The Token Tax: Systematic Bias in Multilingual Tokenization
作者: Jessica M. Lundin, Ada Zhang, Nihal Karim, Hamza Louzan, Victor Wei, David Adelani, Cody Carroll
分类: cs.CL, cs.AI
发布日期: 2025-09-05
💡 一句话要点
揭示多语言分词偏差:Token Tax对低资源语言的影响与应对
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言分词 低资源语言 Token Tax 语言模型评估 形态感知分词
📋 核心要点
- 现有分词器对形态复杂的低资源语言处理效率低,导致计算成本增加和模型准确率下降。
- 论文核心思想是揭示分词粒度与模型性能之间的关系,并量化分词效率低下带来的经济成本。
- 实验表明,分词粒度越高,模型准确率越低,且推理模型在各种资源语言上表现更优。
📝 摘要(中文)
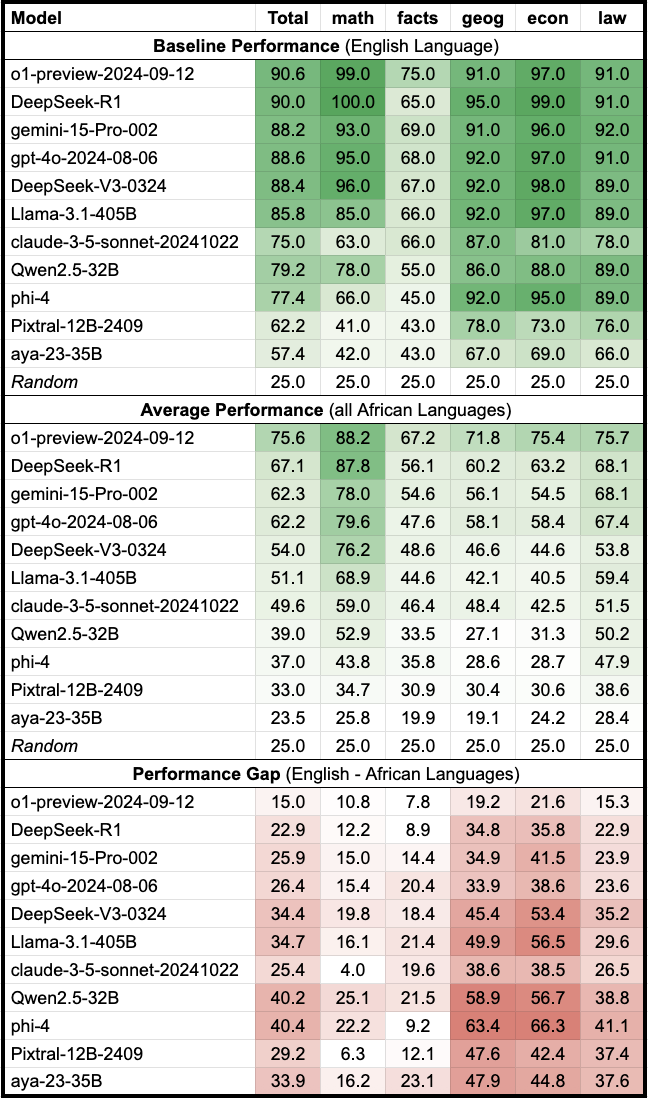
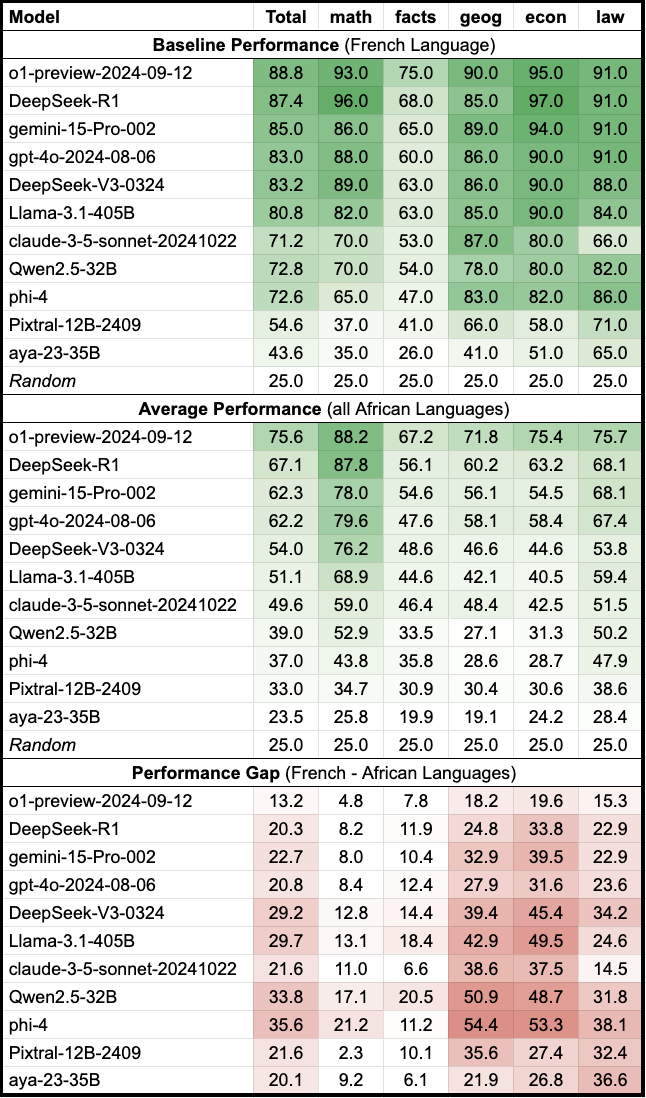
本文研究了分词效率低下对形态复杂、低资源语言造成的结构性劣势,这种劣势体现在计算资源的消耗和准确率的降低。作者在AfriMMLU数据集(包含16种非洲语言的9000个多项选择题)上评估了10个大型语言模型(LLM),发现分词粒度(tokens/word)与准确率之间存在可靠的预测关系。更高的分词粒度始终预测更低的准确率。此外,推理模型(DeepSeek, o1)在AfriMMLU数据集的高低资源语言上始终优于非推理模型,缩小了先前模型世代中观察到的准确率差距。最后,将token膨胀转化为经济成本,token数量翻倍会导致训练成本和时间增加四倍,突显了许多语言面临的token tax。这些结果促使人们关注形态感知的分词、公平定价以及用于公平自然语言处理(NLP)的多语言基准。
🔬 方法详解
问题定义:论文旨在解决多语言分词器在处理形态复杂、低资源语言时效率低下的问题。现有分词器通常针对高资源语言进行优化,导致在处理低资源语言时产生过多的token,增加了计算成本并降低了模型性能。这种现象被称为“Token Tax”,它对低资源语言的NLP发展造成了不公平的结构性劣势。
核心思路:论文的核心思路是通过实证研究揭示分词粒度与模型性能之间的关系,并量化分词效率低下带来的经济成本。作者假设分词粒度越高,模型准确率越低,并且这种现象在低资源语言中更为明显。此外,作者还研究了不同类型的模型(如推理模型和非推理模型)在处理不同资源语言时的表现差异。
技术框架:论文的技术框架主要包括以下几个步骤:1) 在AfriMMLU数据集上评估10个大型语言模型(LLM)的性能;2) 分析分词粒度与模型准确率之间的关系;3) 比较不同类型模型在处理高低资源语言时的表现;4) 将token膨胀转化为经济成本,量化“Token Tax”的影响。AfriMMLU数据集包含16种非洲语言的9000个多项选择题,涵盖5个学科。
关键创新:论文的关键创新在于:1) 首次系统性地揭示了多语言分词器在处理低资源语言时存在的偏差,并将其命名为“Token Tax”;2) 通过实证研究量化了分词粒度与模型性能之间的关系;3) 提出了形态感知的分词、公平定价以及用于公平自然语言处理(NLP)的多语言基准等解决方案。
