Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
作者: Liang Chen, Xueting Han, Li Shen, Jing Bai, Kam-Fai Wong
分类: cs.CL
发布日期: 2025-09-08 (更新: 2025-10-16)
💡 一句话要点
提出Cooperative SFT and RL方法,解决LLM推理中SFT与RL训练的灾难性遗忘问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 监督微调 推理能力 双层优化
📋 核心要点
- 现有两阶段训练方法(SFT+RL)在LLM推理能力提升中存在灾难性遗忘问题,RL训练会逐渐丢失SFT阶段学到的知识。
- 论文提出一种合作式SFT和RL训练方法,通过双层优化,让SFT能够指导RL的优化过程,从而实现更高效的训练。
- 实验结果表明,该方法在多个推理基准测试中优于现有基线方法,并在效率和效果之间取得了更好的平衡。
📝 摘要(中文)
强化学习(RL)已被证明能有效激励大型语言模型(LLM)的推理能力,但由于其试错性质,效率面临严峻挑战。常见的做法是采用监督微调(SFT)作为RL的预热阶段,但这种解耦的两阶段方法存在灾难性遗忘问题:第二阶段的RL逐渐失去SFT习得的行为,并低效地探索新的模式。本研究提出了一种新的推理模型学习方法,该方法采用双层优化来促进这些训练范式之间更好的合作。通过将SFT目标置于最优RL策略的条件下,我们的方法使SFT能够元学习如何指导RL的优化过程。在训练过程中,下层执行RL更新,同时接受SFT监督,上层显式地最大化合作增益——联合SFT-RL训练相对于单独RL的性能优势。在五个推理基准上的实证评估表明,我们的方法始终优于基线,并在有效性和效率之间实现了更好的平衡。
🔬 方法详解
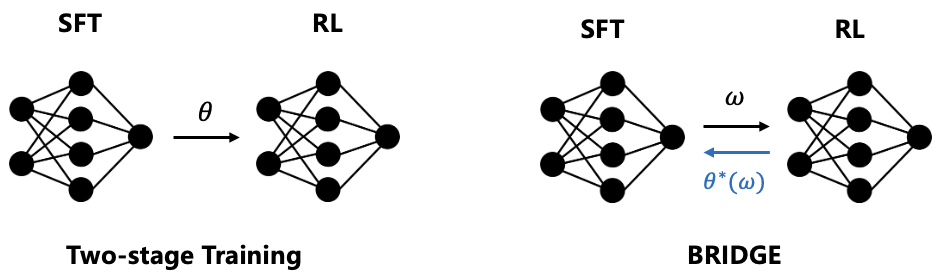
问题定义:现有方法通常采用两阶段训练:先使用监督微调(SFT)预训练LLM,然后使用强化学习(RL)进一步提升推理能力。这种方法的主要痛点在于,RL训练过程中会逐渐遗忘SFT阶段学到的知识,导致训练效率低下,最终性能受限。
核心思路:论文的核心思路是让SFT和RL协同训练,避免灾难性遗忘。具体来说,SFT的目标不再是独立的,而是以RL策略为条件,让SFT学习如何更好地引导RL的优化过程。这样,SFT不仅提供初始知识,还能帮助RL更有效地探索策略空间。
