Creativity Benchmark: A benchmark for marketing creativity for large language models
作者: Ninad Bhat, Kieran Browne, Pip Bingemann
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-09-05 (更新: 2025-10-19)
备注: 30 Pages, 14 figures. Fixed typos
💡 一句话要点
提出Creativity Benchmark以评估大语言模型的市场创意能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 市场创意 大语言模型 评估框架 人类评估 模型多样性 品牌策略 创意生成
📋 核心要点
- 现有方法在评估大语言模型的市场创意能力时缺乏有效的标准,导致评估结果不一致且难以比较。
- 论文提出Creativity Benchmark,通过系统化的评估框架,涵盖多品牌和多种提示类型,提供更全面的创意能力评估。
- 实验结果显示,模型之间的表现差异较小,强调了人类评估的重要性,并揭示了自动评估的局限性。
📝 摘要(中文)
本文介绍了Creativity Benchmark,一个用于评估大语言模型(LLMs)在市场创意方面表现的框架。该基准涵盖100个品牌(12个类别)和三种提示类型(洞察、创意、疯狂创意)。通过对678名创意从业者的11,012次匿名比较进行分析,结果显示模型在品牌或提示类型上表现紧密聚集,没有模型在所有方面占据绝对优势。最高评分模型仅在61%的情况下胜过最低评分模型。此外,模型多样性分析表明,自动评估者无法替代人类评估,传统创意测试在品牌限制任务中也仅部分适用。整体结果强调了专家人类评估和关注多样性的工作流程的必要性。
🔬 方法详解
问题定义:本文旨在解决现有大语言模型在市场创意评估中的不足,尤其是缺乏统一标准和有效比较方法的问题。现有方法往往无法准确反映模型的创意能力。
