Sample-efficient Integration of New Modalities into Large Language Models
作者: Osman Batur İnce, André F. T. Martins, Oisin Mac Aodha, Edoardo M. Ponti
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-09-04
备注: Pre-print
💡 一句话要点
提出SEMI方法,高效地将新模态集成到大型语言模型中
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 模态集成 超网络 样本高效学习
📋 核心要点
- 现有方法需要大量配对数据才能将新模态集成到大型语言模型中,这对于低资源模态来说是一个挑战。
- SEMI方法利用超网络学习如何将共享投影器适配到任意模态,仅需少量样本即可完成新模态的集成。
- 实验表明,SEMI在少量样本集成新模态时,显著提高了样本效率,并扩展了基础模型的模态覆盖范围。
📝 摘要(中文)
多模态基础模型能够处理多种模态。然而,由于可能的模态空间巨大且不断发展,从头开始训练一个包含所有模态的模型是不可行的。此外,将模态集成到预先存在的基础模型中,目前需要大量的配对数据,而对于低资源模态来说,这些数据通常是不可用的。本文提出了一种用于将新模态高效集成到大型语言模型(LLM)中的方法,称为样本高效模态集成(SEMI)。为此,我们设计了一个超网络,它可以将共享投影器(位于模态特定编码器和LLM之间)适配到任何模态。该超网络在高资源模态(即文本、语音、音频、视频)上进行训练,并在推理时以任意模态的少量样本为条件,以生成合适的适配器。为了增加训练模态的多样性,我们通过等距变换人为地增加编码器的数量。我们发现,SEMI在少量样本集成新模态(即卫星图像、天文图像、惯性测量和分子)时,实现了样本效率的显著提升,且编码器的嵌入维度是任意的。例如,为了达到与32-shot SEMI相同的精度,从头开始训练投影器需要多64倍的数据。因此,SEMI有望扩展基础模型的模态覆盖范围。
🔬 方法详解
问题定义:论文旨在解决将新的、低资源模态高效地集成到预训练的大型语言模型中的问题。现有方法通常需要大量配对数据来训练模态特定的投影层,这对于数据稀缺的模态来说是不可行的。此外,从头开始训练包含所有模态的大型模型成本过高。
核心思路:论文的核心思想是利用一个超网络来生成模态特定的适配器,该适配器可以将模态编码器的输出投影到LLM的嵌入空间。超网络在高资源模态上进行训练,学习如何根据少量新模态的样本来调整适配器参数。这种方法允许模型在不需要大量训练数据的情况下快速适应新的模态。
技术框架:SEMI框架包含以下几个主要模块:1) 模态特定的编码器,用于将输入模态转换为嵌入向量;2) 一个共享的投影器,用于将编码器的输出投影到LLM的嵌入空间;3) 一个超网络,用于生成模态特定的适配器,该适配器用于调整共享投影器的参数;4) 一个预训练的大型语言模型。训练过程分为两个阶段:首先,在高资源模态上训练超网络;然后,在少量新模态的样本上微调适配器。
关键创新:SEMI的关键创新在于使用超网络来生成模态特定的适配器。与直接训练模态特定的投影层相比,这种方法可以显著提高样本效率,因为超网络已经学习了如何将不同模态的嵌入映射到LLM的嵌入空间。此外,论文还提出了一种通过等距变换来增加训练模态多样性的方法,进一步提高了模型的泛化能力。
关键设计:超网络以少量新模态的样本作为输入,并输出适配器的参数。适配器可以是一个简单的线性层或更复杂的神经网络。损失函数通常包括一个重构损失,用于确保适配器能够准确地将模态嵌入映射到LLM的嵌入空间,以及一个正则化项,用于防止过拟合。等距变换用于生成新的、虚拟的模态,从而增加训练数据的多样性。
🖼️ 关键图片
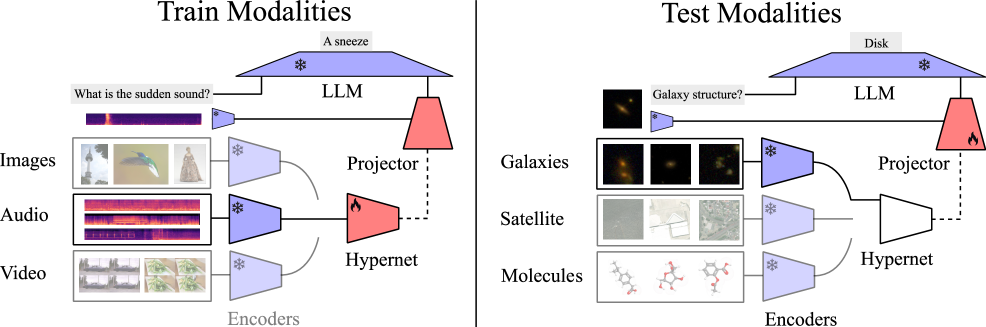


📊 实验亮点
实验结果表明,SEMI在少量样本集成新模态时,显著提高了样本效率。例如,为了达到与32-shot SEMI相同的精度,从头开始训练投影器需要多64倍的数据。SEMI在卫星图像、天文图像、惯性测量和分子等多种模态上都取得了良好的效果,证明了其泛化能力。这些结果表明,SEMI是一种有前景的模态集成方法。
🎯 应用场景
SEMI方法具有广泛的应用前景,例如可以用于集成来自各种传感器的数据,如卫星图像、医疗图像、生物信号等。该方法可以帮助构建更加通用和智能的多模态系统,例如可以用于开发能够理解多种模态信息的智能助手、自动驾驶系统和医疗诊断系统。此外,SEMI方法还可以用于低资源语言的机器翻译和跨模态检索等任务。
📄 摘要(原文)
Multimodal foundation models can process several modalities. However, since the space of possible modalities is large and evolving over time, training a model from scratch to encompass all modalities is unfeasible. Moreover, integrating a modality into a pre-existing foundation model currently requires a significant amount of paired data, which is often not available for low-resource modalities. In this paper, we introduce a method for sample-efficient modality integration (SEMI) into Large Language Models (LLMs). To this end, we devise a hypernetwork that can adapt a shared projector -- placed between modality-specific encoders and an LLM -- to any modality. The hypernetwork, trained on high-resource modalities (i.e., text, speech, audio, video), is conditioned on a few samples from any arbitrary modality at inference time to generate a suitable adapter. To increase the diversity of training modalities, we artificially multiply the number of encoders through isometric transformations. We find that SEMI achieves a significant boost in sample efficiency during few-shot integration of new modalities (i.e., satellite images, astronomical images, inertial measurements, and molecules) with encoders of arbitrary embedding dimensionality. For instance, to reach the same accuracy as 32-shot SEMI, training the projector from scratch needs 64$\times$ more data. As a result, SEMI holds promise to extend the modality coverage of foundation models.