Icon$^{2}$: Aligning Large Language Models Using Self-Synthetic Preference Data via Inherent Regulation
作者: Qiyuan Chen, Hongsen Huang, Qian Shao, Jiahe Chen, Jintai Chen, Hongxia Xu, Renjie Hua, Ren Chuan, Jian Wu
分类: cs.CL, cs.AI
发布日期: 2025-09-06
备注: EMNLP 2025 Main
💡 一句话要点
提出Icon²以高效构建人类偏好数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好数据集 自合成指令 内在调节 对齐能力
📋 核心要点
- 核心问题:现有方法依赖预收集指令,导致与目标模型分布不匹配,且多样化响应采样计算开销大。
- 方法要点:提出Icon²,通过提取层级方向向量和内在一致性过滤自合成指令,构建偏好数据集。
- 实验或效果:Llama3-8B和Qwen2-7B在AlpacaEval 2.0和Arena-Hard上分别提升13.89%和13.45%,计算成本降低48.1%。
📝 摘要(中文)
大型语言模型(LLMs)需要高质量的偏好数据集以与人类偏好对齐。然而,传统构建方法面临显著挑战:依赖预先收集的指令常导致与目标模型的分布不匹配,同时多样化响应的采样引入了巨大的计算开销。本文提出了一种新范式,通过利用LLMs表示空间的内在调节,构建高效且定制的偏好数据集,命名为Icon²。具体而言,首先提取层级方向向量以编码复杂的人类偏好,然后基于内在一致性过滤自合成指令。在解码过程中,应用双向内在控制来引导标记表示,从而精确生成具有明显对齐区分的响应对。实验结果显示,在对齐和效率上均有显著提升。
🔬 方法详解
问题定义:本论文旨在解决大型语言模型对齐人类偏好的数据集构建问题。现有方法依赖于预先收集的指令,导致与目标模型的分布不匹配,同时多样化响应的采样过程计算开销巨大。
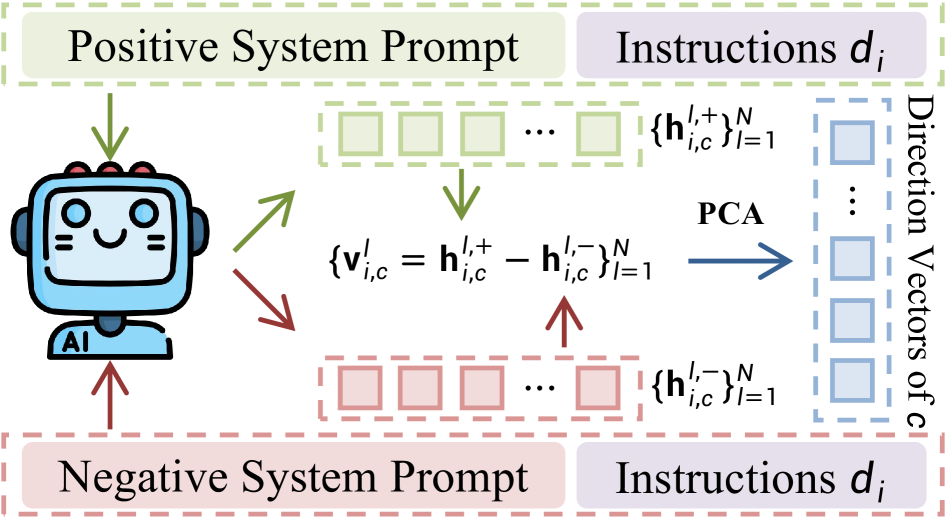
核心思路:论文提出了一种新方法Icon²,通过利用LLMs表示空间的内在调节,提取层级方向向量来编码复杂的人类偏好,并基于这些向量过滤自合成的指令,从而高效构建偏好数据集。
技术框架:整体架构包括两个主要阶段:首先提取层级方向向量以编码人类偏好,其次在解码过程中应用双向内在控制来引导标记表示,确保生成的响应对具有明显的对齐区分。
关键创新:最重要的技术创新在于利用LLMs的内在调节机制,通过层级方向向量的提取与自合成指令的过滤,显著提高了偏好数据集构建的效率和质量。这一方法与传统依赖预收集指令的方式本质上不同。
关键设计:在参数设置上,论文详细描述了层级方向向量的提取过程和自合成指令的过滤标准,确保生成的响应对在对齐性和一致性上达到最佳效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Llama3-8B和Qwen2-7B在AlpacaEval 2.0和Arena-Hard上分别实现了13.89%和13.45%的平均胜率提升,同时计算成本降低高达48.1%。这一显著的性能提升证明了Icon²方法的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和人机交互等。通过高效构建与人类偏好一致的数据集,Icon²能够提升大型语言模型的对齐能力,进而提高其在实际应用中的表现和用户体验。未来,该方法可能为更多领域的模型训练提供新的思路和方法论。
📄 摘要(原文)
Large Language Models (LLMs) require high quality preference datasets to align with human preferences. However, conventional methods for constructing such datasets face significant challenges: reliance on pre-collected instructions often leads to distribution mismatches with target models, while the need for sampling multiple stochastic responses introduces substantial computational overhead. In this work, we explore a paradigm shift by leveraging inherent regulation of LLMs' representation space for efficient and tailored preference dataset construction, named Icon$^{2}$. Specifically, it first extracts layer-wise direction vectors to encode sophisticated human preferences and then uses these vectors to filter self-synthesized instructions based on their inherent consistency. During decoding, bidirectional inherent control is applied to steer token representations, enabling the precise generation of response pairs with clear alignment distinctions. Experimental results demonstrate significant improvements in both alignment and efficiency. Llama3-8B and Qwen2-7B achieve an average win rate improvement of 13.89% on AlpacaEval 2.0 and 13.45% on Arena-Hard, while reducing computational costs by up to 48.1%.