MSLEF: Multi-Segment LLM Ensemble Finetuning in Recruitment
作者: Omar Walid, Mohamed T. Younes, Khaled Shaban, Mai Hassan, Ali Hamdi
分类: cs.CL
发布日期: 2025-09-07
备注: Accepted in AICCSA 2025
💡 一句话要点
MSLEF:多段LLM集成微调框架,提升招聘自动化中简历解析精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 简历解析 大型语言模型 集成学习 招聘自动化 自然语言处理
📋 核心要点
- 现有简历解析方法难以适应简历格式多样性,导致解析精度不高,影响招聘效率。
- MSLEF框架通过对简历分段,并为每个段落训练专门的LLM,再进行集成,从而提升解析精度和泛化能力。
- 实验结果表明,MSLEF在多个指标上显著优于现有方法,尤其在招聘相似度(RS)上提升高达7%。
📝 摘要(中文)
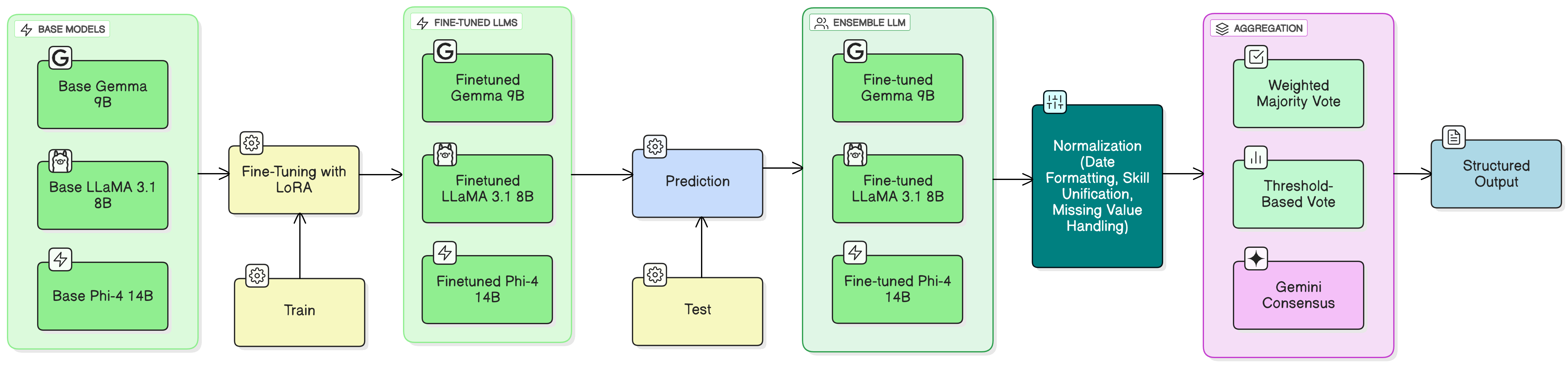
本文提出了一种名为MSLEF的多段集成框架,该框架利用LLM微调来增强招聘自动化中的简历解析。它通过加权投票集成微调后的大型语言模型(LLM),每个模型专门处理简历的特定部分,从而提高准确性。MSLEF基于MLAR,引入了一种段感知架构,该架构利用针对每个简历部分量身定制的特定领域权重,通过适应不同的格式和结构,有效地克服了单模型系统的局限性。该框架集成了Gemini-2.5-Flash LLM作为复杂部分的高级聚合器,并利用了Gemma 9B、LLaMA 3.1 8B和Phi-4 14B。MSLEF在精确匹配(EM)、F1分数、BLEU、ROUGE和招聘相似度(RS)指标方面取得了显著改进,在RS方面优于最佳单模型高达+7%。其段感知设计增强了跨各种简历布局的泛化能力,使其高度适应实际招聘场景,同时确保精确可靠的候选人表示。
🔬 方法详解
问题定义:现有简历解析方法难以有效处理简历格式和结构的多样性,导致解析准确率不高,影响招聘流程的自动化程度。单模型方法难以兼顾简历各个部分的特点,容易在特定字段上出现解析错误。
核心思路:MSLEF的核心思路是将简历划分为多个语义相关的片段,并为每个片段训练一个专门的LLM。通过这种分而治之的策略,每个LLM可以专注于特定类型的信息提取,从而提高整体解析的准确性和鲁棒性。最后,通过加权投票的方式集成各个LLM的输出,以获得最终的解析结果。
技术框架:MSLEF框架包含以下主要模块:1) 简历分段模块:将简历划分为多个语义相关的片段。2) LLM微调模块:针对每个片段,使用不同的LLM(如Gemma 9B、LLaMA 3.1 8B、Phi-4 14B)进行微调,使其擅长解析该片段的信息。3) 集成模块:使用加权投票的方式集成各个LLM的输出,其中权重可以根据片段的重要性或LLM的性能进行调整。Gemini-2.5-Flash LLM被用作高级聚合器,处理复杂片段。
关键创新:MSLEF的关键创新在于其段感知的架构设计。与传统的单模型方法不同,MSLEF能够根据简历的不同部分采用不同的LLM和权重,从而更好地适应简历格式的多样性。此外,使用LLM集成的方式可以进一步提高解析的准确性和鲁棒性。
关键设计:MSLEF的关键设计包括:1) 简历分段策略:如何将简历划分为合适的片段,以最大化每个LLM的性能。2) LLM选择和微调策略:选择哪些LLM以及如何微调这些LLM,以使其擅长解析特定片段的信息。3) 加权投票策略:如何确定每个LLM的权重,以最大化集成后的性能。论文中提到使用了领域特定的权重,但具体的权重设置方法未知。
🖼️ 关键图片
📊 实验亮点
MSLEF在多个简历解析指标上取得了显著提升,尤其是在招聘相似度(RS)指标上,相比最佳单模型提升高达7%。这表明MSLEF能够更准确地理解简历内容,从而更好地匹配候选人和职位。具体性能数据未知,但整体效果优于现有方法。
🎯 应用场景
MSLEF可应用于招聘流程自动化,例如自动提取候选人的技能、经验、教育背景等信息,从而提高招聘效率和质量。该技术还可应用于人力资源管理系统,帮助企业更好地管理和分析员工信息。未来,该技术有望扩展到其他文档解析领域,例如合同解析、财务报表解析等。
📄 摘要(原文)
This paper presents MSLEF, a multi-segment ensemble framework that employs LLM fine-tuning to enhance resume parsing in recruitment automation. It integrates fine-tuned Large Language Models (LLMs) using weighted voting, with each model specializing in a specific resume segment to boost accuracy. Building on MLAR , MSLEF introduces a segment-aware architecture that leverages field-specific weighting tailored to each resume part, effectively overcoming the limitations of single-model systems by adapting to diverse formats and structures. The framework incorporates Gemini-2.5-Flash LLM as a high-level aggregator for complex sections and utilizes Gemma 9B, LLaMA 3.1 8B, and Phi-4 14B. MSLEF achieves significant improvements in Exact Match (EM), F1 score, BLEU, ROUGE, and Recruitment Similarity (RS) metrics, outperforming the best single model by up to +7% in RS. Its segment-aware design enhances generalization across varied resume layouts, making it highly adaptable to real-world hiring scenarios while ensuring precise and reliable candidate representation.