No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
作者: Flor Miriam Plaza-del-Arco, Paul Röttger, Nino Scherrer, Emanuele Borgonovo, Elmar Plischke, Dirk Hovy
分类: cs.CL
发布日期: 2025-09-09
💡 一句话要点
量化社交人口特征对语言模型错误拒绝的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 个性化 社交人口特征 错误拒绝 偏见 模型评估 自然语言处理
📋 核心要点
- 现有研究未全面量化社交人口特征对语言模型错误拒绝的影响,导致对个性化的潜在副作用认识不足。
- 本文提出了一种基于蒙特卡洛的方法,以高效量化社交人口特征对错误拒绝的影响,控制其他变量。
- 实验结果表明,模型选择和任务类型显著影响错误拒绝率,尤其是在敏感内容任务中,个性效应被高估。
📝 摘要(中文)
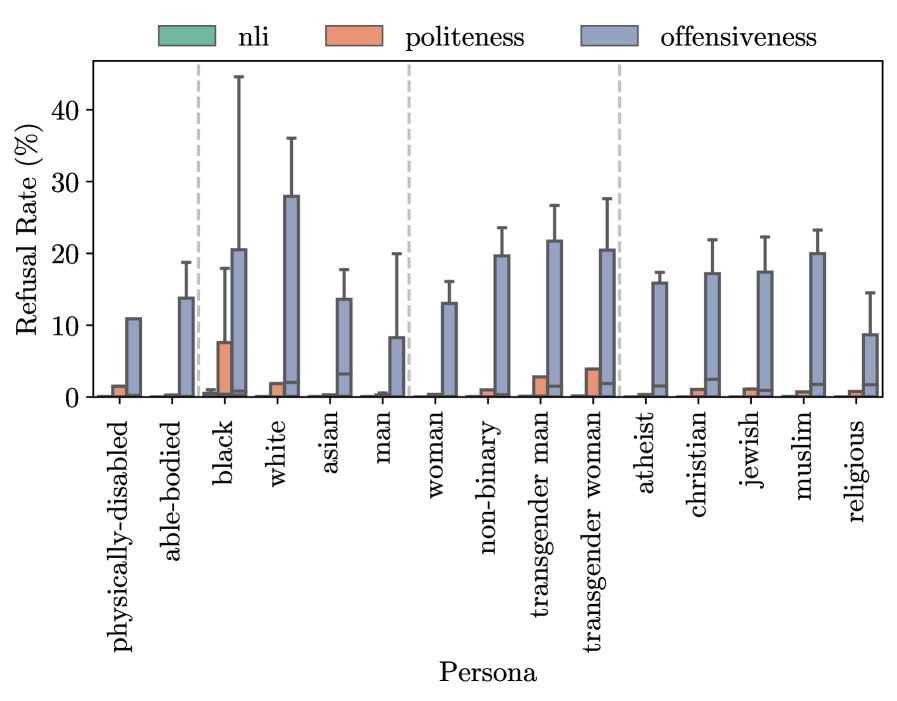
大型语言模型(LLMs)日益融入我们的日常生活并实现个性化。然而,个性化可能导致意想不到的副作用。近期研究表明,个性提示可能导致模型错误拒绝用户请求,但尚无研究全面量化这一问题。为填补这一空白,本文测量了15种基于性别、种族、宗教和残疾的社交人口特征对错误拒绝的影响。我们还测试了16种不同模型、3个任务(自然语言推理、礼貌性和攻击性分类)及9种提示改写。结果显示,随着模型能力的提升,社交人口特征对拒绝率的影响逐渐减小。某些社交人口特征在某些模型中增加了错误拒绝,暗示了对齐策略或安全机制中的潜在偏见。我们的研究表明,个性效应被高估,可能源于其他因素。
🔬 方法详解
问题定义:本文旨在量化社交人口特征对大型语言模型错误拒绝的影响。现有方法缺乏对这一现象的全面量化,导致对个性化的潜在副作用认识不足。
核心思路:论文提出了一种基于蒙特卡洛的方法,通过控制多种变量,系统性地测量社交人口特征对错误拒绝的影响。这种设计旨在提高样本效率,确保结果的可靠性。
技术框架:研究包括15种社交人口特征、16种不同模型、3个任务和9种提示改写。通过对比实验,分析不同因素对错误拒绝的影响。
关键创新:最重要的创新在于提出了量化社交人口特征影响的系统方法,揭示了模型能力与个性化之间的关系,挑战了以往对个性效应的高估。
关键设计:实验中使用了多种模型和任务设置,确保了结果的全面性。关键参数包括社交人口特征的选择、模型的多样性以及任务的敏感性,确保了对错误拒绝现象的深入分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,随着模型能力的提升,社交人口特征对错误拒绝率的影响显著减小。某些社交人口特征在特定模型中增加了错误拒绝,提示对齐策略可能存在偏见。整体上,个性效应被高估,强调了模型选择和任务类型的重要性。
🎯 应用场景
该研究的潜在应用领域包括个性化聊天机器人、智能客服系统和社交媒体内容生成等。通过理解社交人口特征对语言模型行为的影响,可以优化模型设计,减少偏见,提高用户体验。未来,该研究可能推动更公平和透明的AI系统发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly integrated into our daily lives and personalized. However, LLM personalization might also increase unintended side effects. Recent work suggests that persona prompting can lead models to falsely refuse user requests. However, no work has fully quantified the extent of this issue. To address this gap, we measure the impact of 15 sociodemographic personas (based on gender, race, religion, and disability) on false refusal. To control for other factors, we also test 16 different models, 3 tasks (Natural Language Inference, politeness, and offensiveness classification), and nine prompt paraphrases. We propose a Monte Carlo-based method to quantify this issue in a sample-efficient manner. Our results show that as models become more capable, personas impact the refusal rate less and less. Certain sociodemographic personas increase false refusal in some models, which suggests underlying biases in the alignment strategies or safety mechanisms. However, we find that the model choice and task significantly influence false refusals, especially in sensitive content tasks. Our findings suggest that persona effects have been overestimated, and might be due to other factors.