Collaborate, Deliberate, Evaluate: How LLM Alignment Affects Coordinated Multi-Agent Outcomes
作者: Abhijnan Nath, Carine Graff, Nikhil Krishnaswamy
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-07 (更新: 2026-01-21)
备注: This submission is a new version of arXiv:2509.05882v1. with a substantially revised experimental pipeline and new metrics. In particular, collaborator agents are now instantiated independently via separate API calls, rather than generated autoregressively by a single agent. All experimental results are new. Accepted as an extended abstract at AAMAS 2026
💡 一句话要点
研究LLM对齐方法如何影响多智能体协作决策
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体协作 LLM对齐 干预智能体 角色扮演模拟 决策优化
📋 核心要点
- 现有LLM对齐方法在单用户场景下优化,忽略了多方交互中的复杂动态,导致协作效果不佳。
- 提出一种角色扮演模拟方法,通过干预智能体鼓励群体反思,从而改善协作决策。
- 实验表明,对行动修改具有鲁棒性的干预智能体,能显著提升协作任务的正确结果。
📝 摘要(中文)
随着大型语言模型(LLMs)被集成到各种工作流程中,它们越来越被视为人类“合作者”,并需要与其他AI系统协同工作。为了使这些AI合作者能够可靠地与人类或其他AI协调其行动和行为,必须了解和预测它们在多轮交互中的属性和行为。本文研究了不同的对齐方法如何影响LLM智能体作为多轮、多方协作伙伴的有效性。我们通过干预智能体的视角来研究这个问题,这些智能体插入到群体对话中,不是为了提供答案,而是为了鼓励协作群体放慢速度并反思其推理,以进行审慎的决策。常见的对齐技术通常在简化的单用户设置下开发,并假设底层token MDP的最优性。利用修正行动MDP的理论视角,我们展示了它们如何不能解释长时程多方交互的动态。我们提出了一种新颖的角色扮演模拟方法,其中我们根据不同的方法对齐LLM,然后将它们部署在协作任务对话中,以量化干预如何影响群体协作、信念对齐和协调的轨迹。我们的结果表明,对行动修改具有鲁棒性的干预智能体在支持正确的任务结果方面明显优于常见的对齐基线。
🔬 方法详解
