Towards EnergyGPT: A Large Language Model Specialized for the Energy Sector
作者: Amal Chebbi, Babajide Kolade
分类: cs.CL
发布日期: 2025-09-08
💡 一句话要点
提出EnergyGPT,一个针对能源领域的专业大型语言模型,通过微调LLaMA 3.1-8B实现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 能源领域 领域专用模型 监督微调 LLaMA 自然语言处理 能源文本挖掘
📋 核心要点
- 通用大型语言模型在能源领域应用受限,缺乏专业知识和领域针对性。
- EnergyGPT通过在能源领域语料库上微调LLaMA 3.1-8B模型,提升领域性能。
- 实验表明,EnergyGPT在能源相关任务上优于基础模型,无需大规模基础设施。
📝 摘要(中文)
大型语言模型在各个领域都展现出了令人印象深刻的能力。然而,其通用性限制了它们在能源等专业领域的有效性,这些领域需要深厚的技术专长和精确的领域知识。本文介绍了EnergyGPT,一个为能源领域量身定制的领域专用语言模型,通过在高质量、精心策划的能源相关文本语料库上使用监督微调来开发LLaMA 3.1-8B模型。我们提出了一个完整的开发流程,包括数据收集和管理、模型微调、基准设计和LLM-judge选择、评估和部署。通过这项工作,我们证明了我们的训练策略能够在不需要大规模基础设施的情况下提高领域相关性和性能。通过使用领域特定的问答基准评估模型的性能,我们的结果表明EnergyGPT在大多数能源相关的语言理解和生成任务中优于基础模型。
🔬 方法详解
问题定义:现有通用大型语言模型在能源领域表现不足,无法有效处理需要专业知识的任务。痛点在于缺乏针对能源领域的训练数据和领域知识,导致模型无法准确理解和生成相关内容。
核心思路:通过监督微调(Supervised Fine-Tuning)的方式,利用高质量的能源领域文本数据,对预训练的LLaMA 3.1-8B模型进行领域知识的注入。这样可以在不从头训练模型的情况下,快速提升模型在能源领域的性能。
