Too Helpful, Too Harmless, Too Honest or Just Right?
作者: Gautam Siddharth Kashyap, Mark Dras, Usman Naseem
分类: cs.CL
发布日期: 2025-09-10 (更新: 2025-09-15)
备注: EMNLP'25 Main
💡 一句话要点
TrinityX:提出一种基于校准专家混合的模块化对齐框架,提升LLM的HHH对齐效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 混合专家模型 有用性 无害性 诚实性 校准路由 模块化框架
📋 核心要点
- 现有LLM对齐方法通常孤立优化有用性、无害性和诚实性,导致性能权衡和行为不一致。
- TrinityX提出一种模块化框架,利用校准专家混合(MoCaE)在Transformer中实现HHH对齐。
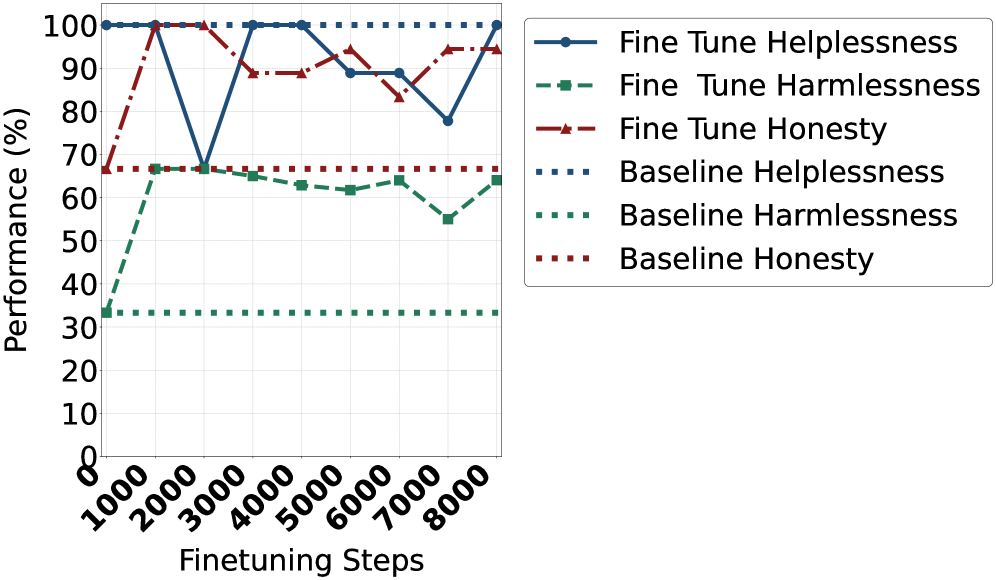
- 实验表明TrinityX在HHH基准测试中显著优于现有方法,并降低了内存使用和推理延迟。
📝 摘要(中文)
大型语言模型(LLM)在各种NLP任务中表现出色,但将其输出与Helpfulness(有用性)、Harmlessness(无害性)和Honesty(诚实性)(HHH)原则对齐仍然是一个挑战。现有方法通常孤立地优化单个对齐维度,导致权衡和不一致的行为。混合专家(MoE)架构虽然具有模块化,但其路由校准不佳,限制了其在对齐任务中的有效性。我们提出了TrinityX,一个模块化对齐框架,它在Transformer架构中结合了校准专家混合(MoCaE)。TrinityX利用针对每个HHH维度单独训练的专家,通过校准的、任务自适应的路由机制整合它们的输出,将专家信号组合成统一的、感知对齐的表示。在三个标准对齐基准(Alpaca(有用性)、BeaverTails(无害性)和TruthfulQA(诚实性))上的大量实验表明,TrinityX优于强大的基线,在胜率、安全分数和真实性方面分别实现了32.5%、33.9%和28.4%的相对改进。此外,与之前的基于MoE的方法相比,TrinityX减少了超过40%的内存使用和推理延迟。消融研究突出了校准路由的重要性,跨模型评估证实了TrinityX在不同LLM骨干上的泛化能力。
🔬 方法详解
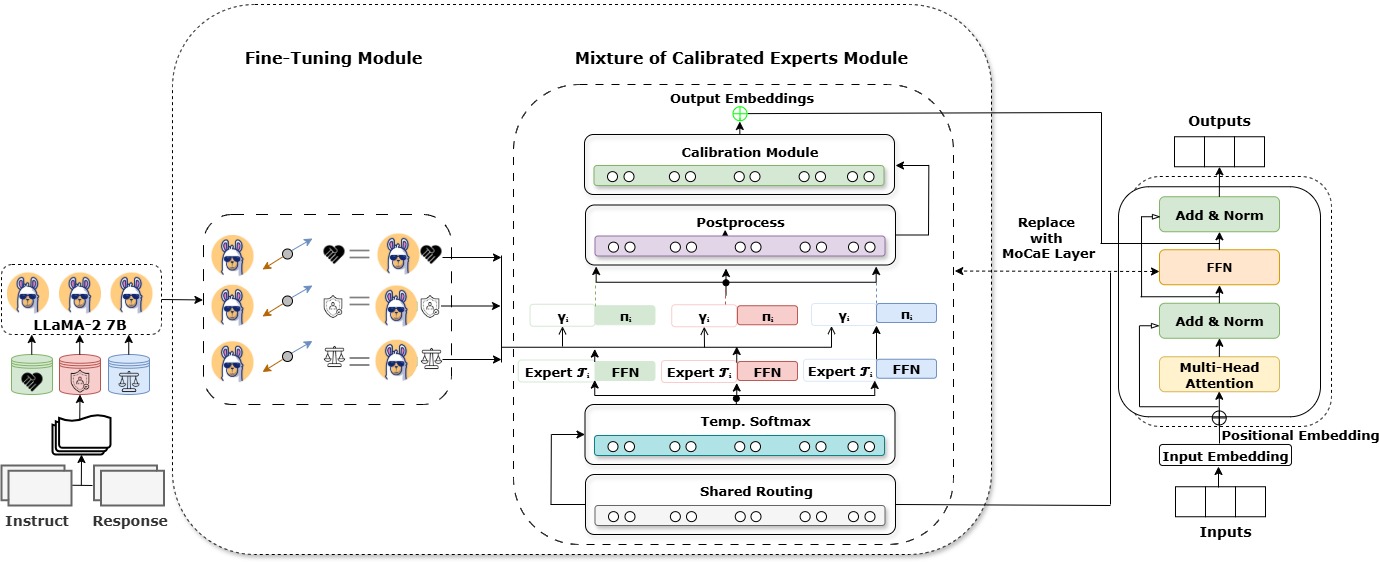
问题定义:现有的大型语言模型(LLM)在对齐方面存在挑战,尤其是在有用性(Helpfulness)、无害性(Harmlessness)和诚实性(Honesty)(HHH)这三个维度上。现有方法通常独立地优化这些维度,导致模型在不同维度之间做出妥协,无法同时保证所有维度的良好表现。此外,现有的混合专家(MoE)方法虽然具有模块化的潜力,但其路由机制校准不足,无法有效地将不同专家的知识整合起来,限制了其在对齐任务中的应用。
