MERLIN: Multi-Stage Curriculum Alignment for Multilingual Encoder-LLM Integration in Cross-Lingual Reasoning
作者: Kosei Uemura, David Guzmán, Quang Phuoc Nguyen, Jesujoba Oluwadara Alabi, En-shiun Annie Lee, David Ifeoluwa Adelani
分类: cs.CL
发布日期: 2025-09-09 (更新: 2025-11-10)
备注: under submission
💡 一句话要点
MERLIN:多阶段课程对齐,提升跨语言推理中多语言编码器-LLM集成效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言推理 低资源语言 课程学习 模型堆叠 多语言编码器 大型语言模型 DoRA权重
📋 核心要点
- 现有编码器-解码器方法在低资源语言的复杂推理任务中表现不佳,存在显著的性能差距。
- MERLIN采用两阶段模型堆叠和课程学习策略,从通用双语数据到特定任务数据逐步训练模型。
- 实验表明,MERLIN在AfriMGSM上显著优于MindMerger和GPT-4o-mini,并在MGSM和MSVAMP上取得一致提升。
📝 摘要(中文)
大型语言模型在英语方面表现出色,但在许多低资源语言(LRL)中进行复杂的推理仍然面临挑战。现有的编码器-解码器方法,如LangBridge和MindMerger,提高了中高资源语言的准确性,但在低资源语言上仍然存在很大差距。我们提出了MERLIN,一个两阶段模型堆叠框架,它应用了一种课程学习策略——从通用的双语平行语料到特定任务的数据——并且只调整一小部分DoRA权重。在AfriMGSM基准测试中,MERLIN的精确匹配准确率比MindMerger提高了+12.9个百分点,并且优于GPT-4o-mini。它还在MGSM和MSVAMP上产生了持续的收益(+0.9和+2.8个百分点),证明了其在低资源和高资源环境中的有效性。
🔬 方法详解
问题定义:论文旨在解决低资源语言(LRLs)在复杂推理任务中,现有编码器-解码器模型性能不足的问题。现有方法如LangBridge和MindMerger虽然在中高资源语言上有所提升,但在LRLs上仍然存在显著的性能差距,无法有效利用LRLs的语言特性进行推理。
核心思路:MERLIN的核心思路是利用课程学习策略,从易到难地训练模型。首先,利用通用的双语平行语料进行预训练,使模型具备基本的跨语言理解能力。然后,利用特定任务的数据进行微调,使模型能够更好地适应目标任务。此外,MERLIN还采用模型堆叠的方式,将编码器和LLM进行有效集成。
技术框架:MERLIN是一个两阶段的模型堆叠框架。第一阶段,使用多语言编码器(例如,mBERT或XLM-R)对输入文本进行编码。第二阶段,将编码器的输出作为LLM的输入,利用LLM进行推理和生成答案。在训练过程中,采用课程学习策略,首先使用通用的双语平行语料进行预训练,然后使用特定任务的数据进行微调。框架的关键在于DoRA权重的调整,以实现高效的参数更新。
