MedBench-IT: A Comprehensive Benchmark for Evaluating Large Language Models on Italian Medical Entrance Examinations
作者: Ruggero Marino Lazzaroni, Alessandro Angioi, Michelangelo Puliga, Davide Sanna, Roberto Marras
分类: cs.CL
发布日期: 2025-09-08
备注: Accepted as an oral presentation at CLiC-it 2025
💡 一句话要点
MedBench-IT:首个意大利医学入学考试LLM综合评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学教育 意大利语 评估基准 自然语言处理
📋 核心要点
- 现有针对特定领域,尤其是非英语医学领域的LLM评估基准非常稀缺,限制了相关研究和应用。
- MedBench-IT构建了一个包含17410道意大利医学入学考试题目的综合基准,覆盖六个科目和三个难度级别。
- 通过对多种LLM的评估,分析了模型在意大利语医学考试中的表现,并进行了可重复性、偏差和可读性分析。
📝 摘要(中文)
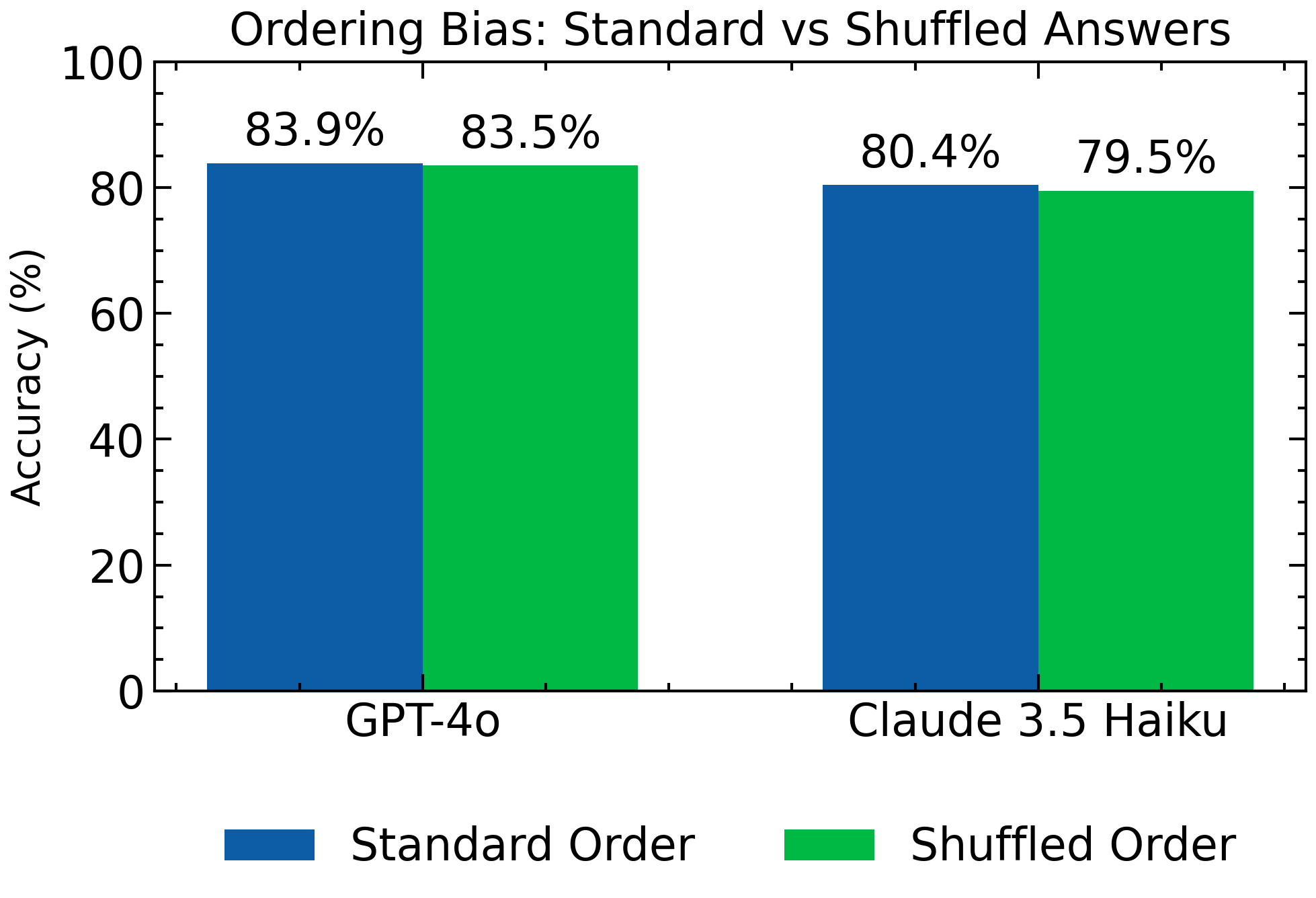
大型语言模型(LLMs)在教育领域展现出日益增长的潜力,但针对特定领域非英语语言的基准仍然稀缺。我们推出了MedBench-IT,这是首个用于评估LLMs在意大利医学大学入学考试表现的综合基准。MedBench-IT来源于领先的备考材料出版商Edizioni Simone,包含17410道由专家编写的选择题,涵盖六个科目(生物、化学、逻辑、普通文化、数学、物理)和三个难度级别。我们评估了包括专有LLMs(GPT-4o、Claude系列)和资源高效的开源替代方案(<30B参数)在内的各种模型,重点关注实际部署能力。除了准确性之外,我们还进行了严格的可重复性测试(88.86%的响应一致性,因科目而异),排序偏差分析(影响极小)和推理提示评估。我们还检查了问题可读性与模型性能之间的相关性,发现了一种统计上显著但较小的负相关关系。MedBench-IT为意大利NLP社区、EdTech开发者和从业者提供了一个关键资源,为这一关键领域提供了对当前能力和标准化评估方法的见解。
🔬 方法详解
问题定义:论文旨在解决缺乏针对意大利语医学入学考试的LLM评估基准的问题。现有方法无法有效评估LLM在该领域的表现,阻碍了LLM在意大利医学教育领域的应用和发展。现有方法的痛点在于缺乏高质量、大规模的意大利语医学考试数据集,以及缺乏针对该领域特点的评估指标和方法。
核心思路:论文的核心思路是构建一个高质量的意大利语医学入学考试数据集,并设计一套全面的评估方法,以评估LLM在该领域的表现。通过对不同LLM的评估和分析,为LLM在该领域的应用提供指导和参考。论文强调了数据集的质量、规模和代表性,以及评估方法的全面性和客观性。
技术框架:MedBench-IT的构建和评估流程主要包括以下几个阶段:1) 数据收集:从Edizioni Simone收集意大利医学入学考试题目,涵盖六个科目和三个难度级别。2) 数据清洗和标注:对收集到的数据进行清洗和标注,确保数据的质量和准确性。3) 模型选择:选择多种LLM进行评估,包括专有LLMs(GPT-4o、Claude系列)和资源高效的开源替代方案(<30B参数)。4) 评估指标:采用准确率作为主要评估指标,并进行可重复性、排序偏差和可读性分析。5) 结果分析:对评估结果进行分析,比较不同LLM的表现,并探讨影响模型性能的因素。
关键创新:论文的关键创新在于构建了首个针对意大利语医学入学考试的LLM评估基准MedBench-IT。该基准包含高质量、大规模的意大利语医学考试题目,并提供了一套全面的评估方法,可以有效评估LLM在该领域的表现。与现有方法相比,MedBench-IT更具针对性和实用性,可以为LLM在意大利医学教育领域的应用提供更有效的指导和参考。
