OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
作者: Wei Chu, Yuanzhe Dong, Ke Tan, Dong Han, Xavier Menendez-Pidal, Ruchao Fan, Chenfeng Miao, Chanwoo Kim, Bhiksha Raj, Rita Singh
分类: cs.CL
发布日期: 2025-09-04
💡 一句话要点
OleSpeech-IV:一个大规模、多说话人、多语种、主题多样的会话语音数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会话语音数据集 多说话人 多语种 语音识别 说话人识别 语音合成 大规模数据集
📋 核心要点
- 现有会话语音数据集在规模、说话人数量、语种多样性和主题覆盖度方面存在局限性,难以满足复杂语音任务的需求。
- OleSpeech-IV通过收集和处理大量公开的会话语音数据,构建了一个大规模、多说话人、多语种且主题多样的数据集。
- 该数据集提供人工标注的说话人信息、发言轮次和文本转录,以及自动生成的附加信息,为语音研究提供丰富资源。
📝 摘要(中文)
OleSpeech-IV数据集是一个大规模、多说话人、多语种、主题多样的会话语音数据集。音频内容来自公开的英语播客、脱口秀、电话会议和其他对话。说话人姓名、发言轮次和文本转录由人工标注,并通过专有流程进行优化,而时间戳和置信度分数等附加信息则来自该流程。IV表示其在Olewave数据集系列中作为第四层级的位置。此外,我们已经开源了一个子集OleSpeech-IV-2025-EN-AR-100,供非商业研究使用。
🔬 方法详解
问题定义:现有的会话语音数据集通常规模较小,说话人数量有限,语种单一,主题覆盖范围窄,难以满足语音识别、说话人识别、语音合成等任务对数据量的需求,尤其是在多语种和跨领域场景下。此外,数据标注的质量和信息完整性也是一个挑战。
核心思路:OleSpeech-IV的核心思路是通过大规模收集公开的会话语音数据,并结合人工标注和自动化处理流程,构建一个高质量、大规模、多说话人、多语种且主题多样的数据集。通过这种方式,可以克服现有数据集的局限性,为语音研究提供更强大的数据支持。
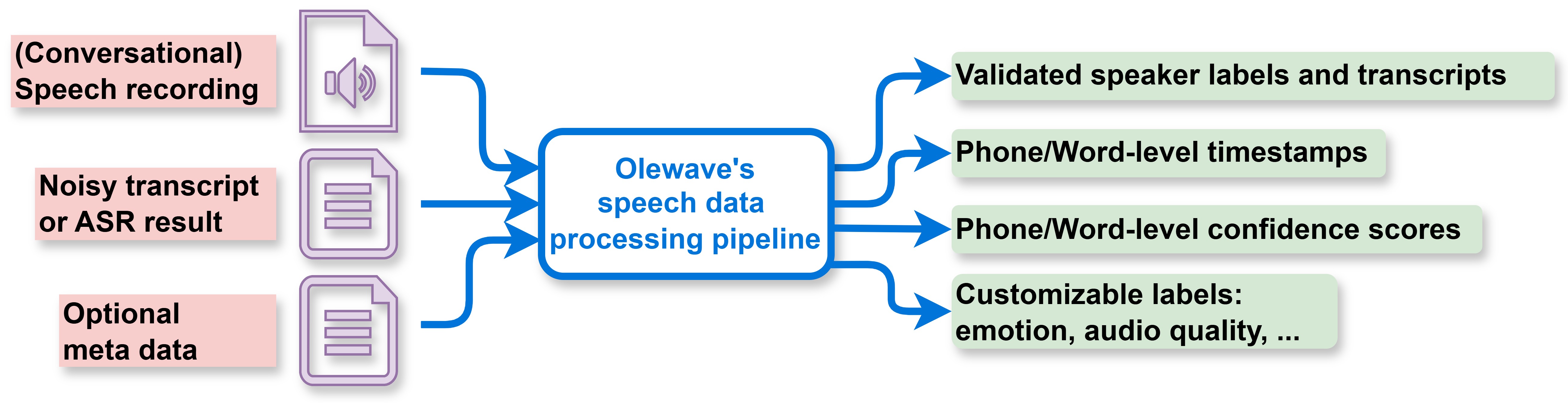
技术框架:OleSpeech-IV的构建流程主要包括以下几个阶段:1) 数据收集:从公开渠道收集英语播客、脱口秀、电话会议等会话语音数据。2) 人工标注:人工标注说话人姓名、发言轮次和文本转录。3) 自动化处理:利用专有流程对人工标注进行优化,并自动生成时间戳和置信度分数等附加信息。4) 数据集构建:将标注信息和音频数据整合,构建OleSpeech-IV数据集。
关键创新:OleSpeech-IV的关键创新在于其数据集的规模、多样性和标注质量。相较于现有数据集,OleSpeech-IV在说话人数量、语种数量和主题覆盖范围上都有显著提升。此外,该数据集结合了人工标注和自动化处理,保证了标注的准确性和信息完整性。
关键设计:数据集包含音频文件、人工标注的说话人信息、发言轮次和文本转录,以及自动生成的时间戳和置信度分数。开源子集OleSpeech-IV-2025-EN-AR-100包含英语和阿拉伯语两种语言,方便研究人员进行多语种语音研究。具体的数据格式和标注规范在论文中应该有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
论文开源了OleSpeech-IV数据集的一个子集OleSpeech-IV-2025-EN-AR-100,包含英语和阿拉伯语两种语言,方便研究人员进行非商业研究。具体的实验结果和性能数据需要在论文中查找(未知),但可以推测,基于该数据集训练的模型在多语种和跨领域场景下应具有更好的泛化能力。
🎯 应用场景
OleSpeech-IV数据集可广泛应用于语音识别、说话人识别、语音合成、语音情感分析等领域。尤其是在多语种和跨领域场景下,该数据集能够为相关研究提供强大的数据支持。此外,该数据集还可以用于开发智能客服、语音助手等应用,提升人机交互的自然性和智能化水平。
📄 摘要(原文)
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.