LatinX: Aligning a Multilingual TTS Model with Direct Preference Optimization
作者: Luis Felipe Chary, Miguel Arjona Ramirez
分类: cs.CL
发布日期: 2025-09-06
💡 一句话要点
LatinX:通过直接偏好优化对齐多语种TTS模型,实现跨语种语音克隆
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到语音 多语种TTS 语音克隆 直接偏好优化 跨语种语音合成
📋 核心要点
- 现有跨语种语音克隆模型在保持说话人身份方面存在挑战,尤其是在客观和主观评估上存在差距。
- LatinX通过三阶段训练,包括预训练、监督微调和基于DPO的对齐,旨在提升跨语种语音克隆的说话人相似度。
- 实验表明,LatinX在WER和客观相似度上优于基线模型,且人工评估显示其说话人相似度优于XTTSv2。
📝 摘要(中文)
本文提出LatinX,一种用于级联语音到语音翻译的多语种文本到语音(TTS)模型,该模型能够在不同语言中保留源说话人的身份。LatinX是一个12层解码器Transformer,分三个阶段训练:(i)文本到音频映射的预训练,(ii)用于零样本语音克隆的监督微调,以及(iii)使用基于词错误率(WER)和说话人相似度指标自动标记的配对数据,通过直接偏好优化(DPO)进行对齐。LatinX在英语和罗曼语系上训练,重点是葡萄牙语,通过DPO一致地降低了WER并提高了客观相似度,优于微调的基线模型。人工评估进一步表明,与强大的基线模型(XTTSv2)相比,LatinX具有更强的感知说话人相似度,揭示了客观和主观测量之间的差距。我们提供了跨语言分析,并讨论了平衡的偏好信号和低延迟架构作为未来的工作。
🔬 方法详解
问题定义:论文旨在解决多语种文本到语音(TTS)模型在跨语种语音克隆任务中,说话人身份保持不佳的问题。现有方法在客观指标(如WER)和主观感知(说话人相似度)上存在差距,难以同时优化。
核心思路:论文的核心思路是通过直接偏好优化(DPO)来对齐TTS模型,使其更好地学习说话人身份的跨语种表示。DPO允许模型直接从人类或自动生成的偏好数据中学习,避免了传统强化学习中的复杂奖励函数设计。
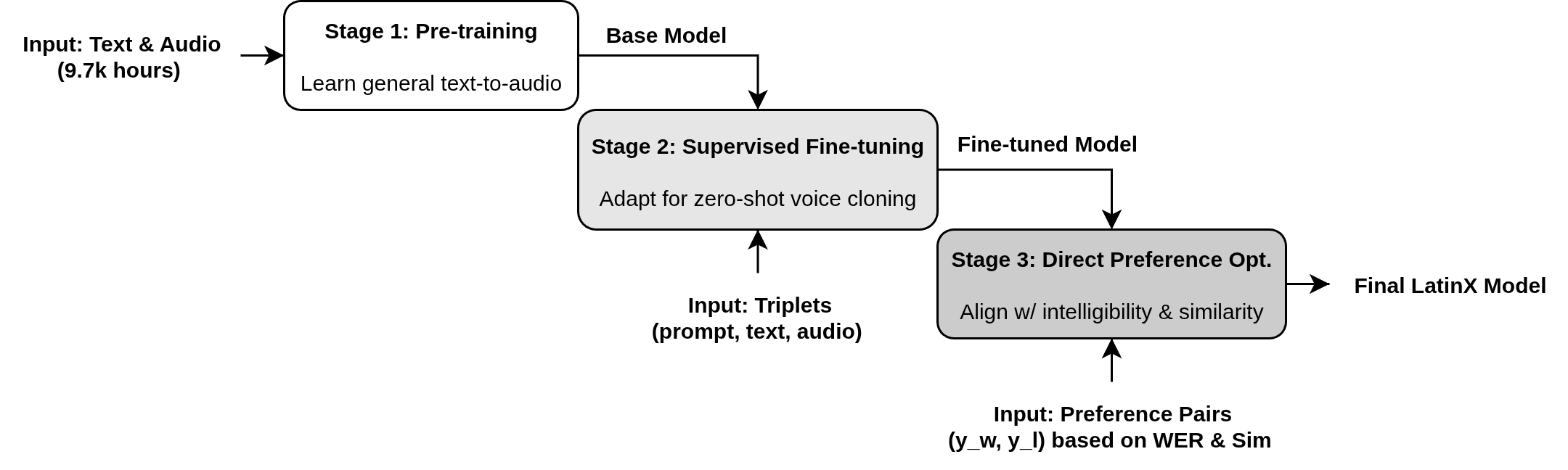
技术框架:LatinX模型是一个12层解码器Transformer,训练分为三个阶段: 1. 预训练:使用大量文本和语音数据进行文本到音频的映射预训练。 2. 监督微调:使用少量带说话人标签的数据进行零样本语音克隆的监督微调。 3. DPO对齐:使用自动标注的偏好数据,通过DPO算法对模型进行对齐,优化说话人相似度。
关键创新:论文的关键创新在于使用DPO算法来优化多语种TTS模型,使其更好地保持说话人身份。与传统的微调方法相比,DPO可以直接从偏好数据中学习,避免了手动设计复杂奖励函数的困难。此外,自动标注偏好数据的方式降低了人工标注成本。
关键设计: * 偏好数据生成:使用WER和说话人相似度指标自动标注偏好数据,用于DPO训练。 * DPO损失函数:使用标准的DPO损失函数,鼓励模型生成更符合偏好的语音。 * 训练数据:使用英语和罗曼语系(重点是葡萄牙语)的数据进行训练,以提高模型的跨语种能力。
🖼️ 关键图片
📊 实验亮点
LatinX模型在客观指标和主观评估上均取得了显著提升。与微调的基线模型相比,LatinX通过DPO一致地降低了WER并提高了客观相似度。更重要的是,人工评估表明,LatinX的说话人相似度优于强大的基线模型XTTSv2,表明DPO在提升感知质量方面具有优势。
🎯 应用场景
该研究成果可应用于多语种语音助手、跨语种内容创作、个性化语音合成等领域。例如,用户可以使用自己的声音在不同语言中生成语音内容,实现无缝的跨语种交流。未来,该技术有望进一步提升人机交互的自然性和个性化程度,促进全球范围内的信息共享和文化交流。
📄 摘要(原文)
We present LatinX, a multilingual text-to-speech (TTS) model for cascaded speech-to-speech translation that preserves the source speaker's identity across languages. LatinX is a 12-layer decoder-only Transformer trained in three stages: (i) pre-training for text-to-audio mapping, (ii) supervised fine-tuning for zero-shot voice cloning, and (iii) alignment with Direct Preference Optimization (DPO) using automatically labeled pairs based on Word Error Rate (WER) and speaker-similarity metrics. Trained on English and Romance languages with emphasis on Portuguese, LatinX with DPO consistently reduces WER and improves objective similarity over the fine-tuned baseline. Human evaluations further indicate stronger perceived speaker similarity than a strong baseline (XTTSv2), revealing gaps between objective and subjective measures. We provide cross-lingual analyses and discuss balanced preference signals and lower-latency architectures as future work.