A Lightweight Framework for Trigger-Guided LoRA-Based Self-Adaptation in LLMs
作者: Jiacheng Wei, Faguo Wu, Xiao Zhang
分类: cs.CL, cs.AI
发布日期: 2025-09-05
备注: 11 pages, 7 figures, conference
💡 一句话要点
提出SAGE框架,通过触发器引导LoRA自适应调整LLM以提升推理时性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 动态微调 LoRA 触发器 自适应学习
📋 核心要点
- 现有大语言模型在推理过程中无法持续学习新知识,导致性能受限,难以适应变化。
- SAGE框架通过触发器检测推理失败,并利用LoRA动态微调模型参数,实现推理时的自适应更新。
- 实验表明,SAGE在原子推理子任务上表现出优秀的准确性、鲁棒性和稳定性,验证了其有效性。
📝 摘要(中文)
大型语言模型在推理时无法持续地从新数据中学习和适应。为了解决这个局限性,我们提出将复杂的推理任务分解为原子子任务,并引入SAGE,这是一个触发器引导的动态微调框架,能够在推理时实现自适应更新。SAGE包含三个关键组件:(1)一个触发器模块,通过多个评估指标实时检测推理失败;(2)一个触发器缓冲模块,使用带有HDBSCAN的流式聚类过程来聚类异常样本,然后进行稳定性检查和基于相似性的合并;(3)一个Lora存储模块,使用适配器池动态优化参数更新以保持知识。评估结果表明,SAGE通过测试时动态知识更新,在原子推理子任务上表现出卓越的准确性、鲁棒性和稳定性。
🔬 方法详解
问题定义:大型语言模型在推理阶段无法持续学习和适应新数据,导致其在面对不断变化的知识和任务时性能下降。现有的微调方法通常是离线的,无法在推理过程中进行动态调整,因此无法满足实时性和自适应性的需求。
核心思路:SAGE的核心思路是利用触发器机制实时检测推理过程中的失败案例,并将这些失败案例作为信号,引导模型进行动态微调。通过将复杂的推理任务分解为原子子任务,可以更精确地定位问题并进行针对性的知识更新。使用LoRA(Low-Rank Adaptation)可以高效地调整模型参数,避免全参数微调带来的计算开销和灾难性遗忘问题。
技术框架:SAGE框架包含三个主要模块: 1. 触发器模块(Trigger Module):负责实时检测推理失败。该模块使用多个评估指标来判断推理结果的正确性,例如置信度、一致性等。 2. 触发器缓冲模块(Trigger Buffer Module):用于存储和管理检测到的异常样本。该模块使用HDBSCAN进行流式聚类,将相似的异常样本聚类在一起,并进行稳定性检查和相似性合并,以减少冗余。 3. Lora存储模块(Lora Store Module):负责动态优化参数更新。该模块维护一个适配器池,每个适配器对应一种特定的知识或技能。当触发器检测到推理失败时,该模块会选择合适的适配器进行微调,从而实现知识的动态更新。
关键创新:SAGE的关键创新在于其触发器引导的动态微调机制。与传统的离线微调方法不同,SAGE能够在推理过程中实时检测问题并进行自适应调整,从而更好地适应变化的环境。此外,SAGE还采用了LoRA技术,可以高效地进行参数更新,避免了全参数微调带来的问题。
