AntiDote: Bi-level Adversarial Training for Tamper-Resistant LLMs
作者: Debdeep Sanyal, Manodeep Ray, Murari Mandal
分类: cs.CL
发布日期: 2025-09-06
备注: 19 pages
💡 一句话要点
AntiDote:面向抗篡改LLM的双层对抗训练方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗训练 安全对齐 权重空间攻击 低秩适应
📋 核心要点
- 现有LLM安全措施难以抵抗恶意微调,攻击者可完全访问模型权重并消除安全防护。
- AntiDote通过双层优化,训练LLM抵抗恶意LoRA权重注入,保持安全对齐。
- 实验表明,AntiDote在保持通用能力的同时,显著提升了LLM的抗攻击鲁棒性。
📝 摘要(中文)
开放权重的大型语言模型(LLM)的发布,在推进可访问研究和防止恶意使用(例如,恶意微调以引出有害内容)之间造成了一种紧张关系。现有的安全措施难以在保持LLM的通用能力的同时,抵抗能够完全访问模型权重和架构的坚定对抗者,这些对抗者可以使用全参数微调来消除现有的安全措施。为了解决这个问题,我们引入了AntiDote,这是一种双层优化程序,用于训练LLM以抵抗这种篡改。AntiDote涉及一个辅助对抗超网络,该网络学习生成恶意的低秩适应(LoRA)权重,这些权重以防御者模型的内部激活为条件。然后,训练防御者LLM的目标是消除这些对抗性权重添加的影响,迫使其保持其安全对齐。我们针对包括越狱提示、潜在空间操纵和直接权重空间攻击在内的52种不同的红队攻击验证了这种方法。与抗篡改和非学习基线相比,AntiDote对抗性攻击的鲁棒性提高了27.4%。至关重要的是,这种鲁棒性是在效用方面以最小的权衡实现的,在包括MMLU、HellaSwag和GSM8K在内的能力基准测试中,性能下降不到0.5%。我们的工作为构建开放权重模型提供了一种实用且计算高效的方法,其中安全性是一种更完整和更具弹性的属性。
🔬 方法详解
问题定义:论文旨在解决开放权重LLM易受恶意篡改的问题。攻击者可以通过微调来绕过安全措施,现有防御方法难以兼顾模型通用能力和安全性。
核心思路:论文的核心思路是采用对抗训练,模拟攻击者对模型进行恶意篡改,并训练模型抵抗这种篡改。通过这种方式,提高模型在实际部署中面对恶意攻击时的鲁棒性。
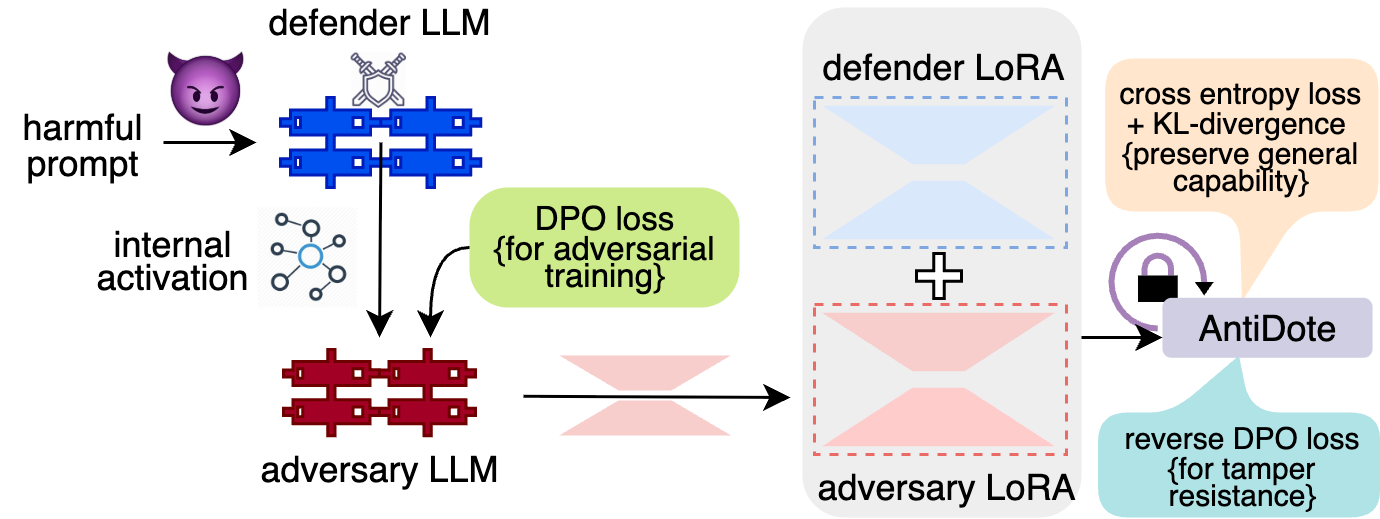
技术框架:AntiDote采用双层优化框架。第一层训练一个对抗超网络,该网络生成恶意的LoRA权重。第二层训练防御者LLM,使其能够抵抗这些恶意权重的注入。整个训练过程交替进行,直到模型达到期望的鲁棒性水平。
关键创新:关键创新在于使用对抗超网络生成针对特定防御模型的恶意LoRA权重。这种方法能够更有效地模拟实际攻击场景,并训练出更具鲁棒性的模型。与传统的对抗训练方法相比,AntiDote更关注权重空间的攻击,而非仅仅是输入空间的扰动。
关键设计:对抗超网络以防御者模型的内部激活为条件,生成LoRA权重。防御者LLM的损失函数包括一个标准任务损失和一个对抗损失,对抗损失衡量模型在受到恶意权重注入后的性能下降程度。通过最小化对抗损失,防御者LLM学会抵抗恶意攻击。
🖼️ 关键图片
📊 实验亮点
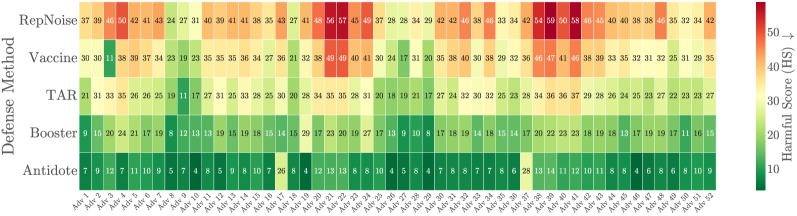
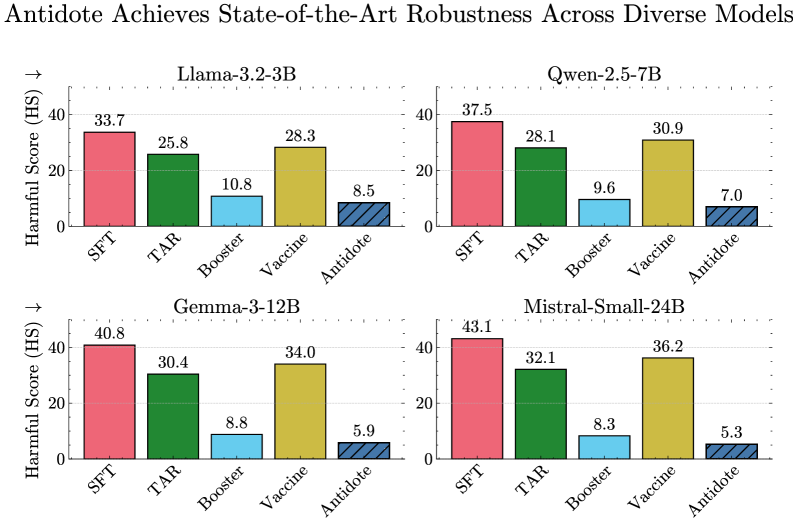
实验结果表明,AntiDote在52种红队攻击下,鲁棒性比现有抗篡改和非学习基线提高了27.4%。同时,在MMLU、HellaSwag和GSM8K等基准测试中,性能下降小于0.5%,表明该方法在提升安全性的同时,对模型通用能力的影响很小。
🎯 应用场景
