Memorization $\neq$ Understanding: Do Large Language Models Have the Ability of Scenario Cognition?
作者: Boxiang Ma, Ru Li, Yuanlong Wang, Hongye Tan, Xiaoli Li
分类: cs.CL
发布日期: 2025-09-05
备注: EMNLP 2025 Main Conference
💡 一句话要点
提出双视角评估框架,揭示大语言模型在情景认知方面依赖记忆而非理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 情景认知 语义理解 评估框架 内部表征 记忆能力 泛化能力
📋 核心要点
- 现有大语言模型在NLP任务中表现出色,但其泛化能力是源于记忆还是理解尚不明确。
- 论文提出双视角评估框架,通过情景认知能力评估模型是否真正理解语义。
- 实验表明,当前大语言模型主要依赖记忆,在情景认知方面存在局限性。
📝 摘要(中文)
大型语言模型(LLMs)在大量且多样化的文本数据驱动下,在众多自然语言处理(NLP)任务中表现出令人印象深刻的性能。然而,一个关键问题仍然存在:它们的泛化能力是源于对训练数据的简单记忆,还是源于深刻的语义理解?为了研究这个问题,我们提出了一个双视角评估框架,以评估LLMs的情景认知能力——即在上下文中将语义情景元素与其论证联系起来的能力。具体来说,我们引入了一个新的基于情景的数据集,该数据集包含对虚构事实的各种文本描述,并标注了情景元素。通过LLMs回答情景相关问题的能力(模型输出视角)以及通过探测其内部表征中编码的情景元素-论证关联(内部表征视角)来评估LLMs。我们的实验表明,当前的LLMs主要依赖于肤浅的记忆,即使在简单的情况下也未能实现稳健的语义情景认知。这些发现揭示了LLMs在语义理解方面的关键局限性,并为提升其能力提供了认知见解。
🔬 方法详解
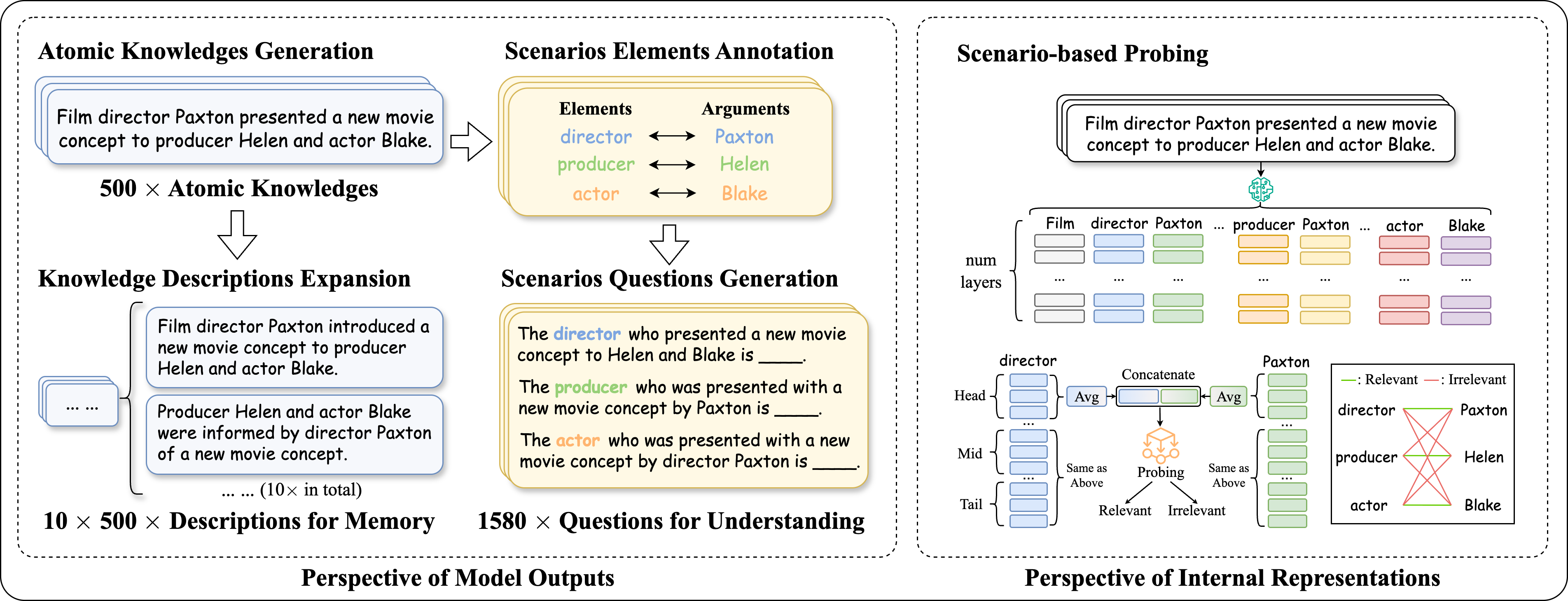
问题定义:论文旨在解决大语言模型(LLMs)是否真正具备语义理解能力的问题,而非仅仅依赖于对训练数据的记忆。现有方法难以有效区分LLMs的泛化能力是源于记忆还是理解,缺乏针对性的评估框架。LLMs在情景认知方面的能力不足,无法将语义情景元素与其论证联系起来,限制了其在复杂场景下的应用。
核心思路:论文的核心思路是通过构建一个基于情景的数据集,并设计双视角评估框架来评估LLMs的情景认知能力。该框架从模型输出和内部表征两个角度考察LLMs是否真正理解情景语义,而非仅仅记住训练数据。
技术框架:该研究的技术框架主要包含以下几个部分:1)构建基于情景的数据集,包含虚构事实的文本描述和标注的情景元素;2)设计模型输出视角评估,通过让LLMs回答情景相关问题来评估其理解能力;3)设计内部表征视角评估,通过探测LLMs内部表征中编码的情景元素-论证关联来评估其理解能力;4)综合分析两个视角的评估结果,判断LLMs是否具备真正的情景认知能力。
关键创新:论文的关键创新在于提出了一个双视角评估框架,能够更全面、深入地评估LLMs的语义理解能力,特别是其情景认知能力。该框架不仅关注模型的输出结果,还关注模型的内部表征,从而能够更准确地判断LLMs是否真正理解语义。此外,论文还构建了一个新的基于情景的数据集,为评估LLMs的情景认知能力提供了数据基础。
