SciGPT: A Large Language Model for Scientific Literature Understanding and Knowledge Discovery
作者: Fengyu She, Nan Wang, Hongfei Wu, Ziyi Wan, Jingmian Wang, Chang Wang
分类: cs.CL
发布日期: 2025-09-09
💡 一句话要点
SciGPT:面向科学文献理解和知识发现的大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 科学文献理解 知识发现 领域自适应 稀疏混合专家 领域蒸馏 ScienceBench
📋 核心要点
- 现有通用大语言模型难以捕捉科学领域的专业术语和方法论严谨性,限制了其在跨学科研究中的应用。
- SciGPT通过低成本的领域蒸馏、稀疏混合专家注意力机制和知识感知适配,提升模型在科学领域的性能。
- 在ScienceBench上的实验结果表明,SciGPT在序列标注、生成和推理等核心科学任务上优于GPT-4o,并展现出良好的鲁棒性。
📝 摘要(中文)
科学文献呈指数级增长,这给研究人员高效地综合知识带来了瓶颈。通用大语言模型(LLMs)在文本处理方面显示出潜力,但它们通常无法捕捉科学领域特有的细微差别(例如,技术术语、方法论的严谨性),并且难以处理复杂的科学任务,限制了它们在跨学科研究中的效用。为了解决这些差距,本文提出了SciGPT,一个为科学文献理解而设计的领域自适应基础模型,以及ScienceBench,一个为评估科学LLMs量身定制的开源基准。
🔬 方法详解
问题定义:当前科研人员面临海量科学文献,难以高效地从中提取和综合知识。通用大语言模型虽然具备一定的文本处理能力,但在理解科学领域的专业术语、方法论以及处理复杂科学任务时表现不足,无法满足跨学科研究的需求。现有方法缺乏针对科学领域的优化,导致模型在科学任务上的性能受限。
核心思路:SciGPT的核心思路是构建一个领域自适应的大语言模型,通过领域蒸馏、稀疏混合专家注意力机制和知识感知适配等技术,使模型能够更好地理解和处理科学文献,从而提升其在科学任务上的性能。这种方法旨在弥合通用大语言模型与科学领域之间的差距,为科研人员提供更有效的工具。
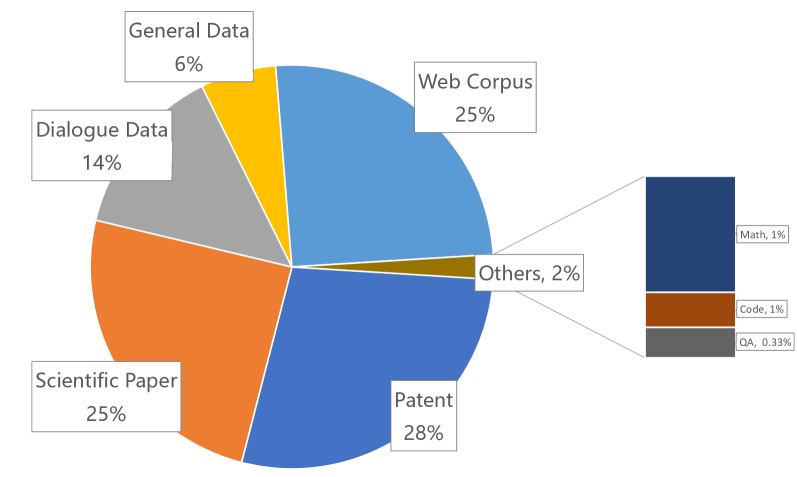
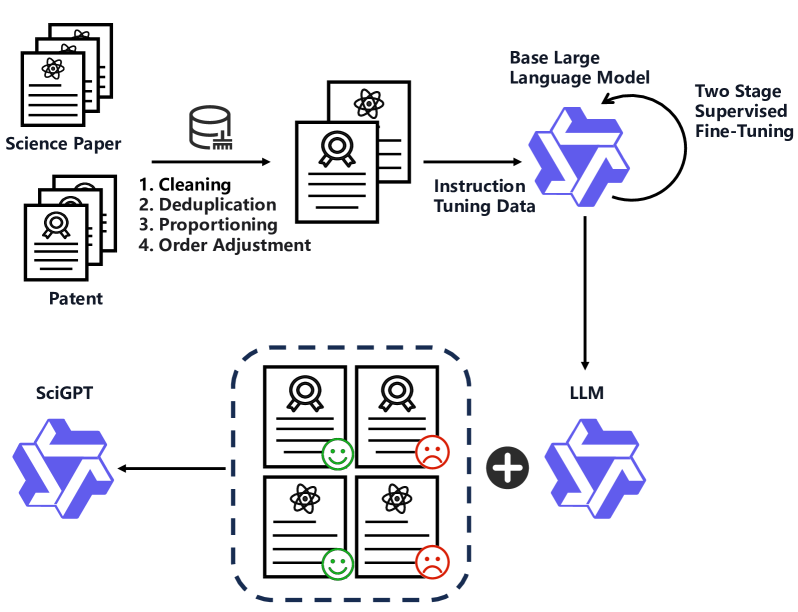
技术框架:SciGPT的整体框架包括以下几个主要阶段:1) 基于Qwen3架构构建基础模型;2) 通过两阶段的低成本领域蒸馏,将通用知识迁移到科学领域;3) 引入稀疏混合专家(SMoE)注意力机制,降低长文档推理的内存消耗;4) 通过知识感知适配,整合领域本体知识,弥合跨学科知识的差距。ScienceBench作为评估基准,用于验证SciGPT在各种科学任务上的性能。
关键创新:SciGPT的关键创新在于以下三个方面:1) 低成本的领域蒸馏,通过两阶段的蒸馏流程,在保证性能的同时降低了训练成本;2) 稀疏混合专家(SMoE)注意力机制,显著降低了处理长文档时的内存消耗,提高了模型的可扩展性;3) 知识感知适配,通过整合领域本体知识,增强了模型对跨学科知识的理解能力。
关键设计:SciGPT的关键设计包括:1) 两阶段蒸馏的具体策略,例如选择哪些数据集进行蒸馏,以及如何设计损失函数;2) SMoE注意力机制的具体实现,例如专家数量、路由策略等;3) 知识感知适配的具体方法,例如如何将领域本体知识融入模型,以及如何设计知识融合的损失函数。论文中可能还包含关于训练数据、优化器、学习率等方面的具体参数设置。
🖼️ 关键图片

📊 实验亮点
