The Thinking Therapist: Training Large Language Models to Deliver Acceptance and Commitment Therapy using Supervised Fine-Tuning and Odds Ratio Policy Optimization
作者: Talha Tahir
分类: cs.CL, cs.AI
发布日期: 2025-09-08 (更新: 2025-09-20)
💡 一句话要点
利用监督微调和优势比策略优化训练大语言模型进行接受与承诺疗法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 接受与承诺疗法 大型语言模型 策略优化 监督微调 思维链 心理治疗 人机交互
📋 核心要点
- 现有认知行为疗法模型难以有效捕捉接受与承诺疗法(ACT)的核心“过程”要素,导致治疗效果受限。
- 论文提出利用优势比策略优化(ORPO)方法,使小型LLM能够学习ACT的治疗过程,而非简单模仿内容。
- 实验结果表明,ORPO训练的模型在ACT保真度和治疗共情方面显著优于监督微调(SFT)模型和Instruct模型。
📝 摘要(中文)
本研究探讨了后训练方法和显式推理对小型开放权重大型语言模型(LLM)执行接受与承诺疗法(ACT)能力的影响。我们使用Mistral-Large生成的合成ACT记录,通过监督微调(SFT)和优势比策略优化(ORPO)两种方法训练Llama-3.2-3b-Instruct,每种方法都包含和不包含显式的思维链(COT)推理步骤。通过将这四种后训练变体与基础Instruct模型进行比较来评估性能。这些模型在模拟治疗会话中进行基准测试,并通过经过人工评估微调的LLM评估器,在ACT保真度测量(ACT-FM)和治疗师共情量表(TES)上进行定量评估。结果表明,ORPO训练的模型在ACT保真度($χ^2(5) = 185.15, p < .001$)和治疗共情($χ^2(5) = 140.37, p < .001$)方面显著优于SFT和Instruct模型。COT的效果是有条件的,因为它为SFT模型提供了显著的优势,使ACT-FM分数平均提高了2.68分($p < .001$),而对ORPO或instruct调整的变体没有明显的优势。我们认为,ORPO的优越性源于其学习治疗“过程”而不是模仿“内容”的能力,这是ACT的关键方面,而COT仅作为通过模仿训练的模型的必要支架。这项研究表明,偏好对齐的策略优化可以有效地将ACT能力灌输到小型LLM中,并且显式推理的效用高度依赖于底层训练范式。
🔬 方法详解
问题定义:本研究旨在解决如何让小型语言模型(LLM)有效地执行接受与承诺疗法(ACT)的问题。现有方法,如监督微调(SFT),主要侧重于模仿治疗内容,而忽略了ACT中至关重要的治疗“过程”,导致模型在实际应用中表现不佳。
核心思路:论文的核心思路是利用优势比策略优化(ORPO)方法,使LLM能够学习ACT的治疗过程,而不仅仅是模仿内容。ORPO通过优化模型的策略,使其能够更好地理解和执行ACT的原则和技巧。这种方法更注重学习治疗师的决策过程和行为模式,而非简单地复制对话内容。
技术框架:整体框架包括以下几个步骤:1)使用Mistral-Large生成合成ACT治疗记录;2)使用SFT和ORPO两种方法训练Llama-3.2-3b-Instruct模型,每种方法都包含和不包含显式的思维链(COT)推理步骤;3)在模拟治疗会话中对模型进行基准测试;4)使用经过人工评估微调的LLM评估器,在ACT保真度测量(ACT-FM)和治疗师共情量表(TES)上对模型进行定量评估。
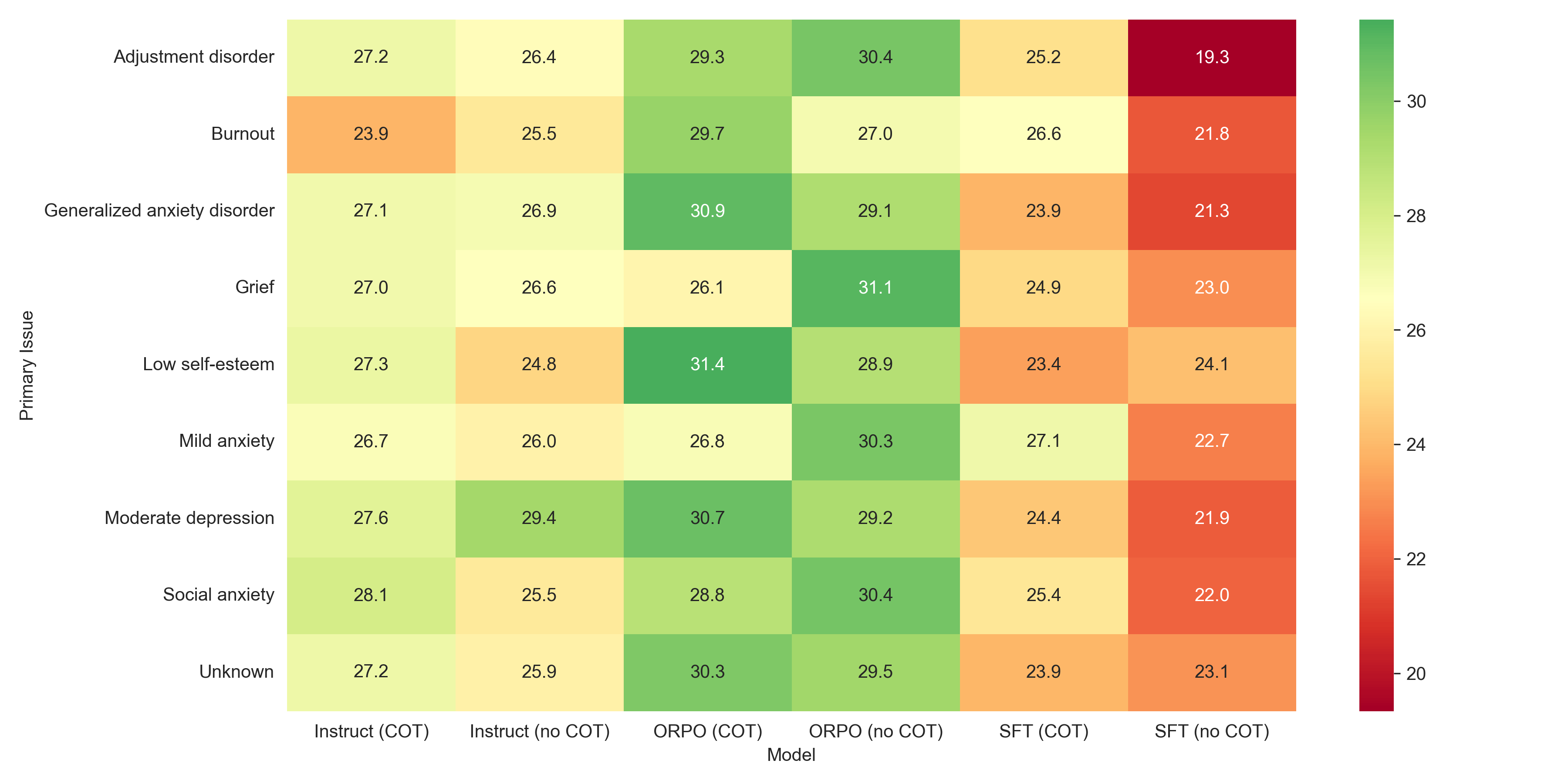
关键创新:最重要的技术创新点在于使用ORPO方法训练LLM执行ACT。与传统的SFT方法相比,ORPO能够更好地学习ACT的治疗过程,从而提高模型的ACT保真度和治疗共情能力。此外,研究还探讨了思维链(COT)推理对不同训练方法的影响,发现COT对SFT模型有显著的提升作用,而对ORPO模型没有明显影响。
关键设计:研究中使用了Llama-3.2-3b-Instruct模型作为基础模型,并使用Mistral-Large生成合成ACT治疗记录。在ORPO训练中,关键在于设计合适的奖励函数,以鼓励模型学习ACT的治疗过程。此外,研究还对SFT和ORPO模型进行了COT训练,以探讨显式推理对模型性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ORPO训练的模型在ACT保真度(ACT-FM)和治疗共情(TES)方面显著优于SFT和Instruct模型($χ^2(5) = 185.15, p < .001$ 和 $χ^2(5) = 140.37, p < .001$)。对于SFT模型,加入思维链(COT)推理步骤后,ACT-FM分数平均提高了2.68分($p < .001$),表明COT可以作为SFT模型的有效辅助手段。
