Saturation-Driven Dataset Generation for LLM Mathematical Reasoning in the TPTP Ecosystem
作者: Valentin Quesnel, Damien Sileo
分类: cs.CL, cs.AI
发布日期: 2025-09-08
🔗 代码/项目: GITHUB
💡 一句话要点
利用饱和驱动的数据集生成方法,提升LLM在TPTP生态中的数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 自动定理证明 数据集生成 符号推理
📋 核心要点
- 现有LLM在数学推理方面面临挑战,缺乏高质量、逻辑严谨的训练数据是主要瓶颈。
- 论文提出一种基于E-prover饱和能力的符号数据生成方法,避免了LLM的错误和复杂证明助手语法。
- 实验表明,该方法生成的任务能有效诊断LLM在深度结构推理方面的不足,并提供训练数据。
📝 摘要(中文)
高质量、逻辑严谨的数据匮乏是提升大型语言模型(LLM)数学推理能力的关键瓶颈。本文通过将数十年的自动定理证明研究转化为可扩展的数据引擎来应对这一挑战。该框架利用E-prover在庞大的TPTP公理库上的饱和能力来推导出一个大规模、保证有效的定理语料库,而不是依赖于容易出错的LLM或像Lean和Isabelle这样复杂的证明助手语法。该流程简单且有原则:饱和公理,过滤“有趣的”定理,并生成任务。由于没有LLM参与,因此从构造上消除了事实错误。然后,将这种纯粹的符号数据转换为三种难度可控的挑战:蕴涵验证、前提选择和证明重构。对前沿模型的零样本实验揭示了一个明显的弱点:在需要深度结构推理的任务上,性能会崩溃。该框架既提供了衡量这一差距的诊断工具,又提供了可扩展的符号训练数据来源来解决这个问题。代码和数据已公开。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在数学推理方面面临的训练数据不足问题,特别是缺乏高质量、逻辑严谨的数据。现有方法要么依赖容易出错的LLM生成数据,要么依赖于复杂的证明助手(如Lean、Isabelle),这些方法难以保证数据的正确性和可扩展性。
核心思路:论文的核心思路是利用自动定理证明器(ATP)E-prover的饱和能力,在TPTP(Thousands of Problems for Theorem Proving)公理库上进行推理,自动生成大量保证逻辑有效的数学定理。通过这种方式,可以避免LLM生成数据时可能引入的错误,并提供一个可扩展的数据来源。
技术框架:整体框架包括以下几个主要阶段:1) 公理饱和:使用E-prover对TPTP公理库中的公理进行饱和推理,生成新的定理。2) 定理过滤:根据一定的标准(例如定理的复杂度、包含的符号等)筛选出“有趣的”定理。3) 任务生成:将筛选出的定理转化为三种不同类型的数学推理任务:蕴涵验证(entailment verification)、前提选择(premise selection)和证明重构(proof reconstruction)。
关键创新:最重要的技术创新在于利用ATP的饱和能力自动生成高质量的数学推理数据,避免了对LLM或复杂证明助手的依赖。这种方法保证了数据的逻辑有效性,并具有良好的可扩展性。与现有方法相比,该方法能够生成更可靠、更具挑战性的数学推理任务。
关键设计:在公理饱和阶段,需要设置E-prover的参数,例如推理时间限制、使用的推理规则等。在定理过滤阶段,需要设计合适的过滤标准,以选择出既具有挑战性又适合LLM学习的定理。在任务生成阶段,需要将定理转化为具体的任务形式,例如蕴涵验证任务需要将定理和前提转化为自然语言描述,并要求LLM判断定理是否成立。
🖼️ 关键图片
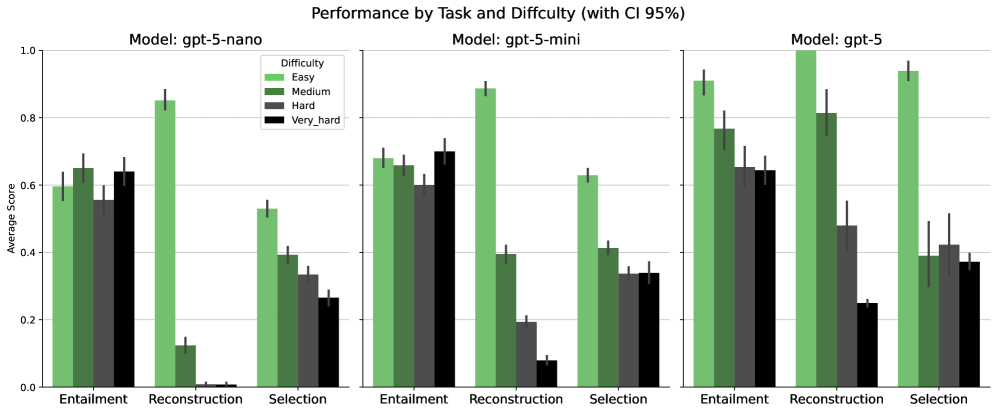


📊 实验亮点
论文通过零样本实验验证了该框架的有效性。实验结果表明,前沿LLM在需要深度结构推理的任务上性能显著下降,表明现有模型在这一方面存在明显不足。该框架提供了一种诊断LLM推理能力的方法,并为生成用于训练LLM的符号数据提供了一种可扩展的解决方案。
🎯 应用场景
该研究成果可应用于提升LLM在数学、逻辑推理等领域的性能。通过使用该方法生成的数据集进行训练,可以提高LLM解决复杂数学问题的能力,例如自动定理证明、数学建模、科学计算等。此外,该方法还可以扩展到其他需要逻辑推理的领域,例如知识图谱推理、程序验证等。
📄 摘要(原文)
The scarcity of high-quality, logically sound data is a critical bottleneck for advancing the mathematical reasoning of Large Language Models (LLMs). Our work confronts this challenge by turning decades of automated theorem proving research into a scalable data engine. Rather than relying on error-prone LLMs or complex proof-assistant syntax like Lean and Isabelle, our framework leverages E-prover's saturation capabilities on the vast TPTP axiom library to derive a massive, guaranteed-valid corpus of theorems. Our pipeline is principled and simple: saturate axioms, filter for "interesting" theorems, and generate tasks. With no LLMs in the loop, we eliminate factual errors by construction. This purely symbolic data is then transformed into three difficulty-controlled challenges: entailment verification, premise selection, and proof reconstruction. Our zero-shot experiments on frontier models reveal a clear weakness: performance collapses on tasks requiring deep, structural reasoning. Our framework provides both the diagnostic tool to measure this gap and a scalable source of symbolic training data to address it. We make the code and data publicly available. https://github.com/sileod/reasoning_core https://hf.co/datasets/reasoning-core/rc1