SciGPT在ScienceBench基准测试中表现出色,在序列标注、生成和推理等核心科学任务上优于GPT-4o。特别是在处理长文档时,SciGPT的稀疏混合专家注意力机制能够显著降低内存消耗,使其能够处理更长的科学文献。此外,SciGPT在未见过的科学任务中也表现出强大的鲁棒性,证明了其良好的泛化能力。
🎯 应用场景
SciGPT在科学研究领域具有广泛的应用前景,可用于辅助科研人员进行文献综述、知识发现、假设生成和实验设计。通过自动提取和整合科学文献中的信息,SciGPT可以加速科研进程,促进跨学科合作,并推动科学知识的创新和发展。未来,SciGPT有望成为AI辅助科学研究的重要工具。
📄 摘要(原文)
Scientific literature is growing exponentially, creating a critical bottleneck for researchers to efficiently synthesize knowledge. While general-purpose Large Language Models (LLMs) show potential in text processing, they often fail to capture scientific domain-specific nuances (e.g., technical jargon, methodological rigor) and struggle with complex scientific tasks, limiting their utility for interdisciplinary research. To address these gaps, this paper presents SciGPT, a domain-adapted foundation model for scientific literature understanding and ScienceBench, an open source benchmark tailored to evaluate scientific LLMs. Built on the Qwen3 architecture, SciGPT incorporates three key innovations: (1) low-cost domain distillation via a two-stage pipeline to balance performance and efficiency; (2) a Sparse Mixture-of-Experts (SMoE) attention mechanism that cuts memory consumption by 55\% for 32,000-token long-document reasoning; and (3) knowledge-aware adaptation integrating domain ontologies to bridge interdisciplinary knowledge gaps. Experimental results on ScienceBench show that SciGPT outperforms GPT-4o in core scientific tasks including sequence labeling, generation, and inference. It also exhibits strong robustness in unseen scientific tasks, validating its potential to facilitate AI-augmented scientific discovery.