技术框架:该方法采用双层优化框架。下层执行RL更新,同时接受SFT的监督。上层则负责最大化合作增益,即联合SFT-RL训练相对于单独RL训练的性能提升。通过这种方式,SFT和RL相互促进,共同提升LLM的推理能力。整体流程可以概括为:1. 初始化SFT模型和RL环境;2. 在下层,进行RL策略更新和SFT监督;3. 在上层,优化SFT目标,使其更好地引导RL;4. 重复2和3,直到收敛。
关键创新:该方法最重要的创新在于将SFT和RL训练解耦的两阶段模式,转变为协同训练模式。通过双层优化,SFT不再是RL的简单预训练,而是成为RL的指导者,帮助RL更有效地探索策略空间,避免灾难性遗忘。这种协同训练的思想是该方法的核心创新。
关键设计:关键设计包括:1. 将SFT目标函数与RL策略相关联,使得SFT能够学习如何指导RL;2. 使用双层优化框架,分别优化RL策略和SFT目标;3. 定义合作增益,作为上层优化的目标,鼓励SFT和RL之间的协同作用。具体的损失函数设计和参数设置在论文中有详细描述,但此处无法完全展开。
🖼️ 关键图片
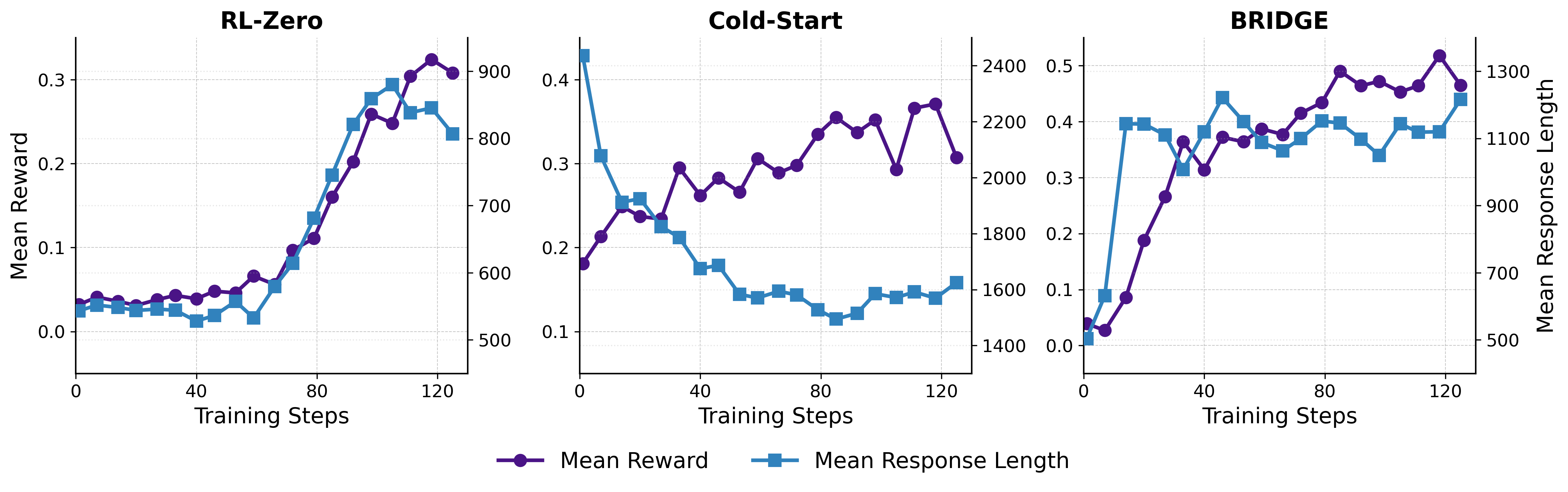
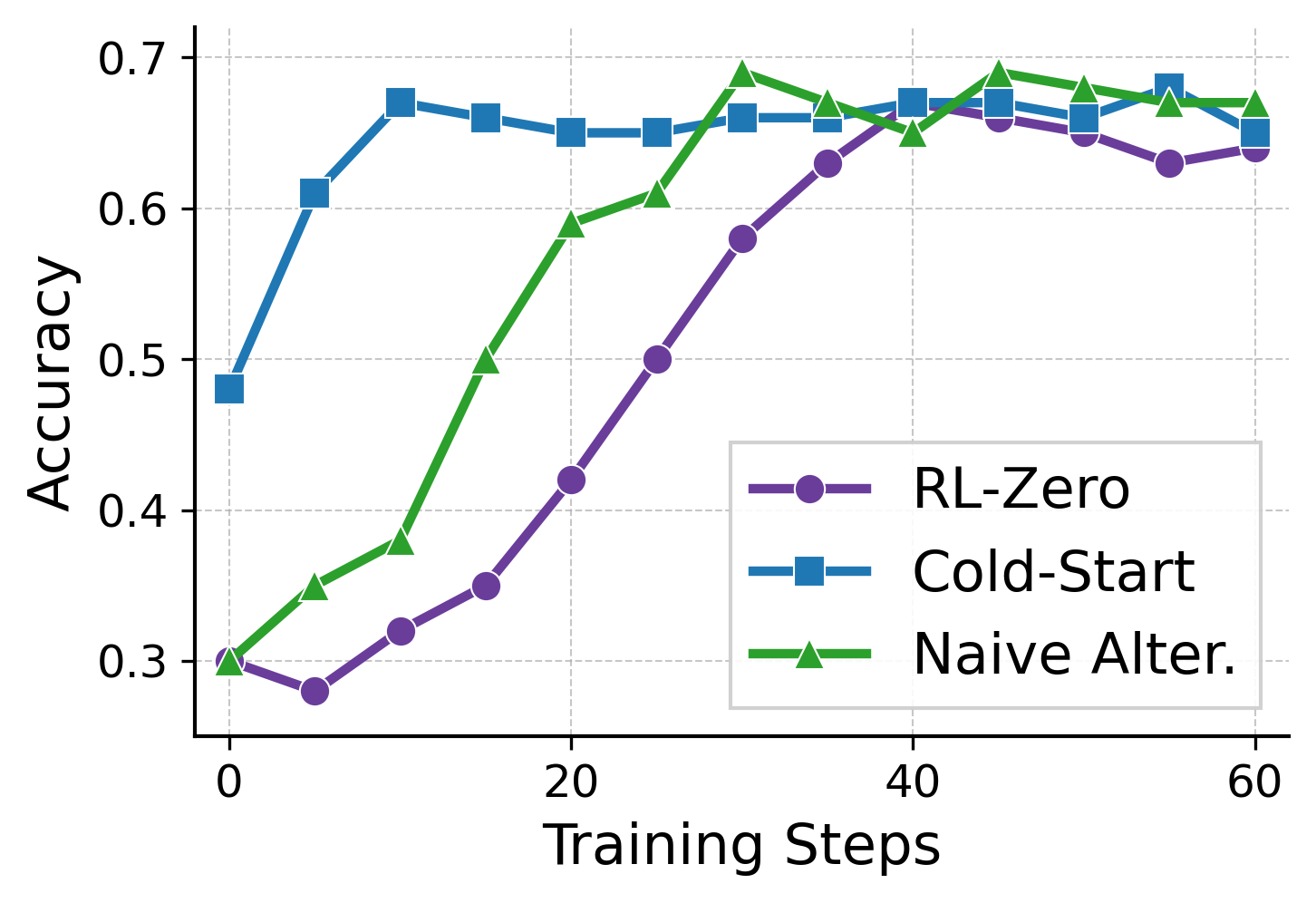
📊 实验亮点
实验结果表明,该方法在五个推理基准测试中均优于现有基线方法,包括GSM8K、MATH等。与传统的两阶段训练方法相比,该方法在相同训练资源下,能够取得更高的推理准确率,并且训练过程更加稳定,有效缓解了灾难性遗忘问题。具体性能提升幅度在不同数据集上有所不同,但整体上都取得了显著的提升。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的大型语言模型应用中,例如智能问答、代码生成、策略规划等。通过提升LLM的推理能力和训练效率,可以降低开发成本,并提升用户体验。该方法也有潜力应用于其他机器学习领域,例如多任务学习和元学习。
📄 摘要(原文)
Reinforcement learning (RL) has proven effective in incentivizing the reasoning abilities of large language models (LLMs), but suffers from severe efficiency challenges due to its trial-and-error nature. While the common practice employs supervised fine-tuning (SFT) as a warm-up stage for RL, this decoupled two-stage approach suffers from catastrophic forgetting: second-stage RL gradually loses SFT-acquired behaviors and inefficiently explores new patterns. This study introduces a novel method for learning reasoning models that employs bilevel optimization to facilitate better cooperation between these training paradigms. By conditioning the SFT objective on the optimal RL policy, our approach enables SFT to meta-learn how to guide RL's optimization process. During training, the lower level performs RL updates while simultaneously receiving SFT supervision, and the upper level explicitly maximizes the cooperative gain-the performance advantage of joint SFT-RL training over RL alone. Empirical evaluations on five reasoning benchmarks demonstrate that our method consistently outperforms baselines and achieves a better balance between effectiveness and efficiency.