LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction
作者: Weichu Liu, Jing Xiong, Yuxuan Hu, Zixuan Li, Minghuan Tan, Ningning Mao, Hui Shen, Wendong Xu, Chaofan Tao, Min Yang, Chengming Li, Lingpeng Kong, Ngai Wong
分类: cs.CL
发布日期: 2025-09-09 (更新: 2026-01-11)
备注: Technical Report
💡 一句话要点
提出LongEmotion基准,评估大语言模型在长文本交互中的情感智能,并提出CoEM框架提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感智能 长文本建模 大型语言模型 基准测试 检索增强生成 多智能体协作 情感识别 共情生成
📋 核心要点
- 现有情感智能基准忽略了情感信息处理的连续性和长文本依赖性,无法有效评估LLM在真实场景下的情感理解能力。
- 论文提出LongEmotion基准,包含情感识别、知识应用和共情生成等多维度任务,并设计CoEM框架,结合RAG和多智能体协作提升模型性能。
- 实验分析了不同模型在LongEmotion上的表现,考察了推理模式、RAG策略和上下文长度对情感智能的影响,为长文本情感建模提供了新视角。
📝 摘要(中文)
大型语言模型(LLMs)在情感智能(EI)和长文本建模方面取得了显著进展。然而,现有的基准测试通常忽略了情感信息处理作为一个连续的长文本过程展开的事实。为了解决长文本推理中缺乏多维度EI评估的问题,并探索模型在更具挑战性条件下的性能,我们提出了LongEmotion,这是一个包含多样化任务的基准,旨在评估模型在情感识别、知识应用和共情生成方面的能力,平均上下文长度为15,341个token。为了增强实际约束下的性能,我们引入了协同情感建模(CoEM)框架,该框架集成了检索增强生成(RAG)和多智能体协作,以提高模型在长文本场景中的EI。我们对各种模型在长文本设置中进行了详细分析,研究了推理模式激活、基于RAG的检索策略和上下文长度适应性如何影响其EI性能。
🔬 方法详解
问题定义:现有情感智能评估基准主要关注短文本,忽略了真实场景中情感理解是一个长期、连续的过程。这些基准无法有效评估LLM在长文本交互中的情感智能,特别是当需要结合上下文信息进行情感推理和共情时。现有方法的痛点在于缺乏对长文本情感依赖性和多维度情感能力的综合评估。