问题定义:论文旨在解决LLM在多智能体协作场景下的对齐问题。现有LLM对齐方法通常在单用户环境下进行优化,忽略了多方交互的复杂动态,例如信念漂移、目标冲突等,导致LLM在协作过程中表现不稳定,难以达成一致的决策。这些方法假设底层token MDP的最优性,未能考虑到长时程交互的影响。
核心思路:论文的核心思路是设计一种干预智能体,该智能体能够插入到群体对话中,引导参与者放慢思考速度,反思其推理过程,从而促进更审慎的决策。这种干预旨在纠正信念偏差,促进更好的信息共享和协调,最终提高协作任务的成功率。
技术框架:论文采用角色扮演模拟方法,构建一个多智能体协作环境。首先,使用不同的对齐方法(例如,常见的监督微调、强化学习等)对LLM进行对齐。然后,将这些对齐后的LLM部署到协作任务对话中,并引入干预智能体。干预智能体的目标不是直接提供答案,而是通过提问、总结等方式引导参与者进行更深入的思考。最后,通过量化群体协作的轨迹、信念对齐程度和协调效果,评估不同对齐方法和干预策略的有效性。
关键创新:论文的关键创新在于:1) 提出了使用干预智能体来改善多智能体协作决策的新思路;2) 采用角色扮演模拟方法,能够更真实地模拟多方交互的复杂性;3) 从修正行动MDP的理论视角分析了现有对齐方法的局限性,并提出了对行动修改具有鲁棒性的干预策略。
关键设计:干预智能体的设计是关键。论文可能探索了不同的干预策略,例如,基于规则的干预、基于模型的干预等。关键参数可能包括干预的频率、干预的强度、干预的内容等。损失函数可能涉及到最大化协作任务的成功率、最小化信念偏差、最大化信息共享程度等。具体的网络结构取决于LLM的选择和干预策略的实现方式,可能涉及到注意力机制、记忆网络等。
🖼️ 关键图片

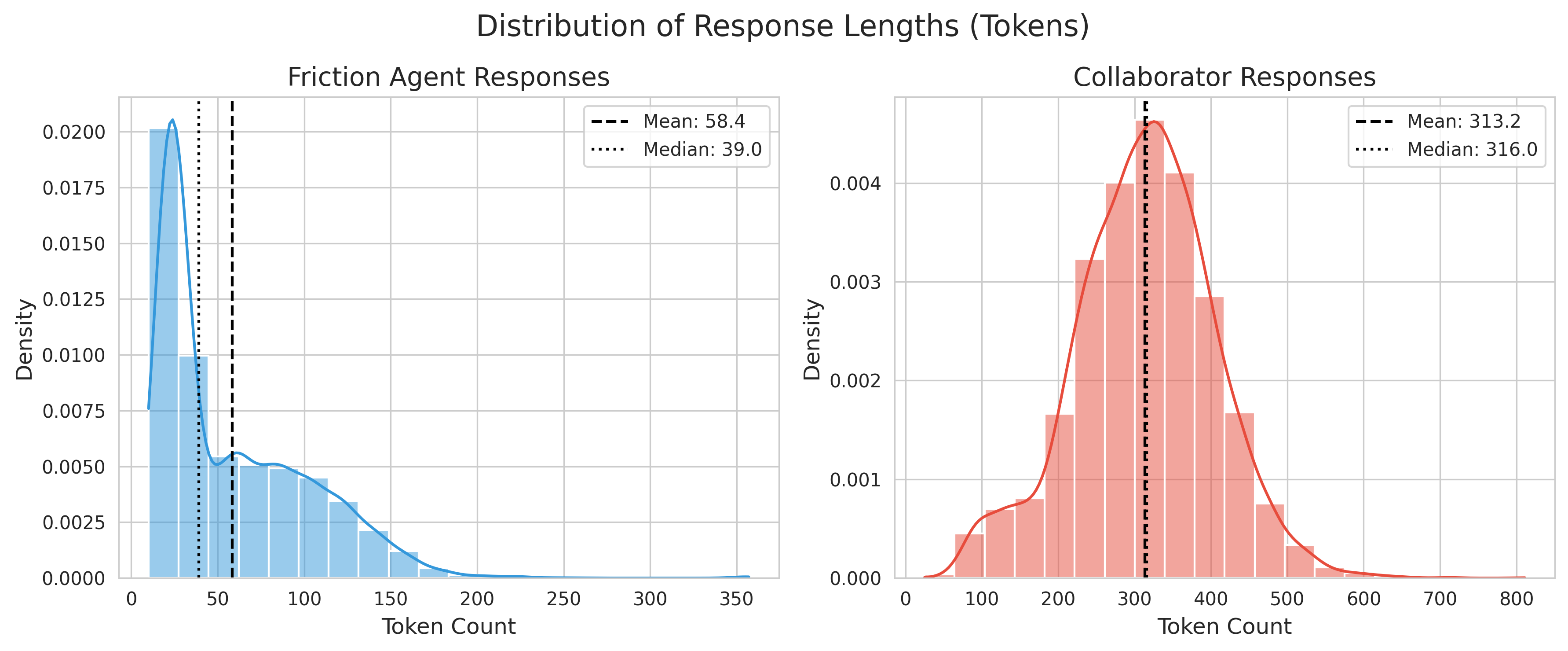
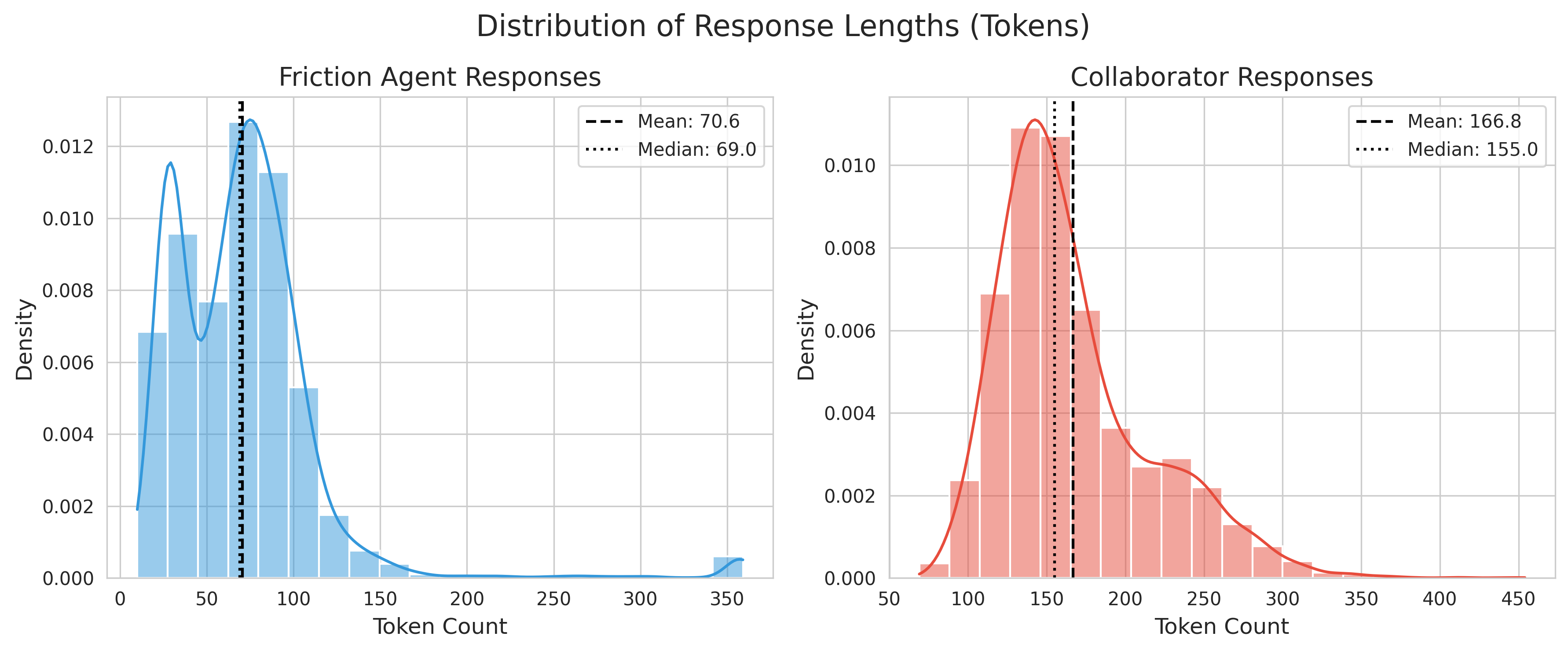
📊 实验亮点
实验结果表明,对行动修改具有鲁棒性的干预智能体在支持正确的任务结果方面明显优于常见的对齐基线。具体的性能数据(例如,任务成功率、信念对齐程度等)和提升幅度需要在论文中查找。该研究验证了干预策略在改善多智能体协作决策方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的场景,例如:智能会议系统、在线教育平台、协同设计工具等。通过引入干预智能体,可以提升团队协作效率,减少决策失误,促进知识共享,从而提高整体工作质量。未来,该研究还可以扩展到人机协作领域,帮助人类更好地与AI系统协同工作。
📄 摘要(原文)
As Large Language Models (LLMs) get integrated into diverse workflows, they are increasingly being regarded as "collaborators" with humans, and required to work in coordination with other AI systems. If such AI collaborators are to reliably coordinate their actions and behaviors with humans or other AIs, their properties and behaviors over multi-turn interactions must be known and predictable. This paper examines how different alignment methods affect LLM agents' effectiveness as partners in multi-turn, multi-party collaborations. We study this question through the lens of intervention agents that insert themselves into group dialogues not to provide answers, but to encourage the collaborative group to slow down and reflect upon their reasoning for deliberative decision-making. Common alignment techniques are typically developed under simplified single-user settings and assume the optimality of the underlying token MDP. Using the theoretical lens of the modified-action MDP, we show how they do not account for the dynamics of long-horizon multi-party interactions. We present a novel roleplay simulation methodology, where we align LLMs according to different methods and then deploy them in collaborative task dialogues to quantify how interventions affect the trajectory of group collaboration, belief alignment, and coordination. Our results show that an intervention agent that is robust to action modification significantly outperforms common alignment baselines in supporting correct task outcomes.