LM-Searcher: Cross-domain Neural Architecture Search with LLMs via Unified Numerical Encoding
作者: Yuxuan Hu, Jihao Liu, Ke Wang, Jinliang Zhen, Weikang Shi, Manyuan Zhang, Qi Dou, Rui Liu, Aojun Zhou, Hongsheng Li
分类: cs.CL, cs.AI
发布日期: 2025-09-06 (更新: 2025-09-25)
备注: EMNLP 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
LM-Searcher:利用LLM和统一数值编码实现跨领域神经架构搜索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经架构搜索 大型语言模型 跨领域学习 数值编码 指令调优
📋 核心要点
- 现有基于LLM的NAS方法依赖于提示工程和领域特定调整,限制了其在不同任务中的实用性和可扩展性。
- LM-Searcher通过NCode统一数值编码,将NAS问题转化为排序任务,利用LLM在跨领域进行架构搜索。
- 实验表明,LM-Searcher在图像分类、分割和生成等任务上表现出色,验证了其跨领域泛化能力。
📝 摘要(中文)
本文提出了一种名为LM-Searcher的新框架,该框架利用大型语言模型(LLM)进行跨领域神经架构优化,无需进行大量的领域特定调整。该方法的核心是NCode,一种用于神经架构的通用数值字符串表示,它实现了跨领域的架构编码和搜索。此外,本文还将神经架构搜索(NAS)问题重新定义为一个排序任务,通过使用基于剪枝的子空间采样策略生成的指令调优样本,训练LLM从候选池中选择高性能架构。作者构建了一个包含广泛架构-性能对的数据集,以促进鲁棒和可迁移的学习。综合实验表明,LM-Searcher在领域内(例如,用于图像分类的CNN)和领域外(例如,用于分割和生成的LoRA配置)任务中均取得了具有竞争力的性能,为基于LLM的灵活且可泛化的架构搜索建立了一种新的范例。
🔬 方法详解
问题定义:现有的基于LLM的神经架构搜索方法通常需要大量的prompt工程和领域特定的调优,这限制了它们在不同任务和领域中的泛化能力。因此,如何设计一种通用的、可跨领域应用的基于LLM的神经架构搜索方法是一个关键问题。
核心思路:LM-Searcher的核心思路是将神经架构搜索问题转化为一个排序问题,并利用大型语言模型(LLM)来学习架构的性能排序。通过设计一种通用的数值编码方式(NCode)来表示不同的神经架构,使得LLM可以理解和比较来自不同领域的架构。此外,通过指令调优的方式,训练LLM从候选架构池中选择高性能的架构。