关键设计:论文的关键设计包括:1) 使用AfriMMLU数据集作为评估基准,该数据集覆盖了多种非洲低资源语言;2) 选择10个具有代表性的大型语言模型进行评估,包括推理模型和非推理模型;3) 使用分词粒度(tokens/word)作为衡量分词效率的指标;4) 通过回归分析等统计方法分析分词粒度与模型准确率之间的关系;5) 将token数量与训练成本和时间进行关联,量化“Token Tax”的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,分词粒度(tokens/word)与模型准确率之间存在显著的负相关关系。更高的分词粒度始终预测更低的准确率。例如,token数量翻倍会导致训练成本和时间增加四倍。此外,推理模型(DeepSeek, o1)在AfriMMLU数据集的高低资源语言上始终优于非推理模型,缩小了先前模型世代中观察到的准确率差距。
🎯 应用场景
该研究成果可应用于改进多语言NLP系统的设计,特别是在处理低资源语言时。通过采用形态感知的分词方法,可以减少token数量,降低计算成本,并提高模型准确率。此外,该研究还强调了公平定价和多语言基准的重要性,有助于促进更公平、更包容的NLP技术发展。未来的研究可以探索更有效的低资源语言分词方法,并开发更全面的多语言评估基准。
📄 摘要(原文)
Tokenization inefficiency imposes structural disadvantages on morphologically complex, low-resource languages, inflating compute resources and depressing accuracy. We evaluate 10 large language models (LLMs) on AfriMMLU (9,000 MCQA items; 5 subjects; 16 African languages) and show that fertility (tokens/word) reliably predicts accuracy. Higher fertility consistently predicts lower accuracy across all models and subjects. We further find that reasoning models (DeepSeek, o1) consistently outperform non-reasoning peers across high and low resource languages in the AfriMMLU dataset, narrowing accuracy gaps observed in prior generations. Finally, translating token inflation to economics, a doubling in tokens results in quadrupled training cost and time, underscoring the token tax faced by many languages. These results motivate morphologically aware tokenization, fair pricing, and multilingual benchmarks for equitable natural language processing (NLP).