AntiDote技术可应用于各种开放权重LLM的安全加固,提高模型在实际应用中的安全性,防止被恶意利用传播有害信息。该方法有助于构建更安全、更可靠的AI系统,促进LLM技术的健康发展。
📄 摘要(原文)
The release of open-weight large language models (LLMs) creates a tension between advancing accessible research and preventing misuse, such as malicious fine-tuning to elicit harmful content. Current safety measures struggle to preserve the general capabilities of the LLM while resisting a determined adversary with full access to the model's weights and architecture, who can use full-parameter fine-tuning to erase existing safeguards. To address this, we introduce AntiDote, a bi-level optimization procedure for training LLMs to be resistant to such tampering. AntiDote involves an auxiliary adversary hypernetwork that learns to generate malicious Low-Rank Adaptation (LoRA) weights conditioned on the defender model's internal activations. The defender LLM is then trained with an objective to nullify the effect of these adversarial weight additions, forcing it to maintain its safety alignment. We validate this approach against a diverse suite of 52 red-teaming attacks, including jailbreak prompting, latent space manipulation, and direct weight-space attacks. AntiDote is upto 27.4\% more robust against adversarial attacks compared to both tamper-resistance and unlearning baselines. Crucially, this robustness is achieved with a minimal trade-off in utility, incurring a performance degradation of upto less than 0.5\% across capability benchmarks including MMLU, HellaSwag, and GSM8K. Our work offers a practical and compute efficient methodology for building open-weight models where safety is a more integral and resilient property.