WildScore: Benchmarking MLLMs in-the-Wild Symbolic Music Reasoning
作者: Gagan Mundada, Yash Vishe, Amit Namburi, Xin Xu, Zachary Novack, Julian McAuley, Junda Wu
分类: cs.SD, cs.CL, eess.AS
发布日期: 2025-09-05 (更新: 2026-01-23)
💡 一句话要点
WildScore:提出一个在真实场景下评估多模态大语言模型音乐推理能力的基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 音乐推理 符号音乐 大语言模型 基准测试
📋 核心要点
- 现有的多模态大语言模型在视觉-语言任务中表现出色,但在符号音乐领域的推理能力尚未充分探索。
- WildScore基准测试通过真实乐谱和用户提问,将复杂的音乐推理转化为多项选择题,评估模型理解能力。
- 实验结果揭示了现有模型在视觉-符号推理中的优势与不足,为未来研究指明方向。
📝 摘要(中文)
本文提出了WildScore,这是首个在真实场景下进行多模态符号音乐推理和分析的基准,旨在评估多模态大语言模型(MLLM)理解真实世界乐谱并回答复杂音乐学问题的能力。WildScore的每个实例都来源于真实的音乐作品,并附带有真实用户生成的问题和讨论,捕捉了实际音乐分析的复杂性。为了方便系统评估,本文提出了一个系统的分类法,包括高层次和细粒度的音乐学本体。此外,本文将复杂的音乐推理转化为多项选择问答,从而能够对MLLM的符号音乐理解进行可控和可扩展的评估。对最先进的MLLM在WildScore上的实证基准测试揭示了它们在视觉-符号推理中有趣的模式,揭示了符号音乐推理和分析中MLLM有希望的方向和持续存在的挑战。数据集和代码已开源。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在真实场景下对符号音乐进行推理和分析能力不足的问题。现有方法缺乏针对真实乐谱的评估基准,难以有效衡量模型在实际音乐分析任务中的表现。现有的数据集和评估方法无法捕捉真实音乐分析的复杂性和细微差别。
核心思路:论文的核心思路是构建一个贴近真实场景的音乐推理基准WildScore,该基准包含真实的乐谱图像、用户生成的问题和讨论。通过将复杂的音乐推理任务转化为多项选择问答形式,实现对MLLM音乐理解能力的可控和可扩展评估。
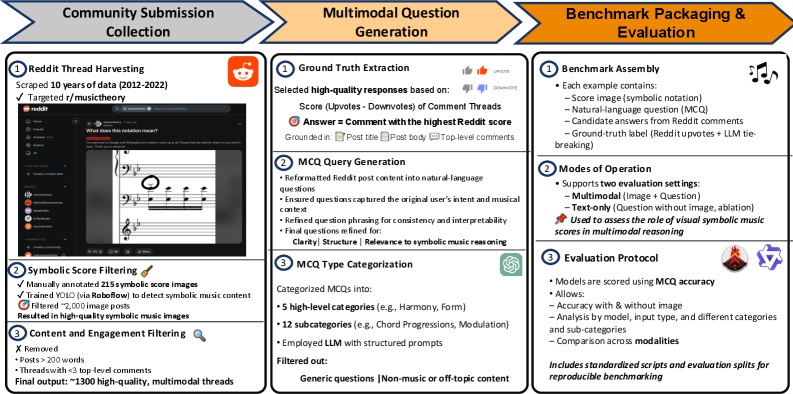
技术框架:WildScore基准测试的构建流程主要包括以下几个阶段:1) 数据收集:从真实的音乐作品中收集乐谱图像和相关的用户提问及讨论。2) 问题构建:将用户提问转化为多项选择题,并提供正确的答案和干扰项。3) 分类体系构建:设计一个系统的音乐学分类体系,包括高层次和细粒度的音乐学本体,用于对问题进行分类。4) 模型评估:使用构建好的基准测试评估现有的MLLM,并分析其在不同类型问题上的表现。
关键创新:WildScore的关键创新在于其真实性和复杂性。它不是基于人工合成的乐谱或问题,而是来源于真实的音乐作品和用户互动,能够更好地反映实际音乐分析的挑战。此外,将音乐推理转化为多项选择问答的形式,使得评估过程更加可控和可扩展。
关键设计:WildScore的数据来源于真实的音乐作品,问题来源于用户提问,保证了数据的真实性。分类体系的设计参考了音乐学领域的专业知识,确保了问题的覆盖范围和深度。多项选择题的干扰项设计需要具有一定的迷惑性,以区分模型是否真正理解了音乐知识。
🖼️ 关键图片

📊 实验亮点
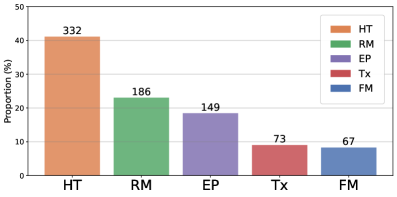
通过在WildScore上对现有MLLM进行基准测试,论文揭示了模型在视觉-符号推理中存在的优势和不足。例如,模型在某些类型的音乐问题上表现良好,但在处理复杂和细微的音乐概念时仍然面临挑战。这些结果为未来研究提供了重要的参考,并指明了改进MLLM音乐理解能力的方向。
🎯 应用场景
该研究成果可应用于音乐教育、音乐创作辅助、音乐信息检索等领域。通过提升多模态大语言模型对音乐的理解能力,可以开发出更智能的音乐学习工具,辅助作曲家进行创作,并提高音乐检索的准确性和效率。未来,该研究有望推动音乐人工智能的发展,促进音乐与科技的融合。
📄 摘要(原文)
Recent advances in Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, their reasoning abilities in the multimodal symbolic music domain remain largely unexplored. We introduce WildScore, the first in-the-wild multimodal symbolic music reasoning and analysis benchmark, designed to evaluate MLLMs' capacity to interpret real-world music scores and answer complex musicological queries. Each instance in WildScore is sourced from genuine musical compositions and accompanied by authentic user-generated questions and discussions, capturing the intricacies of practical music analysis. To facilitate systematic evaluation, we propose a systematic taxonomy, comprising both high-level and fine-grained musicological ontologies. Furthermore, we frame complex music reasoning as multiple-choice question answering, enabling controlled and scalable assessment of MLLMs' symbolic music understanding. Empirical benchmarking of state-of-the-art MLLMs on WildScore reveals intriguing patterns in their visual-symbolic reasoning, uncovering both promising directions and persistent challenges for MLLMs in symbolic music reasoning and analysis. We release the dataset and code.