Orthogonal Low-rank Adaptation in Lie Groups for Continual Learning of Large Language Models
作者: Kefan Cao, Shuaicheng Wu
分类: cs.CL
发布日期: 2025-09-07 (更新: 2026-01-23)
备注: 13 pages, 3 figures
💡 一句话要点
OLieRA:基于李群的正交低秩自适应方法,用于大语言模型的持续学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 大型语言模型 李群 低秩自适应 灾难性遗忘
📋 核心要点
- 现有参数正则化方法在持续学习中通过加性更新扭曲了LLM参数的内在几何结构,导致性能下降。
- OLieRA通过李群上的乘性更新保持参数几何结构,同时强制任务子空间的正交性,从而缓解灾难性遗忘。
- OLieRA在Standard CL基准测试上取得了SOTA性能,并且继承了O-LoRA的无重放和无任务ID推理特性。
📝 摘要(中文)
大型语言模型(LLMs)在序列多任务学习中面临灾难性遗忘问题。现有的参数正则化方法(例如,O-LoRA,N-LoRA)通过低秩子空间正交性来减轻干扰,但加性更新会扭曲模型参数的内在几何结构。我们提出了OLieRA,一种基于李群的微调框架,它通过乘性更新来保持参数几何结构,同时强制跨任务子空间的正交性。OLieRA在Standard CL基准测试上实现了最先进的性能,并在大型任务序列下保持了高度竞争力。此外,它还继承了O-LoRA的无重放和无任务ID推理特性,为LLMs中的持续学习建立了一个原则性的范例。
🔬 方法详解
问题定义:大型语言模型在持续学习中面临灾难性遗忘的问题,即在学习新任务时,会忘记之前学习的任务。现有的基于参数正则化的方法,如O-LoRA和N-LoRA,虽然通过低秩子空间正交性来减轻任务间的干扰,但它们采用的加性更新方式会扭曲模型参数的内在几何结构,从而影响模型的性能。
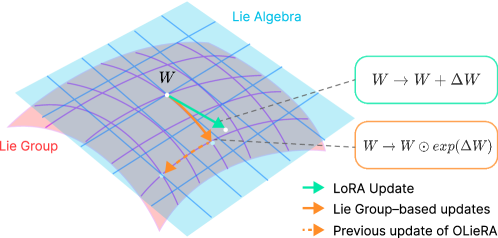
核心思路:OLieRA的核心思路是通过在李群上进行乘性更新来保持模型参数的几何结构。李群是一种连续的群,其元素之间的运算可以保持某些几何性质。通过在李群上进行更新,可以避免加性更新对参数几何结构的破坏。同时,OLieRA仍然强制跨任务子空间的正交性,以减少任务间的干扰。
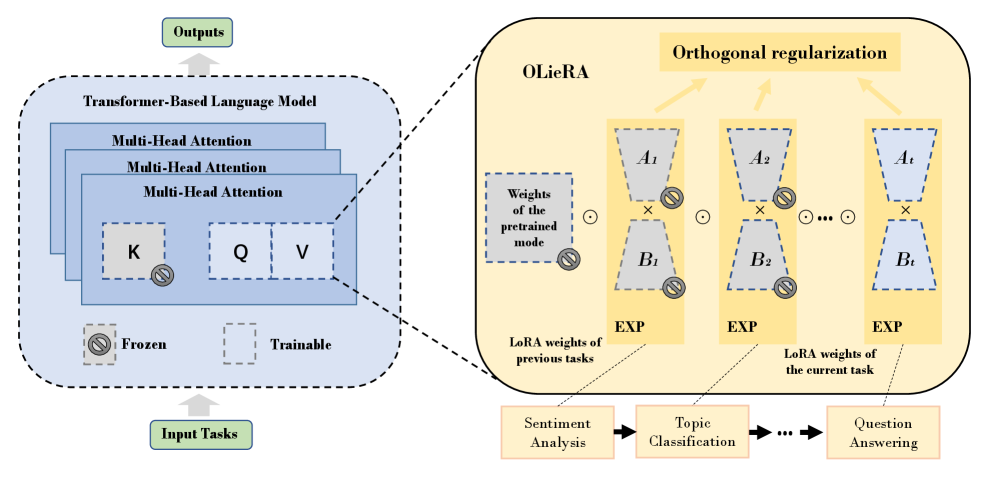
技术框架:OLieRA的整体框架包括以下几个主要步骤:首先,对预训练的LLM进行初始化。然后,对于每个新任务,计算一个低秩更新矩阵,该矩阵位于李群上。接着,将该更新矩阵与模型参数进行乘性更新。最后,通过正则化项强制跨任务子空间的正交性。该框架无需重放旧数据,也无需任务ID,即可实现持续学习。
关键创新:OLieRA的关键创新在于使用李群上的乘性更新来保持模型参数的几何结构。与现有的加性更新方法相比,乘性更新可以更好地保持参数的内在几何性质,从而提高模型的性能。此外,OLieRA还继承了O-LoRA的无重放和无任务ID推理特性,使其更适用于实际应用。
关键设计:OLieRA的关键设计包括:1) 使用指数映射将低秩更新矩阵映射到李群上;2) 使用Frobenius范数来衡量跨任务子空间的正交性;3) 使用Adam优化器来训练模型。具体来说,对于每个任务,OLieRA学习一个低秩矩阵,然后通过指数映射将其映射到李群上。然后,将该李群元素与模型参数进行乘性更新。为了保证任务间的正交性,OLieRA在损失函数中添加了一个正则化项,该正则化项惩罚了不同任务的低秩矩阵之间的相关性。
🖼️ 关键图片
📊 实验亮点
OLieRA在Standard CL基准测试上取得了最先进的性能,表明其在持续学习LLM方面的有效性。具体来说,OLieRA在多个任务序列上都优于现有的方法,并且在大型任务序列下仍然保持了高度竞争力。此外,OLieRA还继承了O-LoRA的无重放和无任务ID推理特性,使其更具实用价值。
🎯 应用场景
OLieRA适用于需要持续学习新任务的大型语言模型,例如,可以应用于智能客服、机器翻译、文本生成等领域。通过持续学习,模型可以不断适应新的用户需求和数据分布,从而提高其性能和泛化能力。该方法无需存储旧数据,也无需任务ID,使其更易于部署和应用。
📄 摘要(原文)
Large language models (LLMs) suffer from catastrophic forgetting in sequential multi-task learning. Existing parameter regularization methods (e.g., O-LoRA, N-LoRA) mitigate interference via low-rank subspace orthogonality, but additive updates distort the intrinsic geometry of model parameters. We propose \textbf{OLieRA}, a Lie group based fine-tuning framework that preserves parameter geometry through multiplicative updates while enforcing orthogonality across task subspaces. OLieRA achieves state-of-the-art performance on the Standard CL benchmark and remains highly competitive under large task sequences. It further inherits the replay-free and task-ID free inference properties of O-LoRA, establishing a principled paradigm for continual learning in LLMs.