技术框架:LM-Searcher的整体框架包括以下几个主要模块:1) NCode编码器:将不同领域的神经架构(例如CNN、LoRA配置)编码为统一的数值字符串表示。2) 子空间采样器:基于剪枝策略,从架构空间中采样候选架构。3) 指令调优数据集构建器:构建包含架构-性能对的指令调优数据集,用于训练LLM。4) LLM排序器:使用训练好的LLM对候选架构进行排序,选择高性能的架构。
关键创新:LM-Searcher的关键创新在于以下几个方面:1) NCode通用数值编码:提出了一种通用的数值字符串表示方法,可以对不同领域的神经架构进行编码,使得LLM可以跨领域地理解和比较架构。2) 基于排序的NAS:将NAS问题转化为一个排序问题,使得LLM可以直接学习架构的性能排序,而不需要进行复杂的架构生成。3) 基于剪枝的子空间采样:提出了一种基于剪枝的子空间采样策略,可以有效地探索架构空间,并选择有潜力的候选架构。
关键设计:NCode编码的关键设计在于如何将不同类型的架构参数(例如卷积核大小、通道数、LoRA秩)映射到数值字符串。指令调优数据集的构建采用了对比学习的思想,即对于每个架构,选择一个性能更好的架构和一个性能更差的架构作为正负样本。LLM排序器使用了标准的Transformer架构,并采用了交叉熵损失函数进行训练。
🖼️ 关键图片
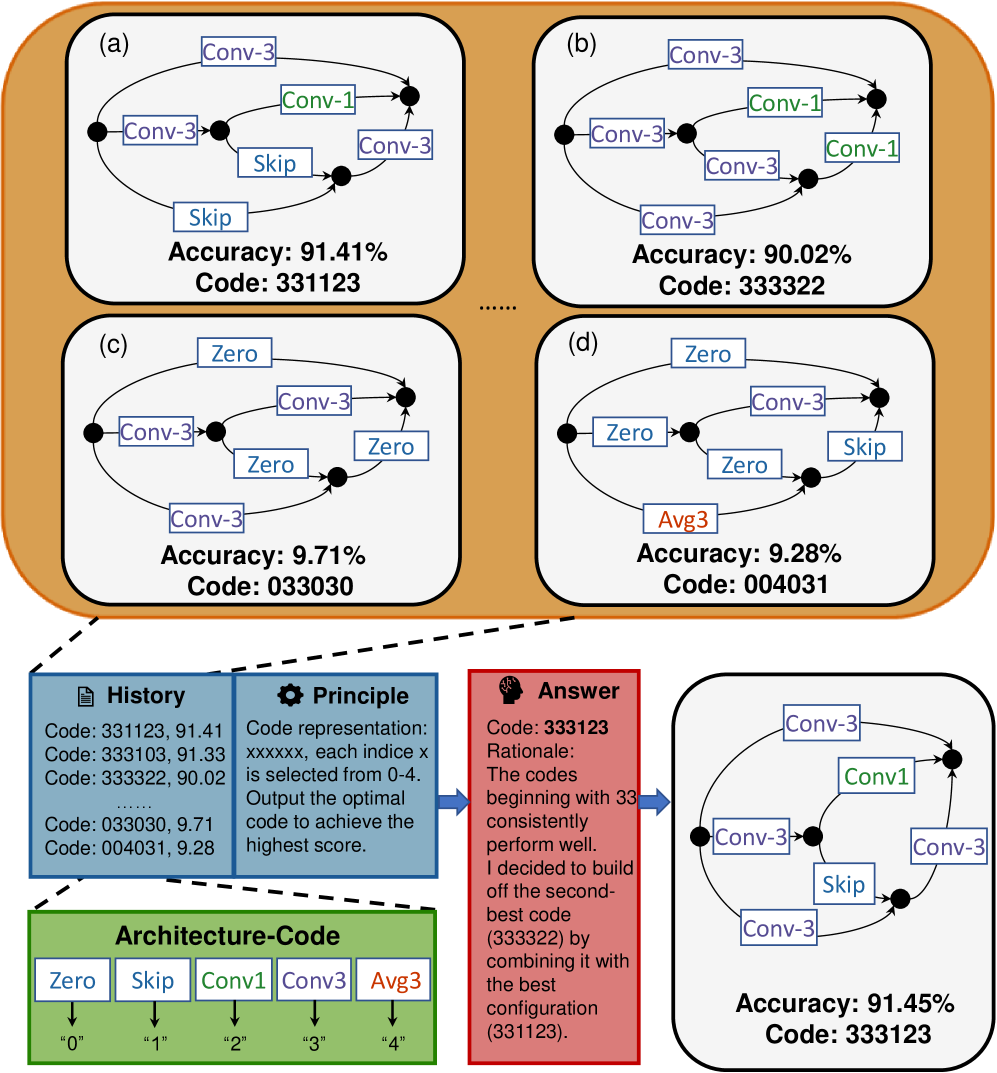
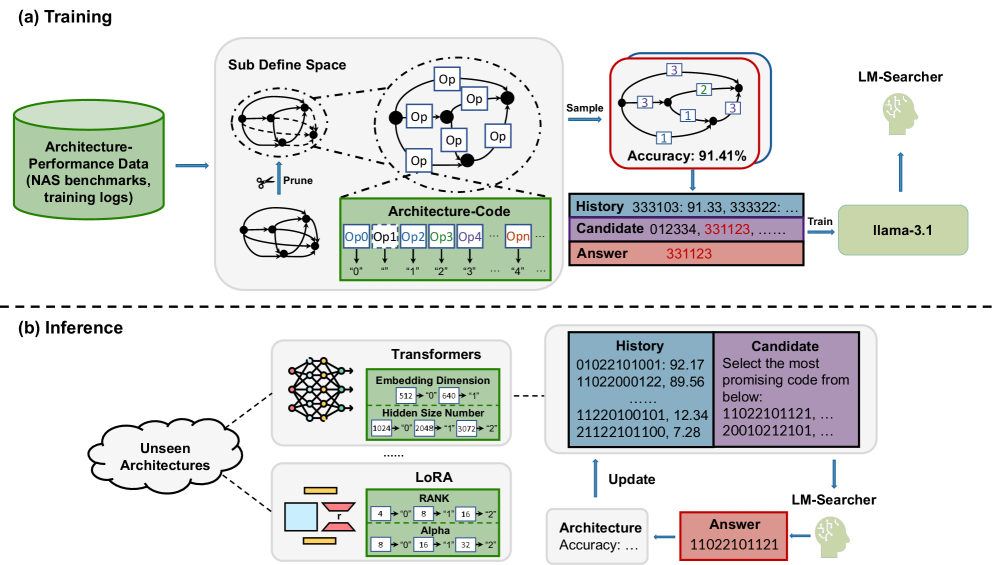
📊 实验亮点
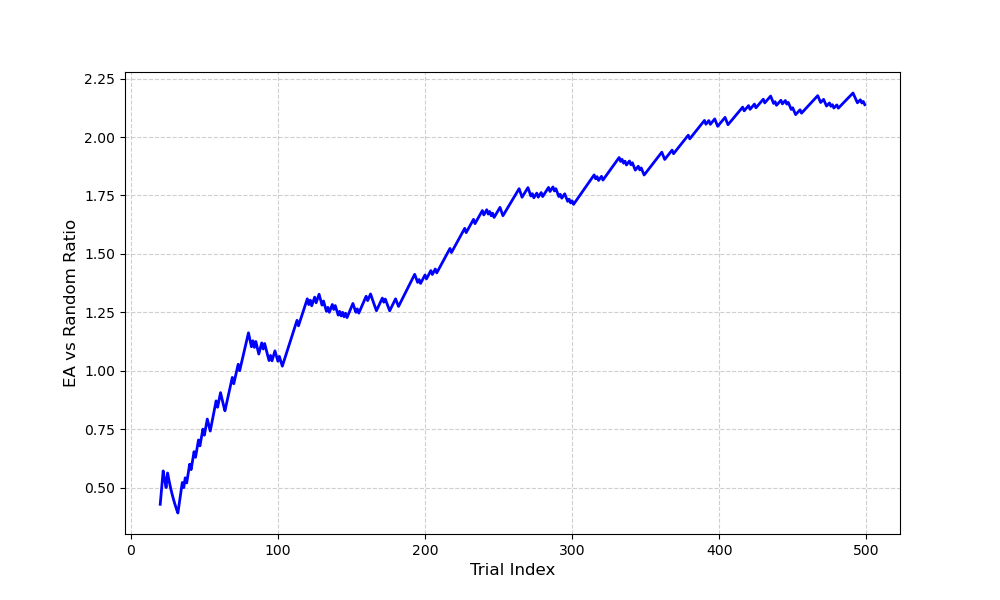
实验结果表明,LM-Searcher在图像分类(CNN架构)和图像分割/生成(LoRA配置)等任务上均取得了具有竞争力的性能。例如,在图像分类任务中,LM-Searcher可以找到与手工设计的SOTA模型性能相当的架构。在图像分割和生成任务中,LM-Searcher可以找到比随机搜索和进化算法更好的LoRA配置,验证了其跨领域泛化能力。
🎯 应用场景
LM-Searcher具有广泛的应用前景,可以应用于图像分类、目标检测、语义分割、图像生成等多种计算机视觉任务,以及自然语言处理、语音识别等其他领域。该方法可以帮助研究人员和工程师快速找到高性能的神经架构,从而加速AI模型的开发和部署。此外,LM-Searcher还可以用于自动化机器学习(AutoML)平台,提供更加灵活和高效的架构搜索能力。
📄 摘要(原文)
Recent progress in Large Language Models (LLMs) has opened new avenues for solving complex optimization problems, including Neural Architecture Search (NAS). However, existing LLM-driven NAS approaches rely heavily on prompt engineering and domain-specific tuning, limiting their practicality and scalability across diverse tasks. In this work, we propose LM-Searcher, a novel framework that leverages LLMs for cross-domain neural architecture optimization without the need for extensive domain-specific adaptation. Central to our approach is NCode, a universal numerical string representation for neural architectures, which enables cross-domain architecture encoding and search. We also reformulate the NAS problem as a ranking task, training LLMs to select high-performing architectures from candidate pools using instruction-tuning samples derived from a novel pruning-based subspace sampling strategy. Our curated dataset, encompassing a wide range of architecture-performance pairs, encourages robust and transferable learning. Comprehensive experiments demonstrate that LM-Searcher achieves competitive performance in both in-domain (e.g., CNNs for image classification) and out-of-domain (e.g., LoRA configurations for segmentation and generation) tasks, establishing a new paradigm for flexible and generalizable LLM-based architecture search. The datasets and models will be released at https://github.com/Ashone3/LM-Searcher.