核心思路:Creativity Benchmark通过引入多品牌和多提示类型的评估框架,结合人类评估者的偏好,提供了一种更为全面和系统的评估方式。这种设计旨在捕捉模型在不同情境下的表现差异。
技术框架:该框架包括三个主要模块:品牌选择、提示类型设计和人类评估。首先,选择100个品牌和12个类别进行评估;其次,设计三种不同的提示类型以测试模型的创意能力;最后,通过人类评估者进行对比分析,确保评估的有效性。
关键创新:最重要的创新在于引入了多样化的评估标准和人类偏好分析,克服了传统评估方法的局限性。与现有方法相比,该框架能够更好地反映模型在实际应用中的表现。
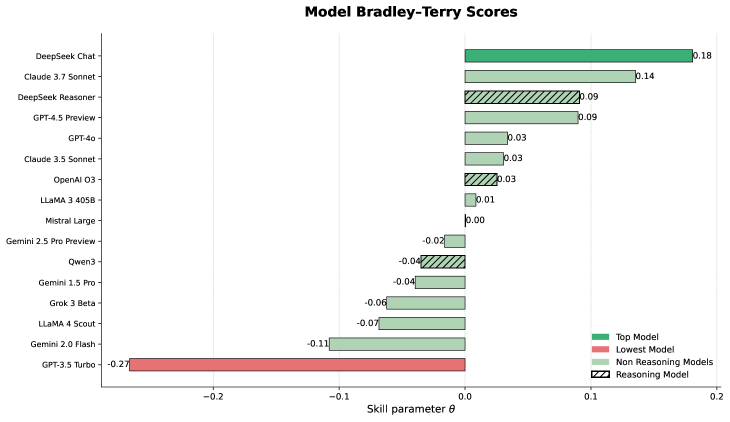
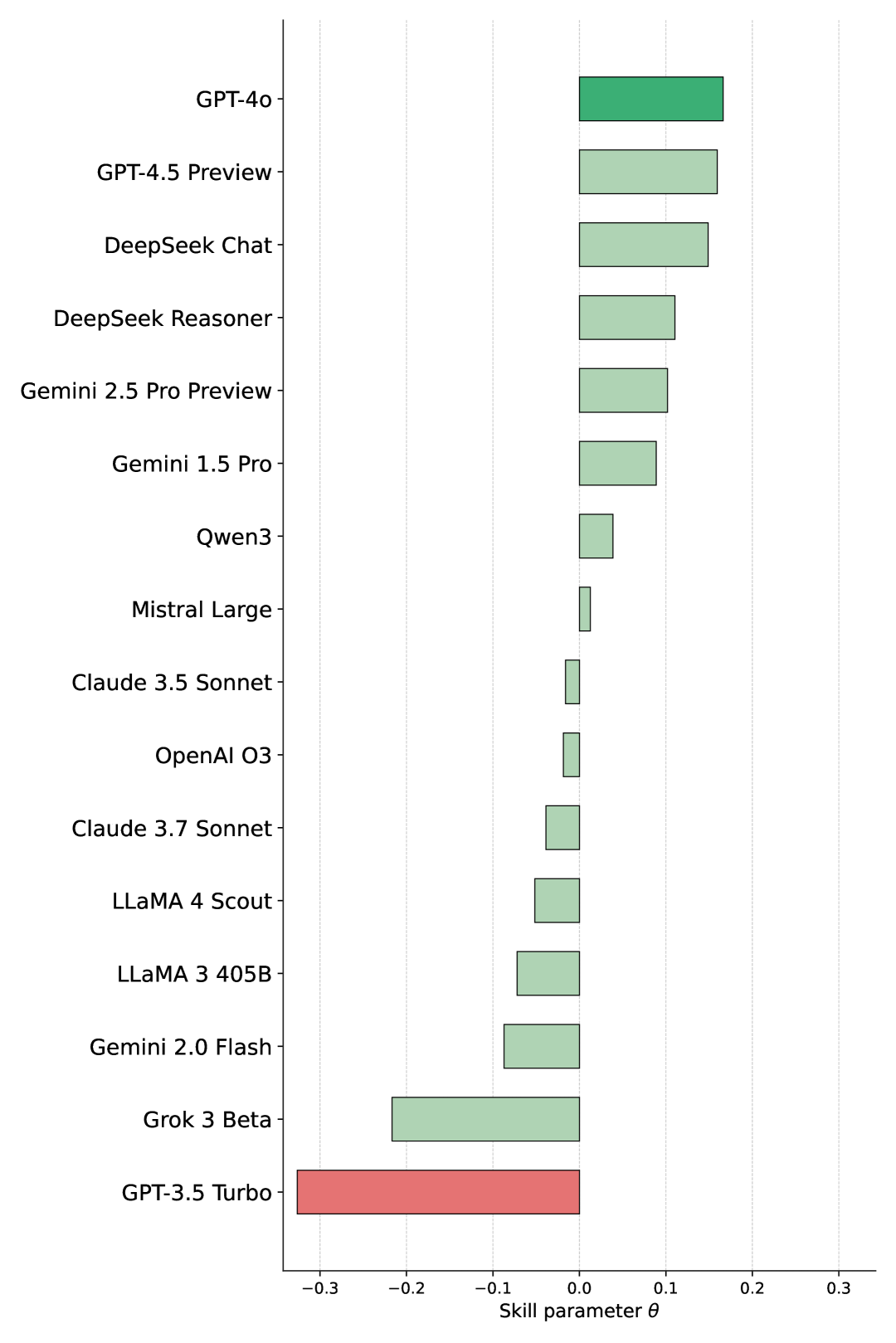
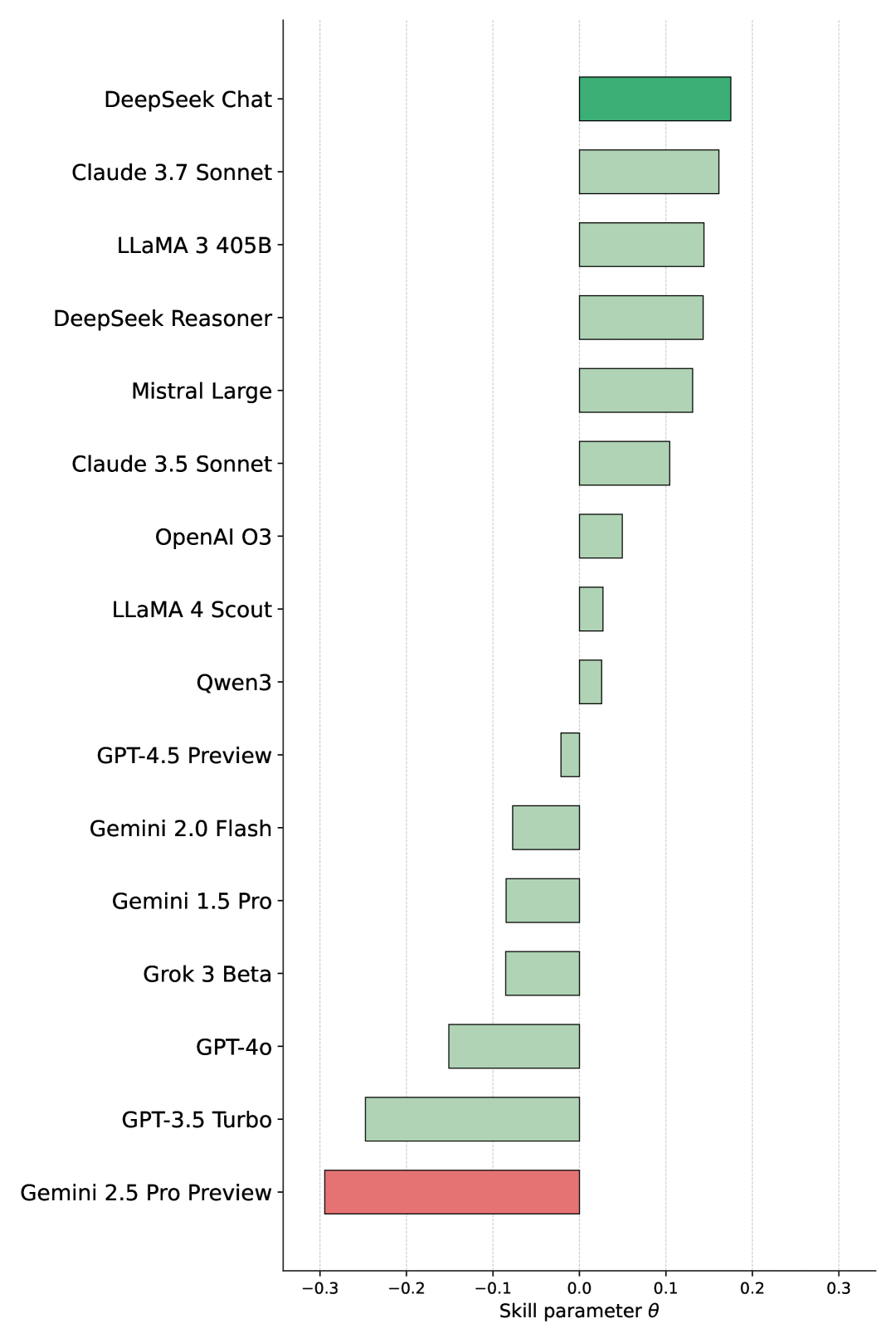
关键设计:在实验中,采用Bradley-Terry模型分析人类偏好,设置了多种提示类型,并使用余弦距离分析模型多样性。这些设计确保了评估的全面性和准确性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,模型在不同品牌和提示类型上的表现差异小,最高评分模型在对比中仅以61%的概率胜过最低评分模型。这表明现有模型在创意生成方面的能力相对接近,强调了人类评估的重要性和必要性。
🎯 应用场景
该研究的潜在应用领域包括市场营销、广告创意生成和品牌策略制定等。通过提供一个标准化的评估框架,企业可以更有效地利用大语言模型生成创意内容,从而提升市场竞争力。未来,该框架可能会推动更多领域的创意评估标准化进程。
📄 摘要(原文)
We introduce Creativity Benchmark, an evaluation framework for large language models (LLMs) in marketing creativity. The benchmark covers 100 brands (12 categories) and three prompt types (Insights, Ideas, Wild Ideas). Human pairwise preferences from 678 practising creatives over 11,012 anonymised comparisons, analysed with Bradley-Terry models, show tightly clustered performance with no model dominating across brands or prompt types: the top-bottom spread is $Δθ\approx 0.45$, which implies a head-to-head win probability of $0.61$; the highest-rated model beats the lowest only about $61\%$ of the time. We also analyse model diversity using cosine distances to capture intra- and inter-model variation and sensitivity to prompt reframing. Comparing three LLM-as-judge setups with human rankings reveals weak, inconsistent correlations and judge-specific biases, underscoring that automated judges cannot substitute for human evaluation. Conventional creativity tests also transfer only partially to brand-constrained tasks. Overall, the results highlight the need for expert human evaluation and diversity-aware workflows.