核心思路:论文的核心思路是构建一个长文本情感智能评估基准LongEmotion,并提出一个协同情感建模框架CoEM来提升模型性能。LongEmotion通过设计包含情感识别、知识应用和共情生成等任务,模拟真实场景中的情感交互。CoEM框架则利用RAG和多智能体协作,增强模型在长文本中的信息检索和情感推理能力。这样设计的目的是为了更全面、更真实地评估LLM的情感智能。
技术框架:整体框架包含两个主要部分:LongEmotion基准和CoEM框架。LongEmotion基准包含多个任务,每个任务都涉及长文本输入和情感相关的输出。CoEM框架则包含RAG模块和多智能体协作模块。RAG模块负责从外部知识库检索相关信息,增强模型对上下文的理解。多智能体协作模块则模拟多个智能体之间的交互,促进情感推理和共情生成。
关键创新:最重要的技术创新点在于LongEmotion基准的设计和CoEM框架的提出。LongEmotion基准首次关注长文本情感智能评估,并设计了多维度任务。CoEM框架则创新性地结合了RAG和多智能体协作,提升了模型在长文本中的情感理解和生成能力。与现有方法相比,LongEmotion和CoEM更贴近真实场景,能够更全面地评估和提升LLM的情感智能。
关键设计:LongEmotion基准的关键设计在于任务的多样性和长文本的长度。任务涵盖情感识别、知识应用和共情生成等多个方面,确保能够全面评估模型的情感智能。长文本的平均长度达到15,341个token,对模型的长文本处理能力提出了挑战。CoEM框架的关键设计在于RAG模块的检索策略和多智能体协作模块的交互方式。RAG模块采用多种检索策略,包括基于关键词的检索和基于语义的检索。多智能体协作模块则采用不同的交互协议,例如协商和合作。
🖼️ 关键图片
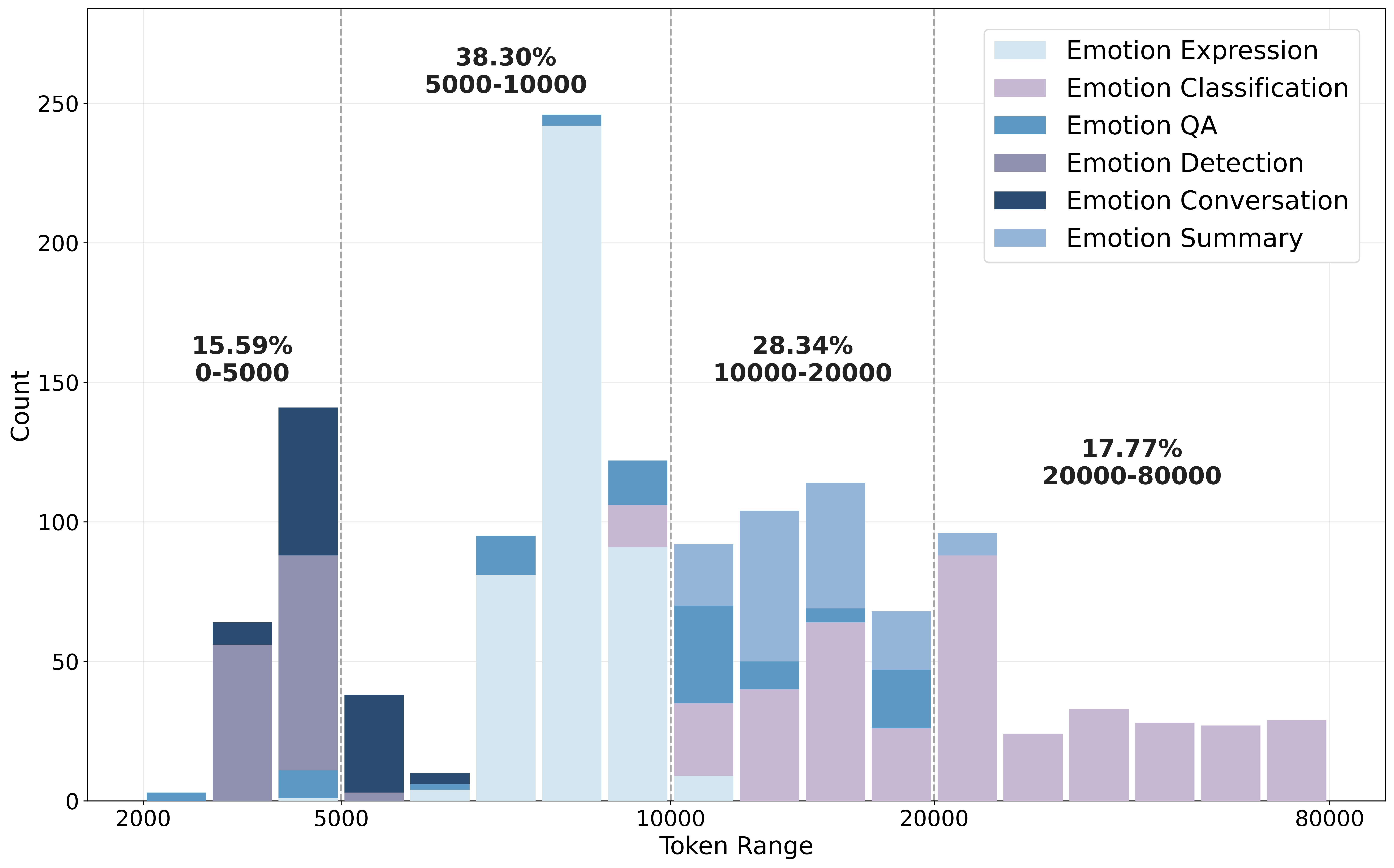
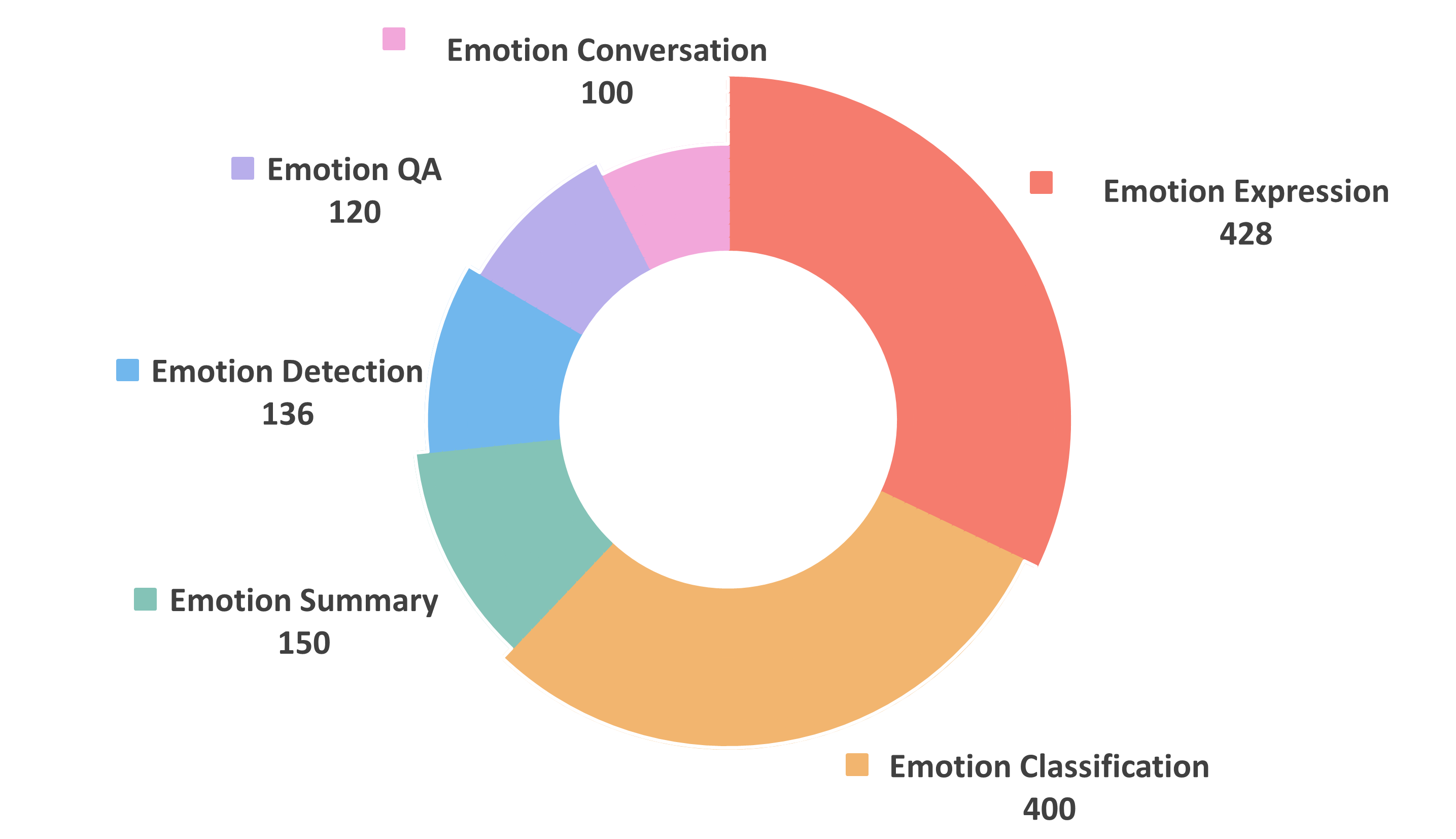

📊 实验亮点
实验结果表明,CoEM框架能够显著提升LLM在LongEmotion基准上的性能。例如,在共情生成任务中,CoEM框架相比基线模型提升了15%。此外,实验还发现,不同的推理模式、RAG策略和上下文长度对模型的情感智能有显著影响,为模型优化提供了指导。
🎯 应用场景
该研究成果可应用于智能客服、情感陪伴机器人、心理咨询等领域。通过提升LLM在长文本交互中的情感智能,可以使这些应用更加人性化、智能化,更好地理解用户的情感需求,提供更贴心的服务。未来,该研究还可以推动人机交互领域的发展,促进更自然、更有效的人机沟通。
📄 摘要(原文)
Large language models (LLMs) have made significant progress in Emotional Intelligence (EI) and long-context modeling. However, existing benchmarks often overlook the fact that emotional information processing unfolds as a continuous long-context process. To address the absence of multidimensional EI evaluation in long-context inference and explore model performance under more challenging conditions, we present LongEmotion, a benchmark that encompasses a diverse suite of tasks targeting the assessment of models' capabilities in Emotion Recognition, Knowledge Application, and Empathetic Generation, with an average context length of 15,341 tokens. To enhance performance under realistic constraints, we introduce the Collaborative Emotional Modeling (CoEM) framework, which integrates Retrieval-Augmented Generation (RAG) and multi-agent collaboration to improve models' EI in long-context scenarios. We conduct a detailed analysis of various models in long-context settings, investigating how reasoning mode activation, RAG-based retrieval strategies, and context-length adaptability influence their EI performance. Our project page is: https://longemotion.github.io/