GENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
作者: Tuo Wang, Adithya Kulkarni, Tyler Cody, Peter A. Beling, Yujun Yan, Dawei Zhou
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-09
备注: Accepted by EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
GENUINE:提出图增强多层次不确定性估计方法,提升大语言模型可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性估计 图神经网络 依赖解析 自然语言处理
📋 核心要点
- 现有大语言模型的不确定性估计方法忽略了文本的语义依赖和结构关系,导致可靠性不足。
- GENUINE框架利用依赖解析树和分层图池化,结合监督学习,建模语义和结构信息,提升不确定性估计的准确性。
- 实验结果表明,GENUINE在AUROC和校准误差方面均优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出GENUINE:图增强多层次不确定性估计框架,旨在提高大语言模型(LLMs)的可靠性,尤其是在高风险应用中。现有方法通常忽略语义依赖,仅依赖于token级别的概率度量,无法捕捉生成文本中的结构关系。GENUINE利用依赖解析树和分层图池化来改进不确定性量化,通过引入监督学习,有效建模语义和结构关系,从而提升置信度评估。在多个NLP任务上的实验表明,GENUINE的AUROC比基于语义熵的方法高出29%,校准误差降低超过15%,验证了基于图的不确定性建模的有效性。代码已开源。
🔬 方法详解
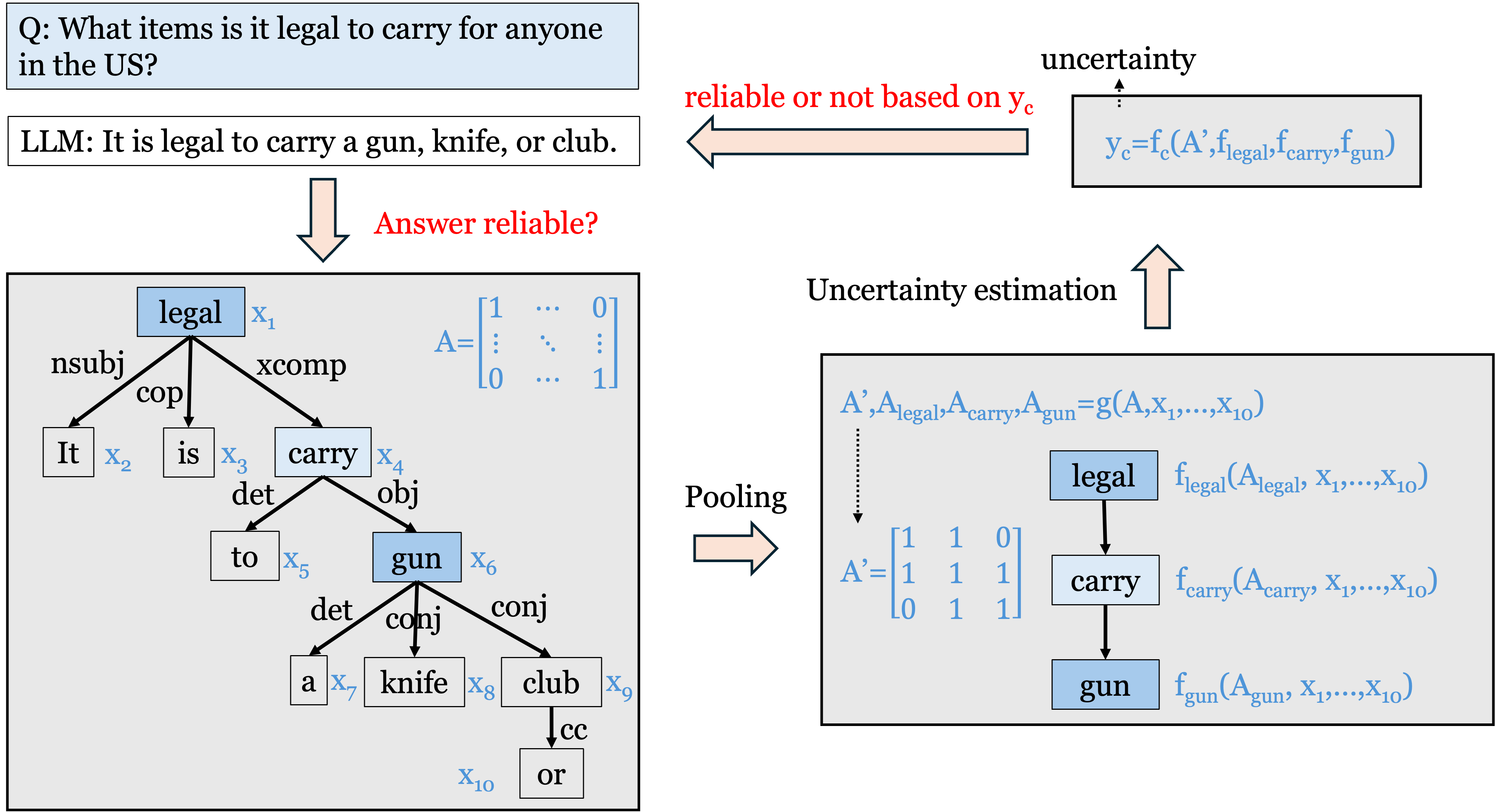
问题定义:现有大语言模型的不确定性估计方法主要依赖于token级别的概率,忽略了句子中token之间的语义依赖关系和结构信息。这种忽略导致模型在评估生成文本的置信度时不够准确,尤其是在需要高可靠性的应用场景下,容易产生误判。现有方法的痛点在于无法有效捕捉文本的整体语义和结构信息,从而影响了不确定性估计的准确性。
核心思路:GENUINE的核心思路是利用图结构来显式地建模文本的语义和结构关系。具体来说,它首先使用依赖解析树来表示句子中词语之间的依赖关系,然后利用图神经网络来学习这些依赖关系,从而得到更准确的文本表示。通过这种方式,GENUINE能够捕捉到token之间的语义依赖,从而更准确地估计生成文本的不确定性。
