Spoken in Jest, Detected in Earnest: A Systematic Review of Sarcasm Recognition -- Multimodal Fusion, Challenges, and Future Prospects
作者: Xiyuan Gao, Shekhar Nayak, Matt Coler
分类: cs.CL
发布日期: 2025-09-04
备注: 20 pages, 7 figures, Submitted to IEEE Transactions on Affective Computing
💡 一句话要点
系统性回顾语音讽刺识别:多模态融合、挑战与未来展望
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音讽刺识别 多模态融合 情感计算 人机交互 系统性综述
📋 核心要点
- 现有讽刺检测主要集中于文本,忽略了语音韵律等重要线索,限制了识别的准确性和鲁棒性。
- 该研究系统性回顾了语音讽刺识别,从单模态到多模态方法,分析了数据集、特征提取和分类的演进。
- 研究强调了跨文化、多语言讽刺识别的重要性,并指出讽刺是一种多模态现象,需要综合考虑。
📝 摘要(中文)
讽刺是人类交流的常见特征,给人们的互动和人机交互带来了挑战。语言学研究强调了韵律线索,如音高、语速和语调的变化,在传达讽刺意图方面的重要性。虽然之前的工作主要集中在基于文本的讽刺检测上,但语音数据在识别讽刺方面的作用尚未得到充分探索。语音技术的最新进展强调了利用语音数据进行自动讽刺识别日益增长的重要性,这可以增强患有神经退行性疾病的个体的社交互动,并提高机器对复杂人类语言使用的理解,从而实现更细致的互动。本系统综述首次关注基于语音的讽刺识别,概述了从单模态到多模态方法的演变,涵盖了数据集、特征提取和分类方法,旨在弥合不同研究领域的差距。研究结果包括语音讽刺识别数据集的局限性,特征提取技术从传统声学特征到基于深度学习的表示的演变,以及分类方法从单模态方法到多模态融合技术的进步。在此过程中,我们强调需要更加重视跨文化和多语言的讽刺识别,以及将讽刺视为一种多模态现象,而不是基于文本的挑战的重要性。
🔬 方法详解
问题定义:论文旨在解决讽刺识别中语音数据利用不足的问题。现有方法主要依赖文本信息,忽略了语音中的韵律特征(如音高、语速、语调),导致讽刺识别的准确率不高,尤其是在口语交流场景下。此外,现有数据集和方法在跨文化和多语言环境下表现不佳,缺乏通用性。
核心思路:论文的核心思路是系统性地回顾和分析语音讽刺识别领域的研究进展,包括数据集、特征提取方法和分类模型。通过梳理现有研究的优缺点,指出未来研究的方向,即从单模态到多模态融合,并强调跨文化和多语言讽刺识别的重要性。