技术框架:该研究的整体框架包括以下几个阶段:1) 数据收集与清洗:收集能源领域的文本数据,并进行清洗和整理,构建高质量的训练语料库。2) 模型微调:使用监督微调方法,在LLaMA 3.1-8B模型的基础上,利用构建的语料库进行训练。3) 基准设计与评估:设计领域特定的问答基准,并选择合适的LLM-judge进行评估。4) 模型部署:将训练好的EnergyGPT模型进行部署,以便在实际应用中使用。
关键创新:该研究的关键创新在于构建了一个高质量的能源领域语料库,并利用该语料库对LLaMA 3.1-8B模型进行微调,从而得到了一个领域专用的语言模型EnergyGPT。与从头训练模型相比,这种方法可以显著降低训练成本,并快速提升模型在特定领域的性能。
关键设计:论文中没有详细说明关键参数设置、损失函数和网络结构等技术细节,但可以推断,微调过程可能采用了标准的监督学习方法,例如交叉熵损失函数,并对LLaMA 3.1-8B模型的参数进行更新。具体参数设置可能需要根据实际情况进行调整。
🖼️ 关键图片

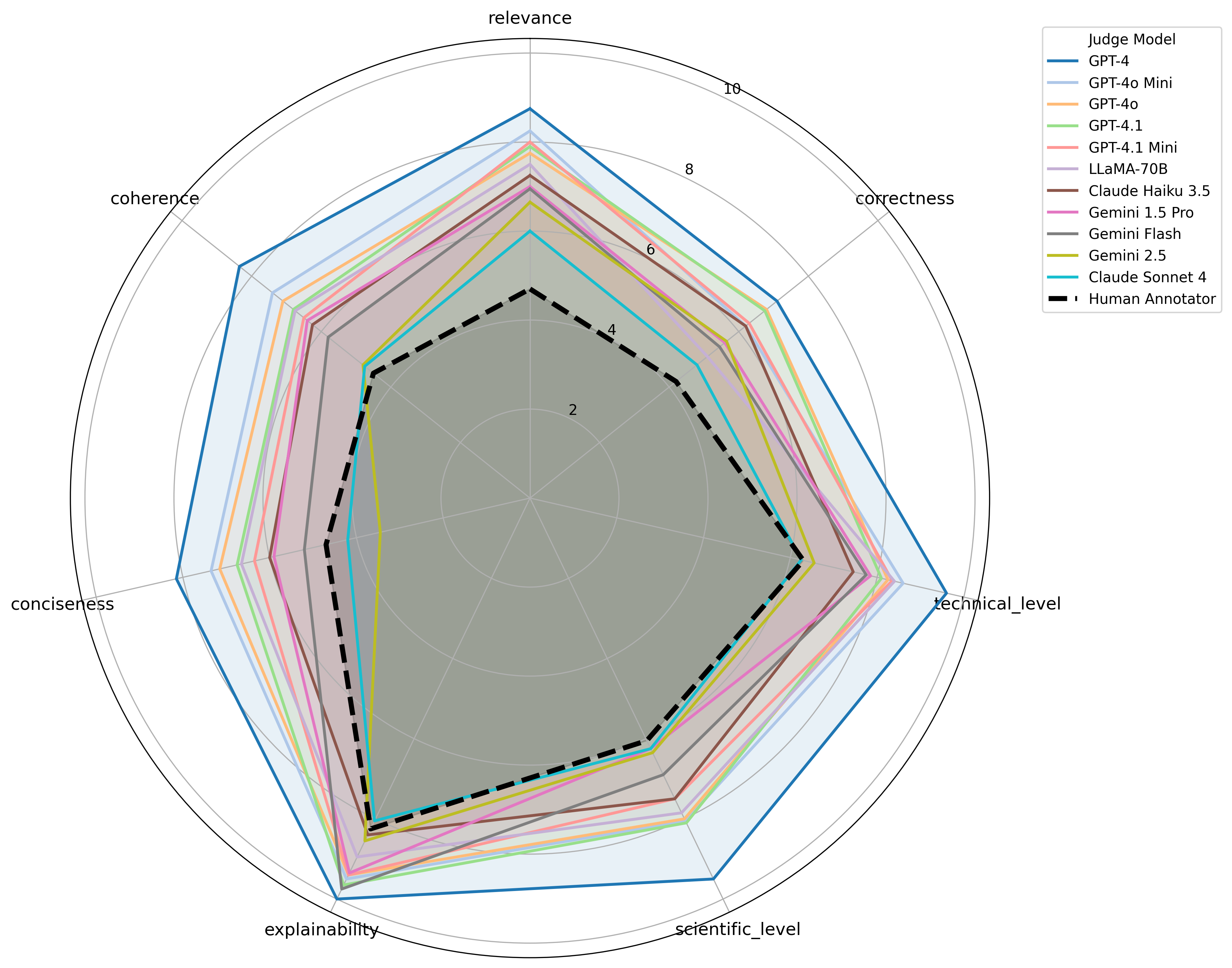
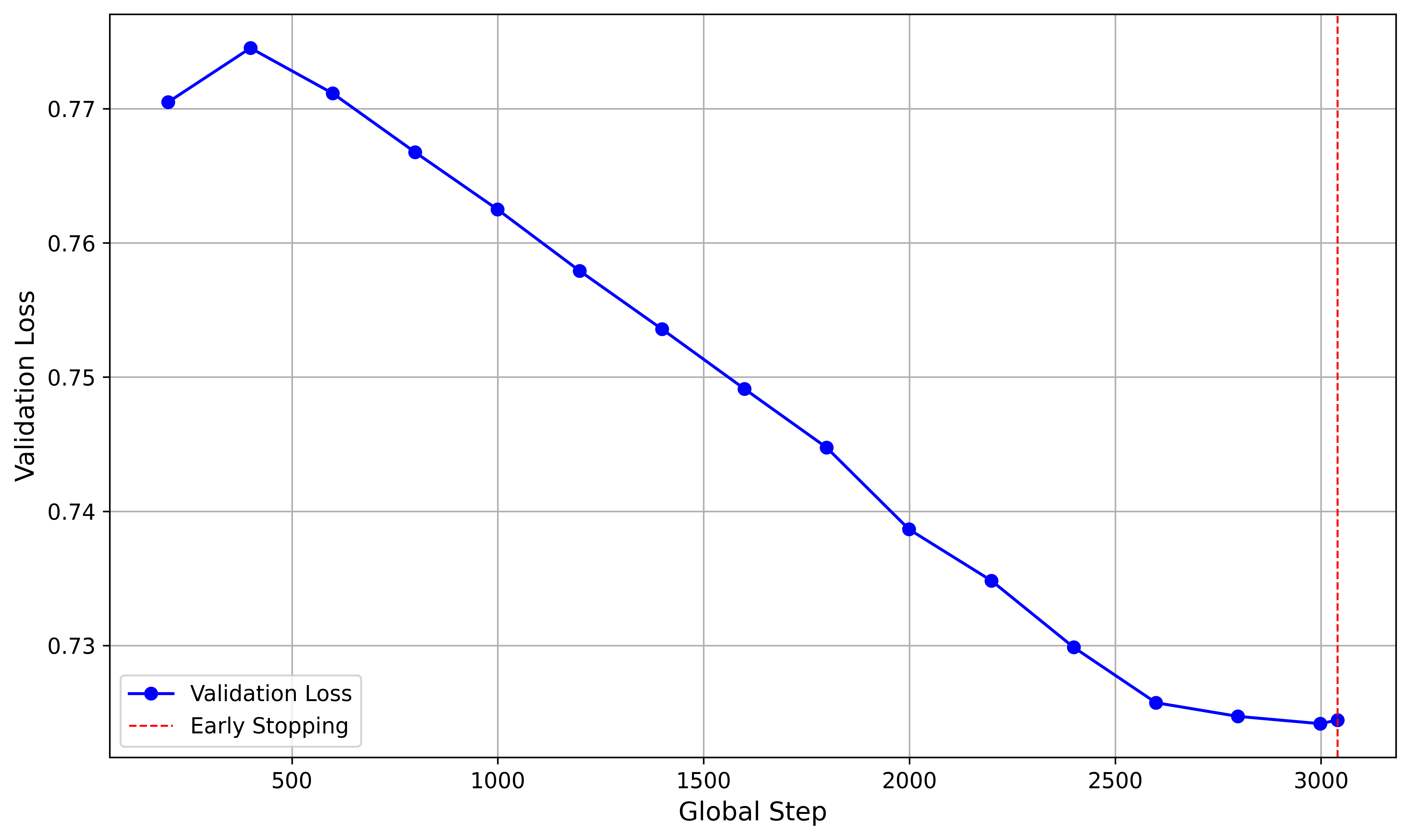
📊 实验亮点
EnergyGPT在领域特定问答基准测试中,性能显著优于基础模型LLaMA 3.1-8B。该研究表明,通过领域特定的数据微调,可以在不依赖大规模计算资源的情况下,有效提升大型语言模型在特定领域的性能。具体性能提升数据未在摘要中给出,需要在论文正文中查找。
🎯 应用场景
EnergyGPT在能源领域具有广泛的应用前景,例如智能客服、能源政策咨询、能源市场分析、智能报告生成等。它可以帮助能源领域的专业人士更高效地获取信息、解决问题,并为能源行业的智能化转型提供技术支持。未来,EnergyGPT可以进一步扩展到其他能源子领域,例如可再生能源、智能电网等。
📄 摘要(原文)
Large Language Models have demonstrated impressive capabilities across various domains. However, their general-purpose nature often limits their effectiveness in specialized fields such as energy, where deep technical expertise and precise domain knowledge are essential. In this paper, we introduce EnergyGPT, a domain-specialized language model tailored for the energy sector, developed by fine-tuning LLaMA 3.1-8B model using Supervised Fine-Tuning on a high-quality, curated corpus of energy-related texts. We present a complete development pipeline, including data collection and curation, model fine-tuning, benchmark design and LLM-judge choice, evaluation and deployment. Through this work, we demonstrate that our training strategy enables improvements in domain relevance and performance without the need for large-scale infrastructure. By evaluating the performance of the model using domain-specific question-answering benchmarks, our results demonstrate that EnergyGPT outperforms the base model in most of the energy-related language understanding and generation tasks.