ALLabel: Three-stage Active Learning for LLM-based Entity Recognition using Demonstration Retrieval
作者: Zihan Chen, Lei Shi, Weize Wu, Qiji Zhou, Yue Zhang
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-09-09
💡 一句话要点
提出ALLabel,一种基于演示检索的三阶段主动学习框架,用于提升LLM在实体识别中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动学习 大型语言模型 实体识别 上下文学习 信息检索
📋 核心要点
- 现有基于微调的实体识别LLM成本高昂,难以在性能和成本之间取得最佳平衡。
- ALLabel通过三阶段主动学习,选择最具信息量和代表性的样本,构建高质量的检索语料库。
- 实验表明,ALLabel仅需标注5%-10%的数据,即可达到与全量标注相当的性能,显著降低标注成本。
📝 摘要(中文)
本文提出ALLabel,一个三阶段框架,旨在为基于大型语言模型(LLM)的实体识别任务选择最具信息量和代表性的样本,用于准备演示数据。该框架利用标注的示例构建ground-truth检索语料库,用于LLM的上下文学习。通过依次采用三种不同的主动学习策略,ALLabel在三个专业领域数据集上,在相同的标注预算下,始终优于所有基线方法。实验结果表明,使用ALLabel选择性地标注数据集中仅5%-10%的样本,即可达到与标注整个数据集的方法相当的性能。进一步的分析和消融研究验证了该提议的有效性和泛化性。
🔬 方法详解
问题定义:论文旨在解决科学领域数据集中的实体识别问题,现有基于微调的LLM方法虽然有效,但微调过程成本高昂,限制了其在资源受限场景下的应用。因此,如何在有限的标注预算下,最大化LLM的实体识别性能,是本文要解决的核心问题。
核心思路:论文的核心思路是利用主动学习策略,选择最具信息量和代表性的样本进行标注,从而构建一个高质量的检索语料库,用于LLM的上下文学习。通过精心设计的三个阶段的主动学习策略,ALLabel能够有效地筛选出对模型性能提升最有帮助的样本。
技术框架:ALLabel框架包含三个主要阶段:1) 不确定性采样(Uncertainty Sampling):选择模型预测最不确定的样本;2) 代表性采样(Representativeness Sampling):选择最具代表性的样本,以覆盖数据集的整体分布;3) 多样性采样(Diversity Sampling):选择与其他已标注样本差异最大的样本,以增加数据的多样性。这三个阶段依次执行,每个阶段都旨在从不同的角度选择信息量最大的样本。最终,选择的样本被标注并用于构建检索语料库,供LLM进行上下文学习。
关键创新:ALLabel的关键创新在于其三阶段主动学习策略的组合,它不仅考虑了模型的不确定性,还考虑了数据的代表性和多样性。这种组合策略能够更有效地选择信息量大的样本,从而提高LLM的实体识别性能。与传统的单阶段主动学习方法相比,ALLabel能够更好地平衡探索和利用,从而在有限的标注预算下取得更好的效果。
关键设计:在不确定性采样阶段,可以使用不同的不确定性度量,例如熵或置信度。在代表性采样阶段,可以使用聚类算法或核心集选择算法来选择最具代表性的样本。在多样性采样阶段,可以使用基于距离的度量或基于覆盖率的度量来选择与其他已标注样本差异最大的样本。具体的参数设置和算法选择可以根据具体的数据集和任务进行调整。论文中具体使用了哪些参数设置和算法选择,需要查阅原文。
🖼️ 关键图片