关键设计:在数据集构建方面,论文设计了包含虚构事实的文本描述,并标注了情景元素,例如参与者、动作、地点、时间等。在模型输出视角评估中,论文设计了多种类型的情景相关问题,例如推理问题、细节问题等。在内部表征视角评估中,论文采用了探测技术,通过训练分类器来预测LLMs内部表征中编码的情景元素-论证关联。具体的参数设置、损失函数、网络结构等技术细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当前的大语言模型在情景认知方面主要依赖于记忆,即使在简单的情景下也未能实现稳健的语义理解。通过双视角评估框架,研究人员发现LLMs在回答情景相关问题时,往往只能记住训练数据中的表面信息,而无法真正理解情景的语义关系。具体的性能数据、对比基线、提升幅度等未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型的语义理解能力,尤其是在需要情景认知的任务中,例如智能对话、阅读理解、知识图谱构建等。通过更准确地评估LLMs的理解能力,可以更好地指导模型训练和优化,从而提高LLMs在实际应用中的性能和可靠性。未来的研究可以基于该框架,探索更有效的方法来提升LLMs的情景认知能力。
📄 摘要(原文)
Driven by vast and diverse textual data, large language models (LLMs) have demonstrated impressive performance across numerous natural language processing (NLP) tasks. Yet, a critical question persists: does their generalization arise from mere memorization of training data or from deep semantic understanding? To investigate this, we propose a bi-perspective evaluation framework to assess LLMs' scenario cognition - the ability to link semantic scenario elements with their arguments in context. Specifically, we introduce a novel scenario-based dataset comprising diverse textual descriptions of fictional facts, annotated with scenario elements. LLMs are evaluated through their capacity to answer scenario-related questions (model output perspective) and via probing their internal representations for encoded scenario elements-argument associations (internal representation perspective). Our experiments reveal that current LLMs predominantly rely on superficial memorization, failing to achieve robust semantic scenario cognition, even in simple cases. These findings expose critical limitations in LLMs' semantic understanding and offer cognitive insights for advancing their capabilities.