🎯 应用场景
该研究成果可应用于开发智能心理治疗助手,为患者提供初步的心理支持和指导。通过将ACT疗法融入LLM,可以降低心理治疗的成本,提高治疗的可及性,尤其是在心理健康资源匮乏的地区。未来,该技术有望扩展到其他心理治疗方法,为更广泛的人群提供个性化的心理健康服务。
📄 摘要(原文)
Acceptance and Commitment Therapy (ACT) is a third-wave cognitive behavioral therapy with emerging evidence of efficacy in several psychiatric conditions. This study investigates the impact of post-training methodology and explicit reasoning on the ability of a small open-weight large language model (LLM) to deliver ACT. Using synthetic ACT transcripts generated by Mistral-Large, we trained Llama-3.2-3b-Instruct with two distinct approaches, supervised fine-tuning (SFT) and odds ratio policy optimization (ORPO), each with and without an explicit chain-of-thought (COT) reasoning step. Performance was evaluated by comparing these four post-trained variants against the base Instruct model. These models were benchmarked in simulated therapy sessions, with performance quantitatively assessed on the ACT Fidelity Measure (ACT-FM) and the Therapist Empathy Scale (TES) by an LLM judge that had been fine-tuned on human evaluations. Our findings demonstrate that the ORPO-trained models significantly outperformed both their SFT and Instruct counterparts on ACT fidelity ($χ^2(5) = 185.15, p < .001$) and therapeutic empathy ($χ^2(5) = 140.37, p < .001$). The effect of COT was conditional as it provided a significant benefit to SFT models, improving ACT-FM scores by an average of 2.68 points ($p < .001$), while offering no discernible advantage to the superior ORPO or instruct-tuned variants. We posit that the superiority of ORPO stems from its ability to learn the therapeutic
process' over imitatingcontent,' a key aspect of ACT, while COT acts as a necessary scaffold for models trained only via imitation. This study establishes that preference-aligned policy optimization can effectively instill ACT competencies in small LLMs, and that the utility of explicit reasoning is highly dependent on the underlying training paradigm.