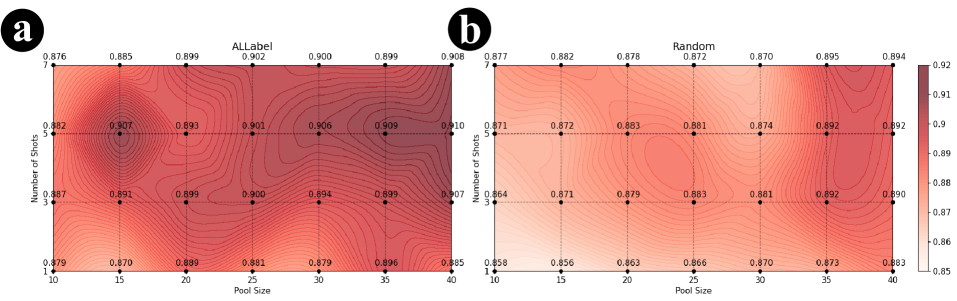
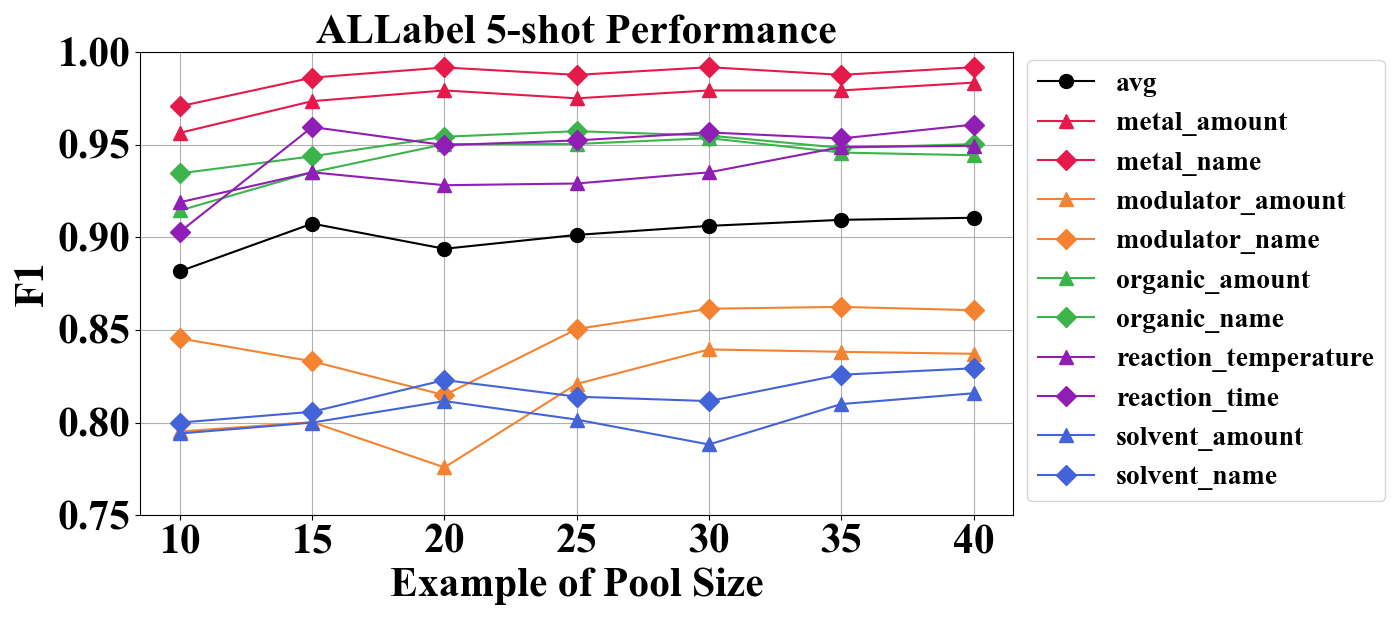
📊 实验亮点
实验结果表明,在三个专业领域数据集上,ALLabel在相同标注预算下始终优于所有基线方法。更重要的是,ALLabel仅需标注5%-10%的数据集,即可达到与标注整个数据集的方法相当的性能,显著降低了标注成本,验证了其高效性和实用性。
🎯 应用场景
ALLabel可应用于化学、材料科学等自然科学领域,用于从科学文献或数据集中自动识别实体,加速科学研究和发现。该方法降低了LLM应用所需的标注成本,使其更易于在资源有限的环境中使用,具有广泛的应用前景。
📄 摘要(原文)
Many contemporary data-driven research efforts in the natural sciences, such as chemistry and materials science, require large-scale, high-performance entity recognition from scientific datasets. Large language models (LLMs) have increasingly been adopted to solve the entity recognition task, with the same trend being observed on all-spectrum NLP tasks. The prevailing entity recognition LLMs rely on fine-tuned technology, yet the fine-tuning process often incurs significant cost. To achieve a best performance-cost trade-off, we propose ALLabel, a three-stage framework designed to select the most informative and representative samples in preparing the demonstrations for LLM modeling. The annotated examples are used to construct a ground-truth retrieval corpus for LLM in-context learning. By sequentially employing three distinct active learning strategies, ALLabel consistently outperforms all baselines under the same annotation budget across three specialized domain datasets. Experimental results also demonstrate that selectively annotating only 5\%-10\% of the dataset with ALLabel can achieve performance comparable to the method annotating the entire dataset. Further analyses and ablation studies verify the effectiveness and generalizability of our proposal.