Multimodal Reasoning for Science: Technical Report and 1st Place Solution to the ICML 2025 SeePhys Challenge
作者: Hao Liang, Ruitao Wu, Bohan Zeng, Junbo Niu, Wentao Zhang, Bin Dong
分类: cs.CL, cs.CV
发布日期: 2025-09-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于图文描述辅助的多模态推理框架,解决科学问题理解难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 科学问题理解 图像描述 视觉文本融合 AI for Math
📋 核心要点
- 现有方法在多模态推理中表现不佳,尤其是在需要结合视觉信息理解科学问题时,性能显著下降。
- 论文提出一种图文描述辅助的推理框架,通过生成图像的文本描述,弥合视觉和文本模态之间的鸿沟。
- 该方法在SeePhys挑战赛中获得第一名,并在MathVerse基准测试中表现出良好的泛化能力,验证了其有效性。
📝 摘要(中文)
多模态推理是人工智能领域的一项基础性挑战。尽管基于文本的推理取得了显著进展,但即使是像GPT-o3这样的先进模型,在多模态场景中也难以保持强大的性能。为了解决这一差距,我们引入了一种图文描述辅助的推理框架,有效地桥接了视觉和文本模态。我们的方法在ICML 2025 AI for Math Workshop & Challenge 2: SeePhys中获得了第一名,突显了其有效性和鲁棒性。此外,我们在MathVerse几何推理基准上验证了其泛化能力,证明了我们方法的多功能性。我们的代码已在https://github.com/OpenDCAI/SciReasoner上公开。
🔬 方法详解
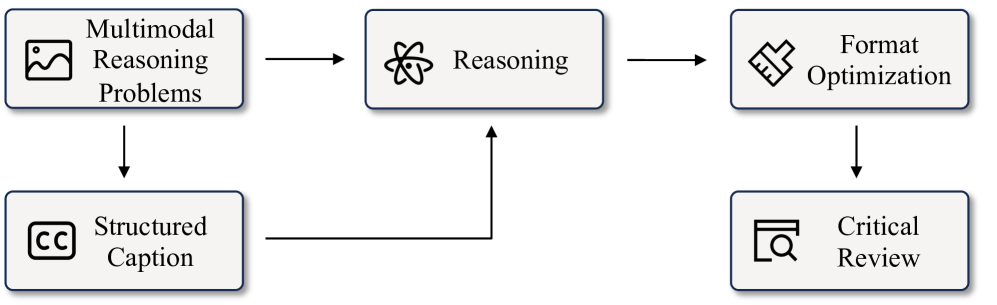
问题定义:论文旨在解决多模态科学问题理解的难题,即如何有效地结合图像和文本信息进行推理。现有方法,如直接使用大型语言模型处理多模态输入,在处理复杂视觉信息时表现不佳,难以准确理解图像中的关键信息,导致推理性能下降。
核心思路:论文的核心思路是利用图像描述(caption)作为桥梁,将视觉信息转化为文本信息,从而更好地利用大型语言模型强大的文本推理能力。通过生成图像的文本描述,将视觉信息显式地表达出来,降低了模型理解视觉信息的难度。
技术框架:整体框架包含图像描述生成模块和文本推理模块。首先,图像描述生成模块负责将输入图像转化为文本描述。然后,将生成的文本描述与原始问题文本拼接在一起,作为文本推理模块的输入。文本推理模块基于大型语言模型,对拼接后的文本进行推理,最终得到答案。
关键创新:最重要的技术创新点在于利用图像描述作为视觉和文本模态之间的桥梁。这种方法避免了直接让大型语言模型处理原始图像信息,而是通过文本描述将视觉信息显式地表达出来,从而提高了模型理解视觉信息的能力。
关键设计:图像描述生成模块可以使用预训练的图像描述模型,也可以针对特定任务进行微调。文本推理模块可以使用各种大型语言模型,如GPT-3或GPT-o3。关键在于如何设计合适的prompt,将图像描述和问题文本有效地结合在一起,以便大型语言模型能够更好地进行推理。损失函数通常采用交叉熵损失,用于优化文本推理模块的参数。
🖼️ 关键图片


📊 实验亮点
该方法在ICML 2025 SeePhys挑战赛中获得第一名,证明了其在多模态科学问题理解方面的有效性。此外,该方法在MathVerse基准测试中也表现出良好的泛化能力,表明其不仅适用于特定数据集,而且具有更广泛的适用性。具体性能数据和对比基线信息未知。
🎯 应用场景
该研究成果可应用于教育领域,例如开发智能辅导系统,帮助学生理解科学概念和解决科学问题。此外,该方法还可以应用于机器人视觉、智能文档处理等领域,提高机器对多模态信息的理解和推理能力,具有广泛的应用前景。
📄 摘要(原文)
Multimodal reasoning remains a fundamental challenge in artificial intelligence. Despite substantial advances in text-based reasoning, even state-of-the-art models such as GPT-o3 struggle to maintain strong performance in multimodal scenarios. To address this gap, we introduce a caption-assisted reasoning framework that effectively bridges visual and textual modalities. Our approach achieved 1st place in the ICML 2025 AI for Math Workshop \& Challenge 2: SeePhys, highlighting its effectiveness and robustness. Furthermore, we validate its generalization on the MathVerse benchmark for geometric reasoning, demonstrating the versatility of our method. Our code is publicly available at https://github.com/OpenDCAI/SciReasoner.