Using Contrastive Learning to Improve Two-Way Reasoning in Large Language Models: The Obfuscation Task as a Case Study
作者: Serge Lionel Nikiema, Jordan Samhi, Micheline Bénédicte Moumoula, Albérick Euraste Djiré, Abdoul Kader Kaboré, Jacques Klein, Tegawendé F. Bissyandé
分类: cs.CL, cs.AI
发布日期: 2025-09-06
💡 一句话要点
提出对比学习微调方法,提升大语言模型在代码混淆任务中的双向推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对比学习 双向推理 大语言模型 代码混淆 认知专业化
📋 核心要点
- 现有大语言模型在单向任务上表现良好,但在逆向推理时性能显著下降,表明模型可能只是在进行模式匹配,缺乏真正的理解。
- 论文提出对比微调(CFT)方法,通过引入正例、负例和正向混淆示例,促使模型学习更深层次的语义理解,从而提升双向推理能力。
- 实验结果表明,CFT方法能够有效提升模型在代码混淆任务中的双向推理能力,在保持正向任务性能的同时,显著提升逆向推理性能。
📝 摘要(中文)
本研究探讨了一个人工智能领域的基础问题:大型语言模型是真正理解概念,还是仅仅识别模式?作者提出双向推理能力,即在没有显式反向训练的情况下,模型能否在两个方向上应用转换,以此作为衡量模型是否真正理解的标准。他们认为,真正的理解应该自然地允许可逆性。研究人员发现,模型在正向任务上进行微调时,性能会提高,但双向推理能力会显著下降,称之为认知专业化。为了解决这个问题,他们开发了对比微调(CFT),使用三种类型的示例训练模型:保持语义意义的正面示例、具有不同语义的负面示例和正向混淆示例。这种方法旨在培养更深层次的理解,而不是表面层次的模式识别,并允许反向能力在没有显式反向训练的情况下自然发展。实验表明,CFT成功实现了双向推理,在保持正向任务能力的同时,实现了强大的反向性能。作者得出结论,双向推理既可以作为评估真正理解的理论框架,也可以作为开发更强大人工智能系统的实用训练方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在双向推理能力上的不足,尤其是在代码混淆任务中。现有方法,如直接在正向任务上进行微调,会导致“认知专业化”,即模型在正向任务上表现提升,但在反向任务上表现下降。这表明模型可能只是学习了表面模式,而缺乏对语义的真正理解。
核心思路:论文的核心思路是通过对比学习,迫使模型学习区分语义相同但表达不同的样本(正例),以及语义不同的样本(负例)。同时,结合正向混淆的例子,让模型学习如何在保持语义不变的情况下进行转换,从而提升模型的泛化能力和双向推理能力。
技术框架:整体框架包括以下几个步骤:1) 构建包含正例、负例和正向混淆示例的数据集;2) 使用对比损失函数对模型进行微调;3) 在正向和反向任务上评估模型的性能。正例是语义相同但表达不同的代码片段,负例是语义不同的代码片段,正向混淆示例是将原始代码片段进行混淆后的版本。
关键创新:最重要的技术创新点在于对比微调(CFT)方法,它通过引入对比学习的思想,使得模型能够学习到更深层次的语义表示,从而提升双向推理能力。与传统的微调方法相比,CFT方法不仅关注正向任务的性能,还关注模型对语义的理解和泛化能力。
关键设计:CFT的关键设计包括:1) 选择合适的对比损失函数,例如InfoNCE loss,用于区分正例和负例;2) 设计有效的负例生成策略,例如随机替换变量名或修改代码结构;3) 合理设置正例、负例和正向混淆示例的比例,以平衡模型的学习目标;4) 针对特定任务(如代码混淆)设计合适的混淆策略,例如变量重命名、代码结构变换等。
🖼️ 关键图片

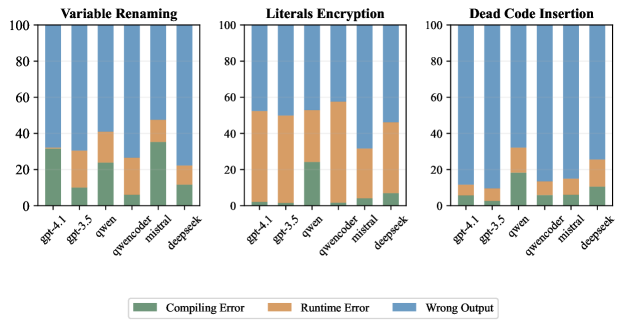
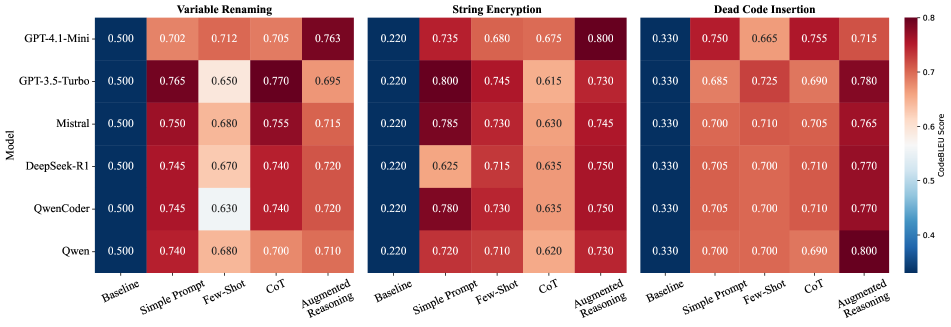
📊 实验亮点
实验结果表明,使用对比微调(CFT)方法可以显著提升模型在代码混淆任务中的双向推理能力。具体来说,在保持正向任务性能的同时,反向任务的性能得到了显著提升。这表明CFT方法能够有效提升模型对代码语义的理解,并使其具备更强的泛化能力。
🎯 应用场景
该研究成果可应用于提升代码理解、代码生成、程序修复等领域中大语言模型的性能。通过增强模型的双向推理能力,可以使其更好地理解代码的语义,从而生成更准确、更可靠的代码。此外,该方法还可以推广到其他需要双向推理能力的自然语言处理任务中,例如机器翻译、文本摘要等。
📄 摘要(原文)
This research addresses a fundamental question in AI: whether large language models truly understand concepts or simply recognize patterns. The authors propose bidirectional reasoning,the ability to apply transformations in both directions without being explicitly trained on the reverse direction, as a test for genuine understanding. They argue that true comprehension should naturally allow reversibility. For example, a model that can change a variable name like userIndex to i should also be able to infer that i represents a user index without reverse training. The researchers tested current language models and discovered what they term cognitive specialization: when models are fine-tuned on forward tasks, their performance on those tasks improves, but their ability to reason bidirectionally becomes significantly worse. To address this issue, they developed Contrastive Fine-Tuning (CFT), which trains models using three types of examples: positive examples that maintain semantic meaning, negative examples with different semantics, and forward-direction obfuscation examples. This approach aims to develop deeper understanding rather than surface-level pattern recognition and allows reverse capabilities to develop naturally without explicit reverse training. Their experiments demonstrated that CFT successfully achieved bidirectional reasoning, enabling strong reverse performance while maintaining forward task capabilities. The authors conclude that bidirectional reasoning serves both as a theoretical framework for assessing genuine understanding and as a practical training approach for developing more capable AI systems.