PLaMo 2 Technical Report
作者: Preferred Networks, :, Kaizaburo Chubachi, Yasuhiro Fujita, Shinichi Hemmi, Yuta Hirokawa, Kentaro Imajo, Toshiki Kataoka, Goro Kobayashi, Kenichi Maehashi, Calvin Metzger, Hiroaki Mikami, Shogo Murai, Daisuke Nishino, Kento Nozawa, Toru Ogawa, Shintarou Okada, Daisuke Okanohara, Shunta Saito, Shotaro Sano, Shuji Suzuki, Kuniyuki Takahashi, Daisuke Tanaka, Avinash Ummadisingu, Hanqin Wang, Sixue Wang, Tianqi Xu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-05 (更新: 2025-09-25)
💡 一句话要点
PLaMo 2:面向日语的混合架构大型语言模型,通过持续预训练支持32K上下文。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 日语NLP 混合架构 模型剪枝 合成数据 持续预训练 指令微调
📋 核心要点
- 现有日语大型语言模型面临数据稀缺和计算成本高的挑战,限制了模型性能和应用。
- PLaMo 2采用混合架构和持续预训练,结合合成数据和模型剪枝,提升效率并扩展上下文长度。
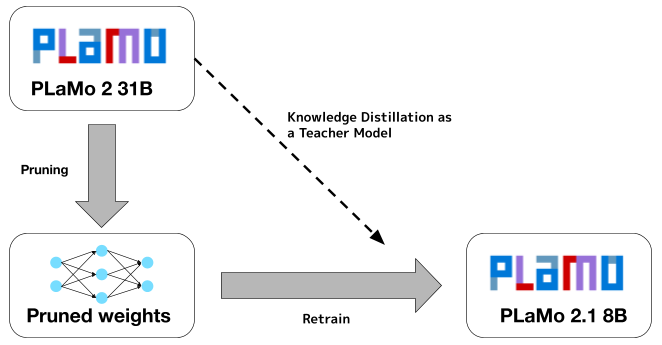
- 实验表明,PLaMo 2的8B模型性能媲美之前的100B模型,并在日语基准测试中取得领先成果。
📝 摘要(中文)
本报告介绍了PLaMo 2,这是一系列以日语为中心的大型语言模型,采用基于Samba的混合架构,通过持续预训练过渡到完全注意力机制,以支持32K token的上下文长度。训练利用广泛的合成语料库来克服数据稀缺问题,并通过权重重用和结构化剪枝实现计算效率。这种高效的剪枝方法产生了一个8B模型,其性能与我们之前的100B模型相当。后训练阶段,通过监督微调(SFT)和直接偏好优化(DPO)的流程进一步优化模型,并使用合成日语指令数据和模型合并技术进行增强。PLaMo 2模型使用vLLM进行优化推理,并使用量化技术在最小化精度损失的前提下,在日语基准测试中实现了最先进的结果,在指令遵循、语言流畅性和日语特定知识方面优于类似规模的开放模型。
🔬 方法详解
问题定义:日语大型语言模型面临数据稀缺的问题,高质量的日语数据难以获取,这限制了模型的训练效果。此外,训练和推理大型语言模型需要大量的计算资源,成本高昂。现有方法在处理长文本上下文时效率较低,难以捕捉长距离依赖关系。
核心思路:PLaMo 2的核心思路是利用合成数据增强训练集,并通过混合架构和模型剪枝提高计算效率。通过持续预训练,模型能够更好地适应长文本上下文。模型合并技术用于融合不同模型的优点,进一步提升性能。
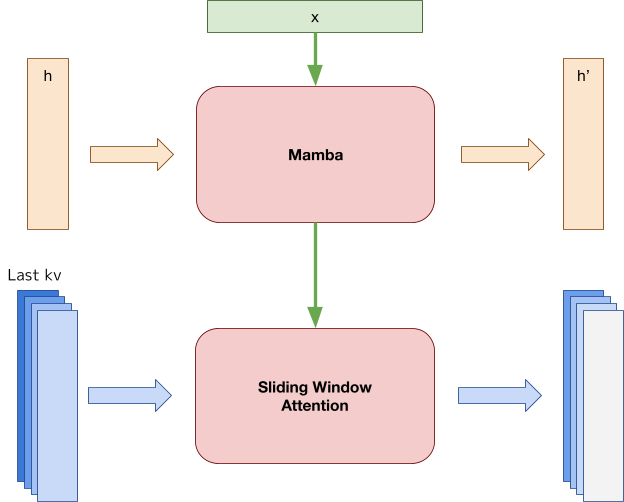
技术框架:PLaMo 2采用混合架构,初期使用基于Samba的架构,之后通过持续预训练过渡到完全注意力机制。训练过程包括预训练、监督微调(SFT)和直接偏好优化(DPO)三个阶段。预训练阶段使用大量的合成日语数据。SFT阶段使用合成日语指令数据进行微调。DPO阶段使用偏好数据进一步优化模型。模型使用vLLM进行推理优化,并采用量化技术降低计算成本。
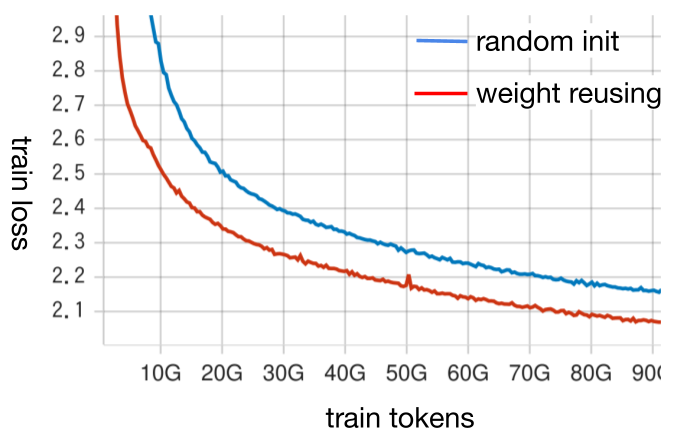
关键创新:PLaMo 2的关键创新在于混合架构的设计,它允许模型在计算效率和性能之间取得平衡。结构化剪枝方法能够有效地减少模型参数,同时保持模型的性能。利用合成数据克服数据稀缺问题也是一个重要的创新点。
关键设计:PLaMo 2的关键设计包括:1) 使用Samba架构进行初始训练,然后过渡到完全注意力机制;2) 利用合成数据生成高质量的日语训练语料;3) 采用结构化剪枝方法减少模型参数;4) 使用监督微调(SFT)和直接偏好优化(DPO)进行后训练;5) 使用vLLM进行推理优化,并采用量化技术降低计算成本。具体的参数设置、损失函数和网络结构等细节在论文正文中应该有更详细的描述,此处未知。
🖼️ 关键图片
📊 实验亮点
PLaMo 2的8B模型在日语基准测试中取得了最先进的结果,其性能与之前的100B模型相当。在指令遵循、语言流畅性和日语特定知识方面,PLaMo 2优于类似规模的开放模型。通过结构化剪枝和量化技术,PLaMo 2实现了高效的推理,降低了计算成本。
🎯 应用场景
PLaMo 2可应用于各种日语自然语言处理任务,如机器翻译、文本摘要、问答系统、对话生成等。其高效的推理能力使其能够部署在资源受限的设备上。该研究对于推动日语自然语言处理技术的发展具有重要意义,并可促进相关产业的创新。
📄 摘要(原文)
In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.