技术框架:GENUINE框架主要包含以下几个模块:1) 依赖解析模块:使用依赖解析器将文本转换为依赖解析树。2) 图构建模块:将依赖解析树转换为图结构,其中节点表示词语,边表示词语之间的依赖关系。3) 图神经网络模块:使用图神经网络(例如Graph Convolutional Network或Graph Attention Network)来学习图结构中的信息,得到每个节点的表示。4) 不确定性估计模块:基于节点表示,计算生成文本的不确定性。框架采用分层图池化,从token级别到句子级别,逐步聚合信息。
关键创新:GENUINE的关键创新在于将图结构引入到大语言模型的不确定性估计中。与现有方法相比,GENUINE能够显式地建模文本的语义和结构关系,从而更准确地估计生成文本的不确定性。此外,GENUINE还采用了分层图池化,能够从不同粒度上捕捉文本的信息。本质区别在于,现有方法主要关注token级别的概率,而GENUINE则关注句子级别的语义和结构信息。
关键设计:在图神经网络模块中,可以选择不同的图神经网络结构,例如GCN或GAT。损失函数的设计需要考虑不确定性估计的准确性和校准性。可以使用交叉熵损失函数来训练模型,并使用校准误差作为评估指标。依赖解析器的选择也会影响最终的性能,可以选择准确率较高的依赖解析器。分层图池化的具体实现方式也会影响性能,例如可以选择最大池化或平均池化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GENUINE在多个NLP任务上取得了显著的性能提升。具体来说,GENUINE的AUROC比基于语义熵的方法高出29%,校准误差降低超过15%。这些结果表明,GENUINE能够更准确地估计生成文本的不确定性,从而提高大语言模型的可靠性。此外,实验还验证了图结构和分层图池化对于不确定性估计的重要性。
🎯 应用场景
GENUINE框架可应用于各种需要高可靠性的大语言模型应用场景,例如医疗诊断、金融风控、法律咨询等。通过提供更准确的不确定性估计,GENUINE可以帮助用户更好地理解模型的预测结果,并做出更明智的决策。未来,该方法可以进一步扩展到其他自然语言处理任务,例如机器翻译、文本摘要等,提高这些任务的可靠性和可信度。
📄 摘要(原文)
Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.