关键创新:MERLIN的关键创新在于多阶段课程对齐策略和DoRA权重的应用。课程对齐策略使得模型能够从易到难地学习跨语言推理能力,避免了直接在低资源数据上训练导致的过拟合问题。DoRA权重允许模型在微调过程中只调整一小部分参数,从而提高了训练效率和泛化能力。
关键设计:MERLIN的关键设计包括:1) 两阶段模型堆叠架构,有效结合了编码器和LLM的优势;2) 课程学习策略,从通用双语数据到特定任务数据逐步训练;3) DoRA权重调整,高效地进行参数更新;4) 损失函数的设计,可能包括交叉熵损失或对比学习损失,以优化模型的跨语言理解和推理能力。具体的参数设置和网络结构细节可能在论文的实验部分进行详细描述。
🖼️ 关键图片

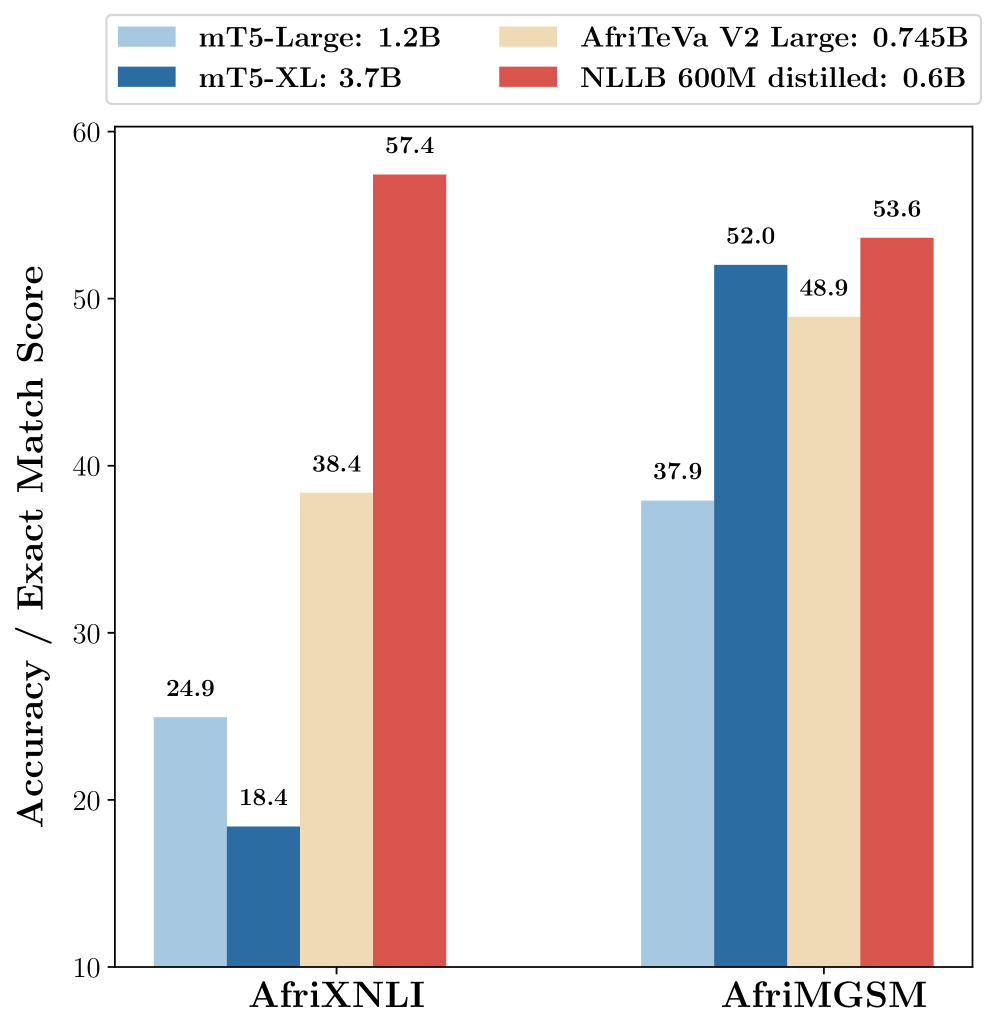
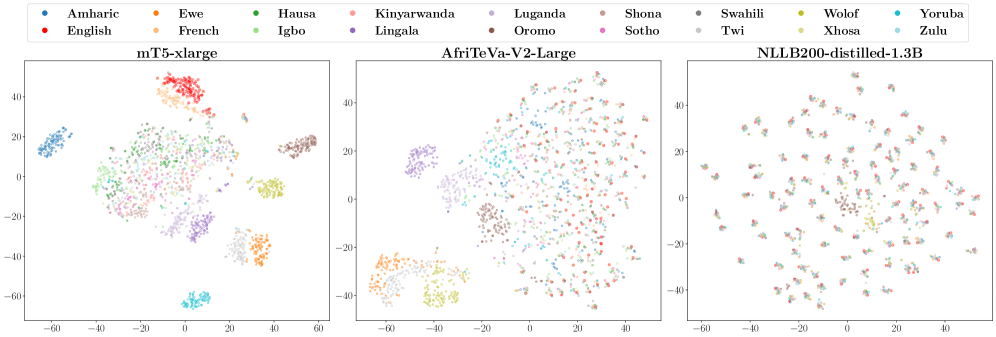
📊 实验亮点
MERLIN在AfriMGSM基准测试中,精确匹配准确率比MindMerger提高了+12.9个百分点,并且优于GPT-4o-mini。同时,在MGSM和MSVAMP数据集上也取得了持续的收益,分别提升了+0.9和+2.8个百分点。这些结果表明,MERLIN在低资源和高资源环境下都具有显著的性能优势。
🎯 应用场景
MERLIN的研究成果可应用于多语言智能客服、跨语言信息检索、机器翻译等领域。通过提升低资源语言的推理能力,可以使更多人受益于人工智能技术,促进全球范围内的信息交流和知识共享。未来,该方法有望扩展到更多复杂的跨语言任务,例如多语言文档摘要、跨语言问答等。
📄 摘要(原文)
Large language models excel in English but still struggle with complex reasoning in many low-resource languages (LRLs). Existing encoder-plus-decoder methods such as LangBridge and MindMerger raise accuracy on mid and high-resource languages, yet they leave a large gap on LRLs. We present MERLIN, a two-stage model-stacking framework that applies a curriculum learning strategy -- from general bilingual bitext to task-specific data -- and adapts only a small set of DoRA weights. On the AfriMGSM benchmark MERLIN improves exact-match accuracy by +12.9 pp over MindMerger and outperforms GPT-4o-mini. It also yields consistent gains on MGSM and MSVAMP (+0.9 and +2.8 pp), demonstrating effectiveness across both low and high-resource settings.