Evolution and compression in LLMs: On the emergence of human-aligned categorization
作者: Nathaniel Imel, Noga Zaslavsky
分类: cs.CL
发布日期: 2025-09-09 (更新: 2025-12-01)
备注: Accepted at CogInterp: Interpreting Cognition in Deep Learning Models Workshop at NeurIPS 2025
💡 一句话要点
研究表明大型语言模型能涌现与人类对齐的语义分类能力,并实现信息瓶颈效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语义分类 信息瓶颈 文化演化 上下文学习 颜色命名 认知科学
📋 核心要点
- 现有大型语言模型未针对信息瓶颈优化,缺乏对人类语义分类的有效模拟。
- 论文提出迭代上下文语言学习(IICLL)方法,模拟LLM中伪颜色命名系统的文化演化。
- 实验表明,LLM能自发地将随机系统重构为更高信息瓶颈效率,涌现人类对齐的语义分类。
📝 摘要(中文)
大量证据表明,人类的语义类别系统通过信息瓶颈(IB)的复杂性-准确性权衡实现了近乎最优的压缩。大型语言模型(LLM)并非为此目标而训练,这引出了一个问题:LLM是否能够演化出高效的、与人类对齐的语义系统?为了解决这个问题,我们以颜色分类为重点——这是认知类别理论的关键试验台,拥有非常丰富的人类数据——并使用LLM复制了两项有影响力的人类研究。首先,我们进行了一项英语颜色命名研究,表明LLM在复杂性和英语对齐方面差异很大,而更大的指令调整模型实现了更好的对齐和IB效率。其次,为了测试这些LLM是否仅仅模仿其训练数据中的模式,或者实际上表现出类似人类的、趋向于IB效率的归纳偏置,我们通过一种称为迭代上下文语言学习(IICLL)的方法,在LLM中模拟了伪颜色命名系统的文化演化。我们发现,与人类类似,LLM迭代地将最初随机的系统重构为更高的IB效率。然而,只有具有最强上下文能力的模型(Gemini 2.0)能够重现人类观察到的各种近乎最优的IB权衡,而其他最先进的模型则收敛到低复杂度的解决方案。这些发现表明,与人类语义效率的基本原理相同,与人类对齐的语义类别可以在LLM中涌现。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)是否能够像人类一样,演化出高效且与人类认知对齐的语义分类系统。现有方法主要集中在训练数据和模型规模上,忽略了模型本身是否具备类似人类的归纳偏置,即通过信息瓶颈(IB)原则实现复杂性与准确性的平衡。
核心思路:论文的核心思路是通过模拟文化演化过程,观察LLM在没有明确IB目标训练的情况下,是否能够自发地优化其语义分类系统,使其更接近人类的分类方式。这种模拟通过迭代上下文语言学习(IICLL)实现,让LLM在每一轮迭代中学习并改进其颜色命名系统。
技术框架:整体框架包含两个主要部分:1) 英语颜色命名研究,评估LLM在颜色命名任务上的表现,并与人类数据进行比较;2) 迭代上下文语言学习(IICLL),模拟颜色命名系统的文化演化。IICLL涉及初始化随机颜色命名系统,然后通过LLM进行多轮迭代,每一轮LLM根据上一轮的结果进行学习和改进。
关键创新:关键创新在于提出了迭代上下文语言学习(IICLL)方法,这是一种新颖的模拟文化演化的方式,用于研究LLM的归纳偏置和语义涌现能力。与直接评估LLM在现有数据集上的表现不同,IICLL允许研究人员观察LLM如何从零开始构建和优化语义系统。
关键设计:IICLL的关键设计包括:1) 颜色空间的表示方式(例如,RGB或CIELAB);2) 颜色命名系统的初始化方法(例如,随机分配颜色名称);3) LLM的学习方式(例如,通过上下文学习或微调);4) 迭代轮数和停止条件;5) 信息瓶颈(IB)效率的计算方法,用于评估颜色命名系统的复杂性和准确性。
🖼️ 关键图片

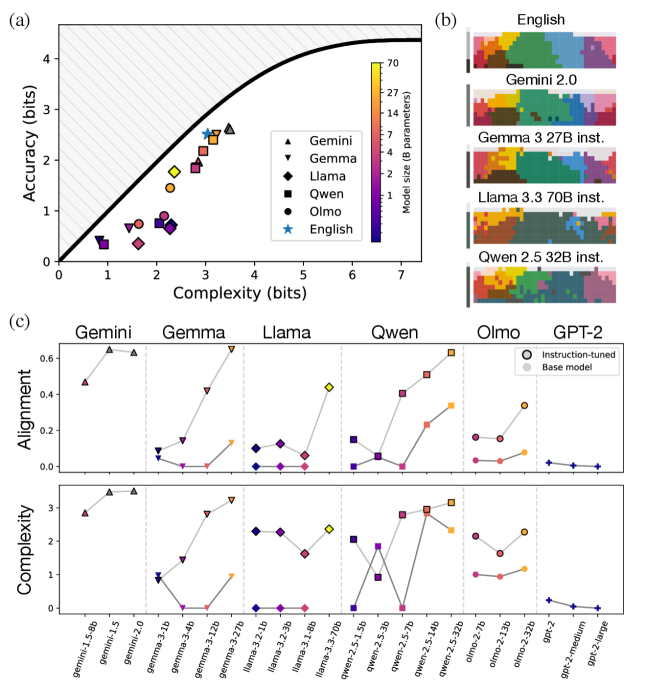

📊 实验亮点
实验结果表明,大型语言模型(特别是Gemini 2.0)能够通过迭代上下文语言学习(IICLL)方法,自发地将随机颜色命名系统重构为更高信息瓶颈效率的系统,并重现人类观察到的各种近乎最优的IB权衡。其他先进模型虽然也能提升IB效率,但最终收敛到低复杂度的解决方案,表明Gemini 2.0具有更强的上下文学习能力。
🎯 应用场景
该研究成果可应用于提升语言模型的语义理解能力,使其更符合人类认知习惯。通过理解LLM如何涌现人类对齐的语义系统,可以更好地设计和训练LLM,使其在自然语言处理、人机交互等领域表现更佳。此外,该研究也为理解人类认知和文化演化提供了新的视角。
📄 摘要(原文)
Converging evidence suggests that human systems of semantic categories achieve near-optimal compression via the Information Bottleneck (IB) complexity-accuracy tradeoff. Large language models (LLMs) are not trained for this objective, which raises the question: are LLMs capable of evolving efficient human-aligned semantic systems? To address this question, we focus on color categorization -- a key testbed of cognitive theories of categorization with uniquely rich human data -- and replicate with LLMs two influential human studies. First, we conduct an English color-naming study, showing that LLMs vary widely in their complexity and English-alignment, with larger instruction-tuned models achieving better alignment and IB-efficiency. Second, to test whether these LLMs simply mimic patterns in their training data or actually exhibit a human-like inductive bias toward IB-efficiency, we simulate cultural evolution of pseudo color-naming systems in LLMs via a method we refer to as Iterated in-Context Language Learning (IICLL). We find that akin to humans, LLMs iteratively restructure initially random systems towards greater IB-efficiency. However, only a model with strongest in-context capabilities (Gemini 2.0) is able to recapitulate the wide range of near-optimal IB-tradeoffs observed in humans, while other state-of-the-art models converge to low-complexity solutions. These findings demonstrate how human-aligned semantic categories can emerge in LLMs via the same fundamental principle that underlies semantic efficiency in humans.