建基于Web的LLM语料库的可扩展方法,并将其应用于构建一个新的1200亿token的葡萄牙语语料库,该语料库的性能与工业级语料库相当。通过持续预训练设置,研究了不同的数据选择和预处理策略在将最初用英语训练的模型过渡到另一种语言时如何影响LLM的性能。研究结果表明,特定于语言的过滤管道(包括教育、科学、技术、工程和数学(STEM)以及有毒内容分类器)的价值。结果表明,使模型适应目标语言可以提高性能,从而加强了高质量、特定于语言的数据的重要性。虽然案例研究侧重于葡萄牙语,但本文的方法适用于其他语言,为多语言LLM开发提供了见解。
🔬 方法详解
问题定义:论文旨在解决如何为葡萄牙语等非英语语言的大型语言模型构建高质量训练数据集的问题。现有方法在构建非英语语料库时,往往缺乏针对特定语言的优化,导致模型性能受限。痛点在于如何有效地从Common Crawl等大规模Web数据中筛选出高质量的、特定于目标语言的内容,并去除噪声和有害信息。
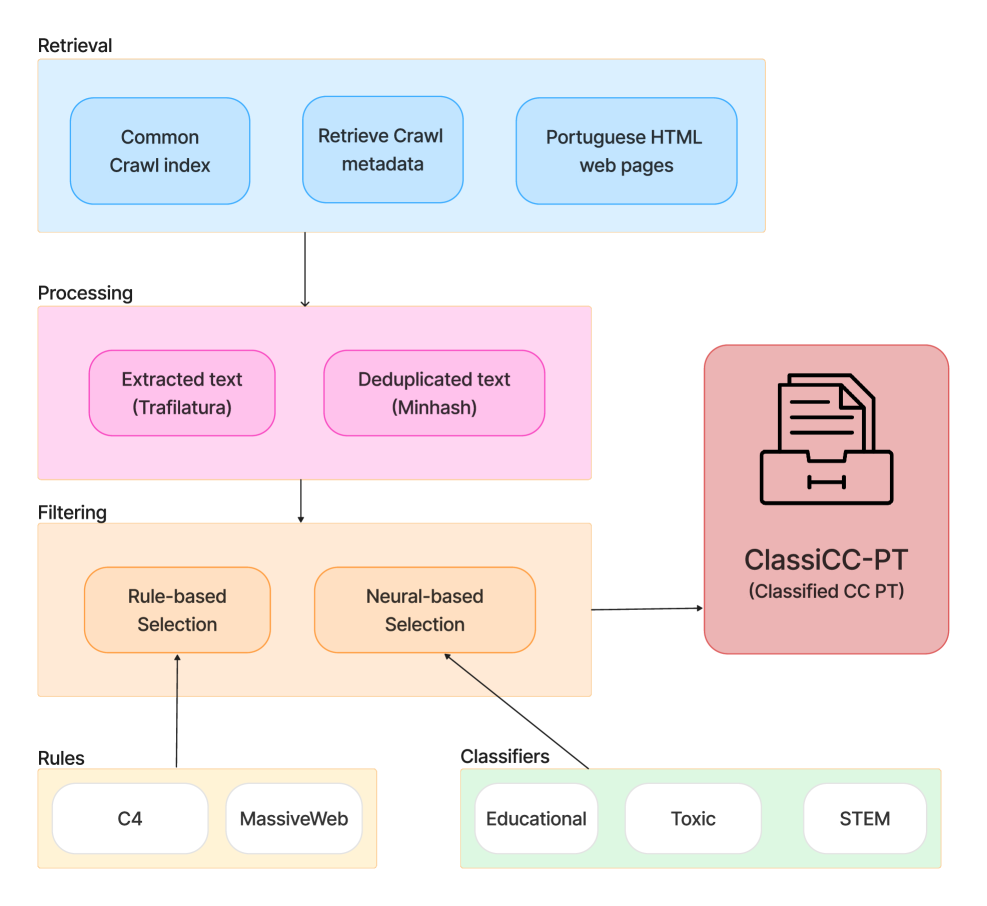
核心思路:论文的核心思路是构建一个特定于葡萄牙语的、包含多阶段过滤和清洗流程的数据集构建pipeline。该pipeline利用语言特定的分类器来识别和保留高质量的文本,同时过滤掉低质量和有害的内容。通过持续预训练,将模型从英语迁移到葡萄牙语,并评估不同数据选择策略对模型性能的影响。
技术框架:整体框架包含以下几个主要阶段:1) 从Common Crawl快照中提取文本数据;2) 应用语言识别模型过滤非葡萄牙语文本;3) 使用多个分类器(如STEM分类器、毒性内容分类器)对数据进行分类和过滤;4) 对数据进行去重和清洗;5) 使用清洗后的数据进行持续预训练。
关键创新:论文的关键创新在于提出了一个针对葡萄牙语的、多阶段的数据过滤和清洗pipeline,该pipeline集成了语言特定的分类器,能够有效地识别和过滤高质量的STEM内容以及有害内容。此外,论文还研究了不同的数据选择策略对模型性能的影响,为构建其他语言的高质量语料库提供了参考。
关键设计:关键设计包括:1) 使用预训练的语言模型作为STEM分类器,以识别高质量的科学、技术、工程和数学领域的文本;2) 使用毒性内容分类器过滤有害信息,保证数据的安全性;3) 通过持续预训练的方式,将模型从英语迁移到葡萄牙语,并评估不同数据选择策略对模型性能的影响;4) 实验中使用了120B token的葡萄牙语语料库进行训练,并与工业级语料库进行了对比。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用本文构建的120B token葡萄牙语语料库训练的LLM,其性能与使用工业级语料库训练的模型相当。通过持续预训练,模型在葡萄牙语任务上的性能得到了显著提升,验证了语言特定过滤pipeline的有效性。STEM分类器和毒性内容分类器的应用,有效提升了数据集的质量和安全性。
🎯 应用场景
该研究成果可应用于构建各种非英语语言的大型语言模型,尤其是在资源相对匮乏的语言上。高质量的语料库能够提升LLM在特定语言环境下的性能,从而促进自然语言处理技术在当地的应用,例如智能客服、机器翻译、内容生成等。该方法也为多语言LLM的开发提供了有价值的参考。
📄 摘要(原文)
The performance of large language models (LLMs) is deeply influenced by the quality and composition of their training data. While much of the existing work has centered on English, there remains a gap in understanding how to construct effective training corpora for other languages. We explore scalable methods for building web-based corpora for LLMs. We apply them to build a new 120B token corpus in Portuguese that achieves competitive results to an industrial-grade corpus. Using a continual pretraining setup, we study how different data selection and preprocessing strategies affect LLM performance when transitioning a model originally trained in English to another language. Our findings demonstrate the value of language-specific filtering pipelines, including classifiers for education, science, technology, engineering, and mathematics (STEM), as well as toxic content. We show that adapting a model to the target language leads to performance improvements, reinforcing the importance of high-quality, language-specific data. While our case study focuses on Portuguese, our methods are applicable to other languages, offering insights for multilingual LLM development.