关键设计:在数据集构建方面,论文注重题目的质量和代表性,选择了来自领先备考材料出版商Edizioni Simone的题目,并涵盖了六个科目和三个难度级别。在评估方法方面,论文除了采用准确率作为主要评估指标外,还进行了可重复性、排序偏差和可读性分析,以更全面地评估LLM的表现。在模型选择方面,论文选择了多种LLM进行评估,包括专有LLMs和开源替代方案,以比较不同模型的性能。
🖼️ 关键图片


📊 实验亮点
MedBench-IT基准测试显示,不同LLM在意大利医学入学考试题目上的表现存在差异。实验结果表明,专有LLM(如GPT-4o)通常优于开源模型,但资源高效的开源模型也展现出一定的竞争力。可重复性测试表明,模型的响应一致性较高(88.86%),排序偏差影响极小,问题可读性与模型性能之间存在统计上显著但较小的负相关关系。
🎯 应用场景
MedBench-IT可应用于意大利医学教育领域,帮助学生更好地备考医学入学考试。同时,该基准也可用于评估和改进LLM在医学领域的应用能力,推动医学人工智能的发展。此外,该研究为其他语言和领域的LLM基准构建提供了参考,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Large language models (LLMs) show increasing potential in education, yet benchmarks for non-English languages in specialized domains remain scarce. We introduce MedBench-IT, the first comprehensive benchmark for evaluating LLMs on Italian medical university entrance examinations. Sourced from Edizioni Simone, a leading preparatory materials publisher, MedBench-IT comprises 17,410 expert-written multiple-choice questions across six subjects (Biology, Chemistry, Logic, General Culture, Mathematics, Physics) and three difficulty levels. We evaluated diverse models including proprietary LLMs (GPT-4o, Claude series) and resource-efficient open-source alternatives (<30B parameters) focusing on practical deployability. Beyond accuracy, we conducted rigorous reproducibility tests (88.86% response consistency, varying by subject), ordering bias analysis (minimal impact), and reasoning prompt evaluation. We also examined correlations between question readability and model performance, finding a statistically significant but small inverse relationship. MedBench-IT provides a crucial resource for Italian NLP community, EdTech developers, and practitioners, offering insights into current capabilities and standardized evaluation methodology for this critical domain.