Bias after Prompting: Persistent Discrimination in Large Language Models
作者: Nivedha Sivakumar, Natalie Mackraz, Samira Khorshidi, Krishna Patel, Barry-John Theobald, Luca Zappella, Nicholas Apostoloff
分类: cs.CL, cs.LG
发布日期: 2025-09-09 (更新: 2025-11-19)
💡 一句话要点
揭示Prompting后的大语言模型偏见:持续存在的歧视现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见转移 Prompting 公平性 因果模型
📋 核心要点
- 现有研究假设大语言模型偏见不会转移到prompt适应后的模型,但实际应用中prompting非常普遍。
- 该研究通过因果模型分析,发现偏见确实会通过prompting转移,且现有缓解方法效果不佳。
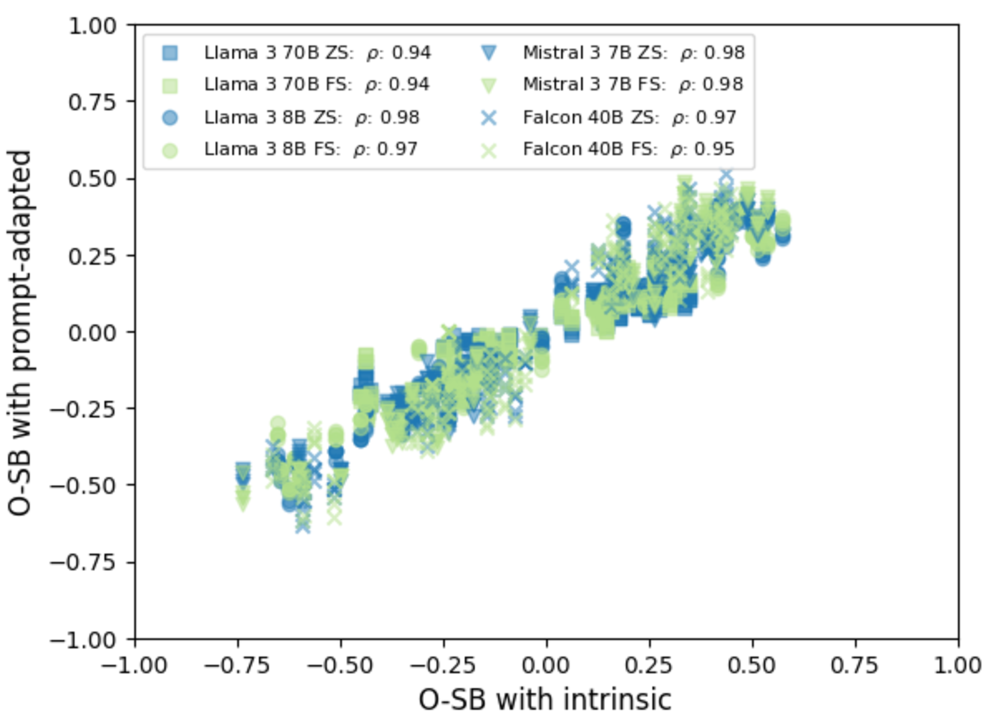
- 实验表明,内在偏见与prompt适应后的偏见高度相关,且少样本参数变化不会显著降低偏见。
📝 摘要(中文)
先前关于偏见转移假设(BTH)的研究可能存在一个危险的假设,即预训练的大语言模型(LLM)中的偏见不会转移到经过适应的模型中。本文通过研究因果模型中prompt适应下的BTH,从而否定了这一假设,因为prompting是实际应用中一种极其流行和易于使用的适应策略。与先前工作相反,我们发现偏见可以通过prompting转移,并且流行的基于prompt的缓解方法并不能始终如一地防止偏见转移。具体而言,内在偏见与prompt适应后的偏见之间的相关性在不同的人口统计和任务中保持中等到强烈的程度——例如,在共指消解中性别(rho >= 0.94),在问答中年龄(rho >= 0.98)和宗教(rho >= 0.69)。此外,我们发现当改变少样本组合参数时,例如样本大小、刻板印象内容、职业分布和代表性平衡(rho >= 0.90),偏见仍然高度相关。我们评估了几种基于prompt的去偏见策略,发现不同的方法有不同的优势,但没有一种方法能够始终如一地减少跨模型、任务或人口统计的偏见转移。这些结果表明,纠正内在模型中的偏见,并可能提高推理能力,可以防止偏见传播到下游任务。
🔬 方法详解
问题定义:现有研究低估了预训练大语言模型中偏见通过Prompting传递的风险,认为Prompting是一种有效的偏见缓解手段。然而,在实际应用中,Prompting作为一种主要的适应策略,其潜在的偏见传递问题并未得到充分重视。现有方法难以有效且一致地防止偏见在Prompting过程中的扩散。
核心思路:该研究的核心在于验证偏见转移假设(BTH)在Prompting适应下的有效性。通过分析内在偏见与Prompting后偏见的相关性,揭示Prompting作为一种适应策略,实际上可能加剧而非缓解偏见。研究还评估了多种Prompting去偏见策略的有效性。
技术框架:该研究主要采用因果模型来分析偏见转移。具体流程包括:1) 评估预训练模型的内在偏见;2) 通过不同的Prompting策略(包括少样本学习、改变样本组成等)对模型进行适应;3) 评估Prompting后模型的偏见;4) 计算内在偏见与Prompting后偏见的相关性,以量化偏见转移程度;5) 评估不同的Prompting去偏见策略的效果。
关键创新:该研究的主要创新在于:1) 否定了Prompting可以有效缓解偏见的假设,证明偏见可以通过Prompting传递;2) 系统性地评估了多种Prompting去偏见策略的有效性,发现没有一种策略能够始终如一地减少偏见转移;3) 通过因果模型量化了内在偏见与Prompting后偏见的相关性,为偏见分析提供了新的视角。
关键设计:研究中关键的设计包括:1) 使用多种任务(如共指消解、问答)和人口统计变量(如性别、年龄、宗教)来评估偏见;2) 改变少样本学习的参数,如样本大小、刻板印象内容、职业分布和代表性平衡,以评估其对偏见转移的影响;3) 评估多种Prompting去偏见策略,如对抗训练、数据增强等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,内在偏见与Prompting后的偏见之间存在高度相关性(例如,共指消解中性别rho >= 0.94,问答中年龄rho >= 0.98,宗教rho >= 0.69)。即使改变少样本学习的参数,偏见仍然高度相关(rho >= 0.90)。多种Prompting去偏见策略的效果有限,无法始终如一地减少偏见转移。
🎯 应用场景
该研究成果对大语言模型的安全部署具有重要意义。理解Prompting带来的偏见转移风险,有助于开发更有效的去偏见方法,避免模型在实际应用中产生歧视性行为。该研究还可应用于评估和改进现有的Prompting策略,确保模型输出的公平性和公正性。
📄 摘要(原文)
A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.