核心思路:TrinityX的核心思路是构建一个模块化的对齐框架,该框架能够同时优化LLM的有用性、无害性和诚实性。它通过引入校准专家混合(MoCaE)机制,将针对每个HHH维度单独训练的专家模型的知识整合起来。这种设计允许模型根据不同的任务需求,动态地调整不同专家的权重,从而实现更好的对齐效果。
技术框架:TrinityX的整体架构是在Transformer模型中嵌入MoCaE模块。该框架包含以下主要模块:1) HHH专家:针对每个HHH维度(有用性、无害性、诚实性)训练独立的专家模型。2) 校准路由机制:根据输入任务的特点,动态地计算每个专家的权重。3) 专家混合:将不同专家的输出按照计算得到的权重进行混合,得到最终的输出。整个流程可以概括为:输入文本 -> 校准路由 -> 专家输出 -> 专家混合 -> 最终输出。
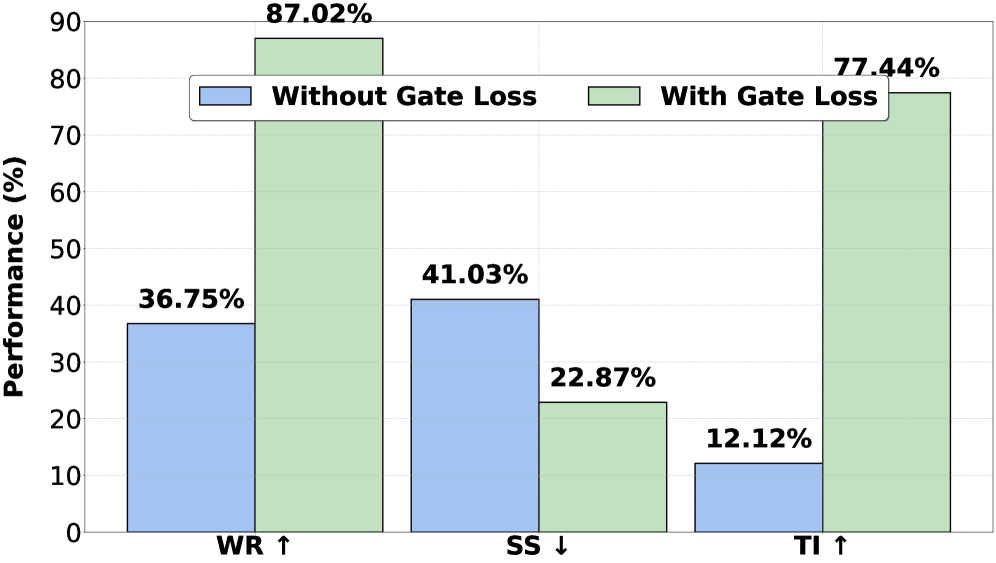
关键创新:TrinityX的关键创新在于其校准路由机制。传统的MoE方法通常使用简单的路由算法,例如Top-K路由,这种算法无法准确地反映不同专家对特定任务的贡献程度。TrinityX通过引入校准机制,学习一个能够准确预测专家贡献的路由函数。这种校准机制能够更好地利用不同专家的知识,从而提高对齐效果。
关键设计:TrinityX的关键设计包括:1) 专家模型的训练:针对每个HHH维度,使用特定的数据集和损失函数训练专家模型。2) 校准路由函数的学习:使用一个独立的神经网络学习路由函数,该网络以输入文本和专家输出为输入,输出每个专家的权重。3) 专家混合策略:使用加权平均的方式将不同专家的输出进行混合,权重由校准路由函数计算得到。具体的损失函数和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
TrinityX在Alpaca(有用性)、BeaverTails(无害性)和TruthfulQA(诚实性)三个标准对齐基准上取得了显著的性能提升。具体而言,在胜率方面提升了32.5%,在安全分数方面提升了33.9%,在真实性方面提升了28.4%。此外,TrinityX还降低了超过40%的内存使用和推理延迟,使其更适用于实际应用。
🎯 应用场景
TrinityX具有广泛的应用前景,可用于提升各种LLM的安全性、可靠性和实用性。例如,可以应用于智能客服、内容生成、教育辅导等领域,确保LLM在提供服务的同时,避免产生有害、不真实或不恰当的内容。此外,该研究对于开发更加可信赖和负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) exhibit strong performance across a wide range of NLP tasks, yet aligning their outputs with the principles of Helpfulness, Harmlessness, and Honesty (HHH) remains a persistent challenge. Existing methods often optimize for individual alignment dimensions in isolation, leading to trade-offs and inconsistent behavior. While Mixture-of-Experts (MoE) architectures offer modularity, they suffer from poorly calibrated routing, limiting their effectiveness in alignment tasks. We propose TrinityX, a modular alignment framework that incorporates a Mixture of Calibrated Experts (MoCaE) within the Transformer architecture. TrinityX leverages separately trained experts for each HHH dimension, integrating their outputs through a calibrated, task-adaptive routing mechanism that combines expert signals into a unified, alignment-aware representation. Extensive experiments on three standard alignment benchmarks-Alpaca (Helpfulness), BeaverTails (Harmlessness), and TruthfulQA (Honesty)-demonstrate that TrinityX outperforms strong baselines, achieving relative improvements of 32.5% in win rate, 33.9% in safety score, and 28.4% in truthfulness. In addition, TrinityX reduces memory usage and inference latency by over 40% compared to prior MoE-based approaches. Ablation studies highlight the importance of calibrated routing, and cross-model evaluations confirm TrinityX's generalization across diverse LLM backbones.