技术框架:该论文并非提出一种新的技术框架,而是一个系统性的综述。它主要关注以下几个方面:1) 语音讽刺识别的数据集,分析其特点和局限性;2) 特征提取方法,包括传统声学特征和基于深度学习的表示方法;3) 分类模型,从单模态方法到多模态融合技术。论文旨在梳理这些技术的发展脉络,并指出未来的研究方向。
关键创新:该论文的创新之处在于它是首个专注于语音讽刺识别的系统性综述。它弥合了不同研究领域之间的差距,为研究人员提供了一个全面的视角,了解该领域的研究现状和未来发展趋势。论文强调了多模态融合和跨文化、多语言讽刺识别的重要性,为未来的研究提供了指导。
关键设计:由于该论文是综述,因此没有具体的参数设置、损失函数或网络结构等技术细节。论文主要关注的是对现有研究的梳理和分析,并指出未来的研究方向。未来的研究可以考虑使用更先进的深度学习模型,例如Transformer或图神经网络,来提取语音中的韵律特征,并将其与文本信息进行融合。此外,还可以构建更大规模、更多样化的跨文化、多语言讽刺识别数据集。
🖼️ 关键图片
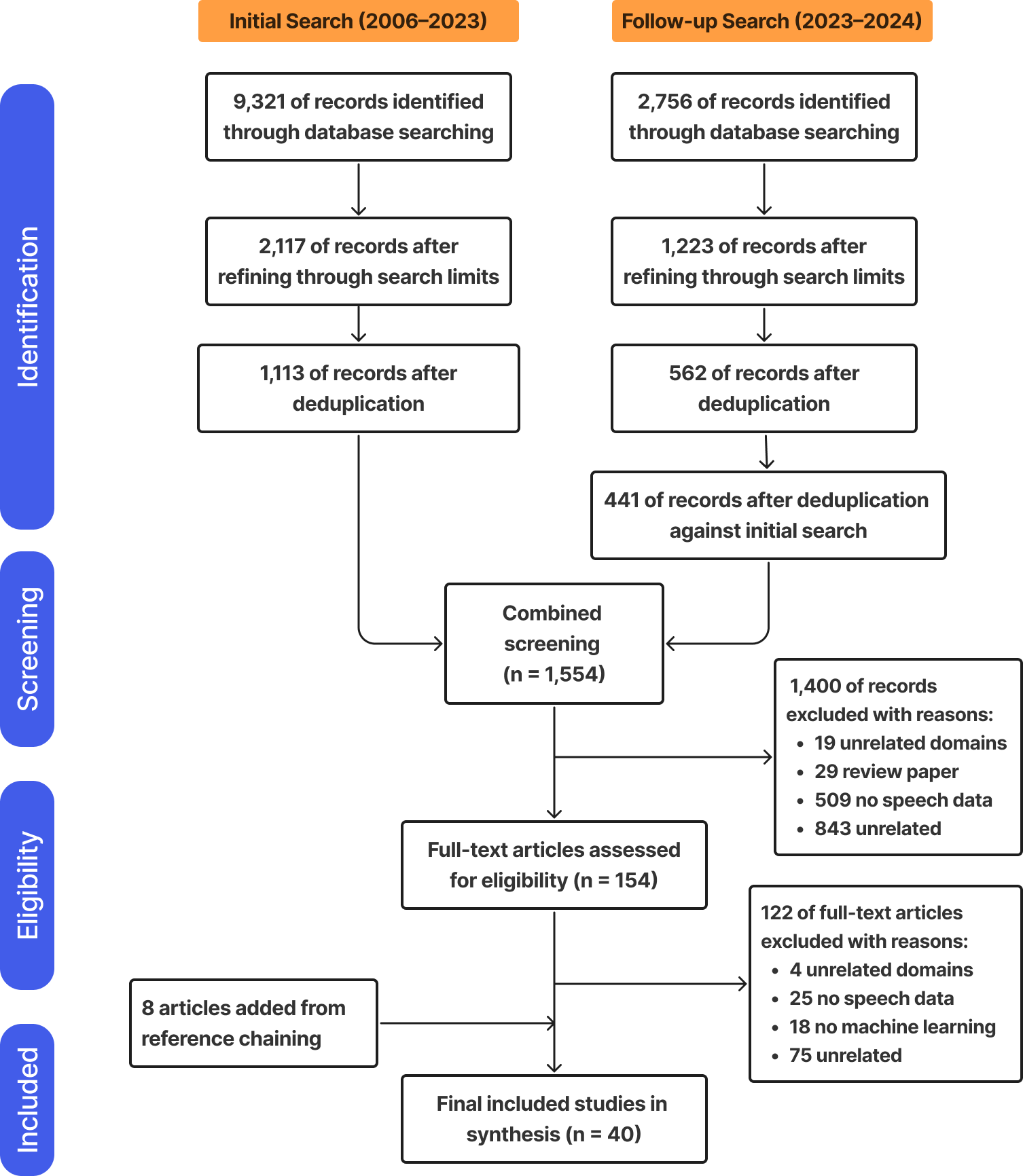
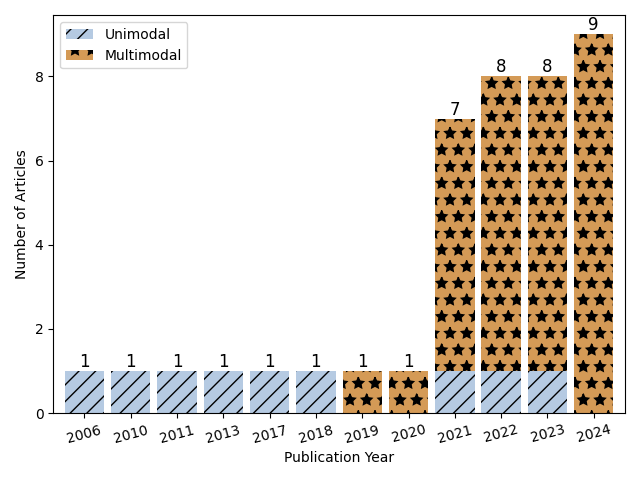
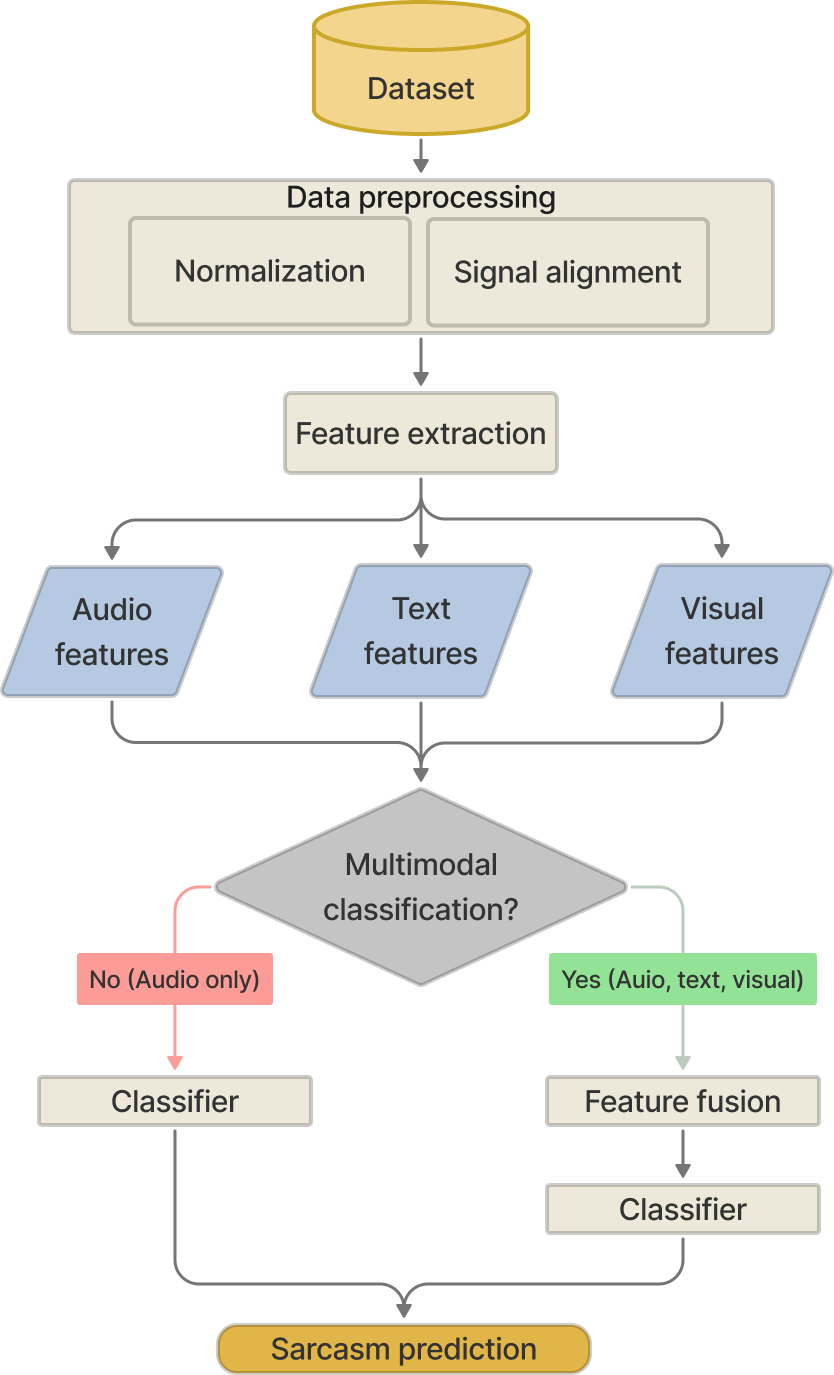
📊 实验亮点
该综述总结了语音讽刺识别领域的研究进展,指出了现有数据集的局限性,并强调了多模态融合和跨文化、多语言讽刺识别的重要性。虽然没有提供具体的性能数据,但该综述为未来的研究提供了重要的指导,并有望推动该领域的发展。
🎯 应用场景
该研究成果可应用于多个领域,如情感计算、人机交互、社交媒体分析等。通过提高机器对讽刺的理解能力,可以改善人机对话系统的自然性和流畅性,增强社交媒体情感分析的准确性,并帮助患有神经退行性疾病的个体更好地理解社交互动。
📄 摘要(原文)
Sarcasm, a common feature of human communication, poses challenges in interpersonal interactions and human-machine interactions. Linguistic research has highlighted the importance of prosodic cues, such as variations in pitch, speaking rate, and intonation, in conveying sarcastic intent. Although previous work has focused on text-based sarcasm detection, the role of speech data in recognizing sarcasm has been underexplored. Recent advancements in speech technology emphasize the growing importance of leveraging speech data for automatic sarcasm recognition, which can enhance social interactions for individuals with neurodegenerative conditions and improve machine understanding of complex human language use, leading to more nuanced interactions. This systematic review is the first to focus on speech-based sarcasm recognition, charting the evolution from unimodal to multimodal approaches. It covers datasets, feature extraction, and classification methods, and aims to bridge gaps across diverse research domains. The findings include limitations in datasets for sarcasm recognition in speech, the evolution of feature extraction techniques from traditional acoustic features to deep learning-based representations, and the progression of classification methods from unimodal approaches to multimodal fusion techniques. In so doing, we identify the need for greater emphasis on cross-cultural and multilingual sarcasm recognition, as well as the importance of addressing sarcasm as a multimodal phenomenon, rather than a text-based challenge.