关键设计: * 触发器模块:使用了多种评估指标,例如置信度、一致性等,以提高检测推理失败的准确性。 * 触发器缓冲模块:使用了HDBSCAN进行流式聚类,可以有效地处理大量的异常样本,并减少冗余。 * Lora存储模块:维护了一个适配器池,每个适配器对应一种特定的知识或技能,可以实现更精细的知识更新。 * 损失函数:采用了交叉熵损失函数,用于优化LoRA适配器的参数。
🖼️ 关键图片


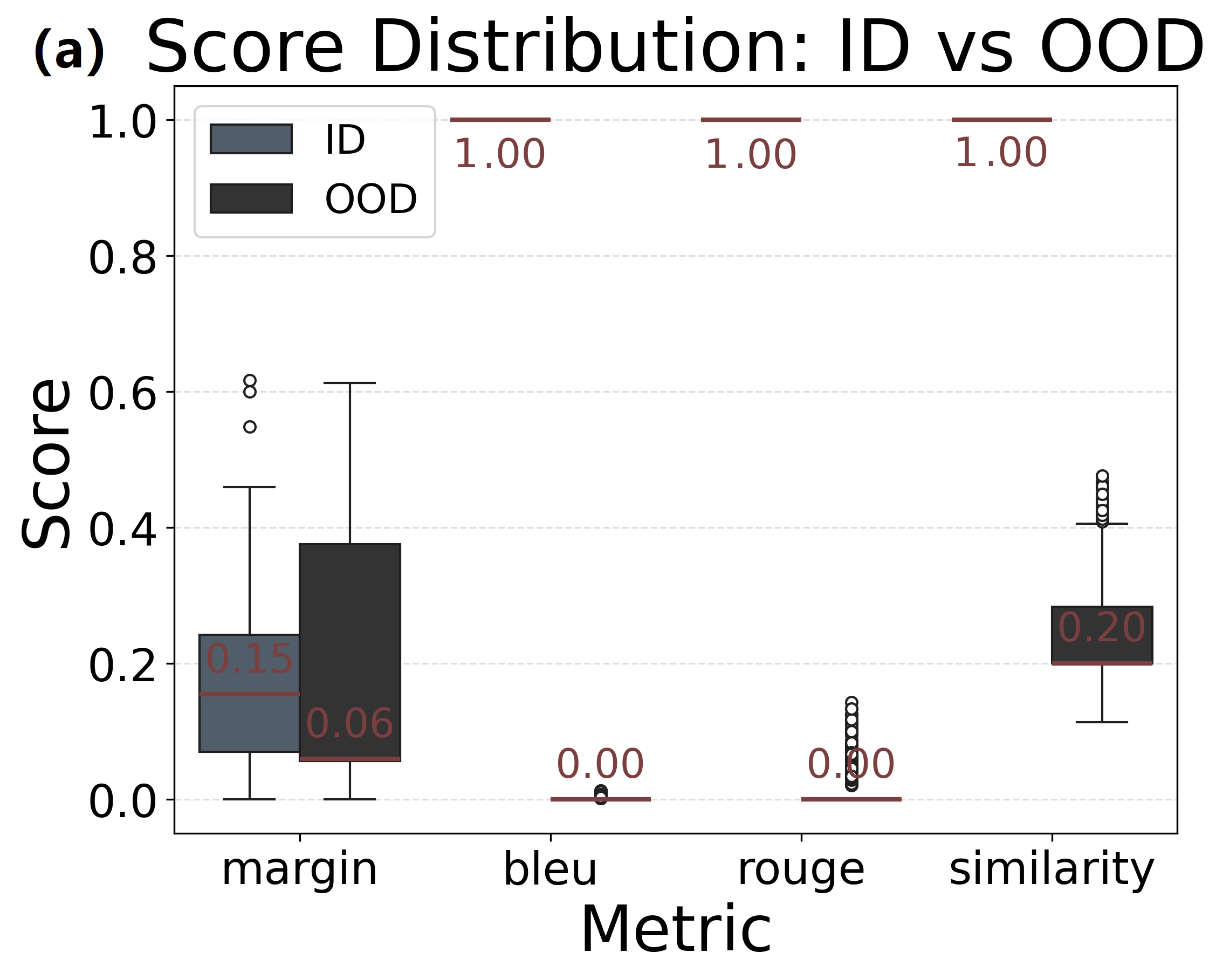
📊 实验亮点
实验结果表明,SAGE框架在原子推理子任务上表现出卓越的性能。通过动态知识更新,SAGE显著提高了模型的准确性、鲁棒性和稳定性。具体来说,SAGE在多个数据集上取得了优于基线模型的性能,并且在面对噪声数据和对抗攻击时表现出更强的抵抗能力。这些结果验证了SAGE框架的有效性和优越性。
🎯 应用场景
SAGE框架可应用于需要持续学习和适应新知识的各种场景,例如智能客服、对话系统、知识问答等。通过在推理过程中动态更新知识,SAGE可以提高模型的准确性、鲁棒性和稳定性,从而提供更优质的服务。此外,该框架还可以用于个性化推荐、智能搜索等领域,根据用户的实时反馈进行模型调整,提升用户体验。
📄 摘要(原文)
Large language models are unable to continuously adapt and learn from new data during reasoning at inference time. To address this limitation, we propose that complex reasoning tasks be decomposed into atomic subtasks and introduce SAGE, a trigger-guided dynamic fine-tuning framework that enables adaptive updates during reasoning at inference time. SAGE consists of three key components: (1) a Trigger module that detects reasoning failures through multiple evaluation metrics in real time; (2) a Trigger Buffer module that clusters anomaly samples using a streaming clustering process with HDBSCAN, followed by stability checks and similarity-based merging; and (3) a Lora Store module that dynamically optimizes parameter updates with an adapter pool for knowledge retention. Evaluation results show that SAGE demonstrates excellent accuracy, robustness, and stability on the atomic reasoning subtask through dynamic knowledge updating during test time.