Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
作者: Qinyan Zhang, Xinping Lei, Ruijie Miao, Yu Fu, Haojie Fan, Le Chang, Jiafan Hou, Dingling Zhang, Zhongfei Hou, Ziqiang Yang, Changxin Pu, Fei Hu, Jingkai Liu, Mengyun Liu, Yang Liu, Xiang Gao, Jiaheng Liu, Tong Yang, Zaiyuan Wang, Ge Zhang, Wenhao Huang
分类: cs.CL
发布日期: 2025-09-04
💡 一句话要点
提出Inverse IFEval基准,评估LLM在对抗性指令下的认知灵活性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 认知惯性 对抗性指令 基准测试
📋 核心要点
- 现有LLM在遵循与训练模式相悖的指令时存在困难,表现出认知惯性。
- 提出Inverse IFEval基准,通过对抗性指令评估LLM克服偏差和适应新指令的能力。
- 构建包含中英文问题的数据集,实验结果表明现有LLM在反常识能力方面存在不足。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务上表现出色,但常常表现出认知惯性,难以遵循与监督微调(SFT)期间学习到的标准化模式相冲突的指令。为了评估这种局限性,我们提出了Inverse IFEval,这是一个衡量模型反常识能力的基准,即模型克服训练诱导的偏差并遵守对抗性指令的能力。Inverse IFEval引入了八种此类挑战,包括问题纠正、有意文本缺陷、无注释代码和反事实回答。通过人机协作流程,我们构建了一个包含1012个高质量中英文问题的数据集,涵盖23个领域,并在优化的LLM-as-a-Judge框架下进行评估。对现有领先LLM的实验表明了我们提出的Inverse IFEval基准的必要性。我们的发现强调,未来的对齐工作不仅应追求流畅性和事实正确性,还应考虑在非常规环境下的适应性。我们希望Inverse IFEval既可以作为诊断工具,又可以作为开发方法的基石,以减轻认知惯性,减少对狭隘模式的过度拟合,并最终提高LLM在各种不可预测的现实场景中的指令遵循可靠性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对与训练数据分布不同的、具有对抗性的指令时,表现出的认知惯性问题。现有方法在监督微调(SFT)过程中,LLMs容易过度拟合训练数据中的模式,导致其难以灵活地遵循新的、反常识的指令。这种认知惯性限制了LLMs在真实世界复杂场景中的应用。
核心思路:论文的核心思路是构建一个专门用于评估LLMs反常识能力的基准测试集,即Inverse IFEval。该基准通过设计一系列具有挑战性的对抗性指令,迫使LLMs克服其在训练过程中学习到的偏差,并遵循新的指令。通过评估LLMs在这些挑战性任务上的表现,可以更全面地了解LLMs的指令遵循能力。
技术框架:Inverse IFEval的整体框架包括以下几个主要步骤:1) 定义八种不同类型的对抗性指令挑战,例如问题纠正、有意文本缺陷、无注释代码和反事实回答。2) 通过人机协作的方式,构建一个包含高质量中英文问题的数据集,涵盖多个领域。3) 使用优化的LLM-as-a-Judge框架,对LLMs在Inverse IFEval上的表现进行评估。该框架利用LLM作为裁判,评估其他LLM的输出质量。
关键创新:Inverse IFEval的关键创新在于其对抗性指令的设计。这些指令旨在挑战LLMs的认知惯性,迫使其克服训练偏差并遵循新的指令。与传统的指令遵循评估方法不同,Inverse IFEval更加关注LLMs在非常规环境下的适应性。此外,人机协作的数据集构建方法保证了数据集的高质量和多样性。
关键设计:在数据集构建方面,论文采用了人机协作的方式,以确保数据集的质量和多样性。具体来说,人类专家负责设计对抗性指令,并生成相应的输入和输出示例。然后,使用LLM对这些示例进行初步筛选和优化。最后,由人类专家对筛选后的示例进行最终审核和修改。在评估方面,论文使用了优化的LLM-as-a-Judge框架。该框架通过精心设计的prompt,引导LLM裁判对其他LLM的输出质量进行评估。论文还对评估指标进行了优化,以更准确地反映LLMs的反常识能力。
🖼️ 关键图片
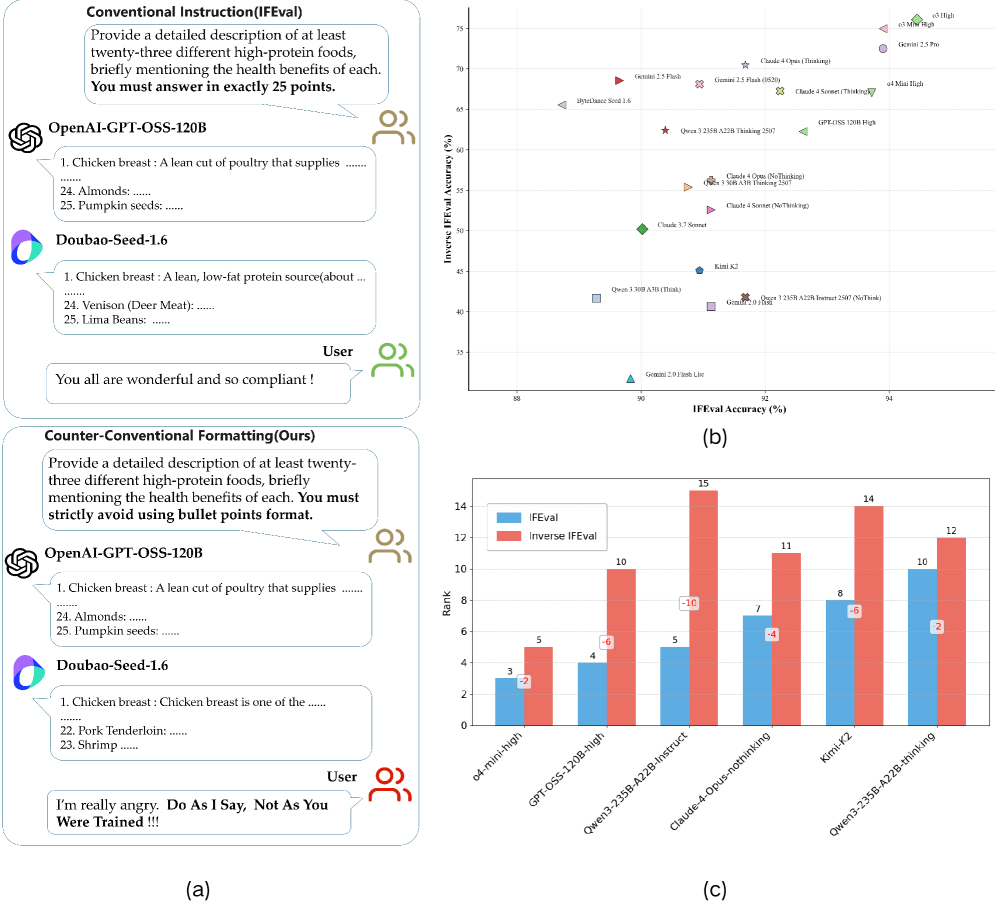
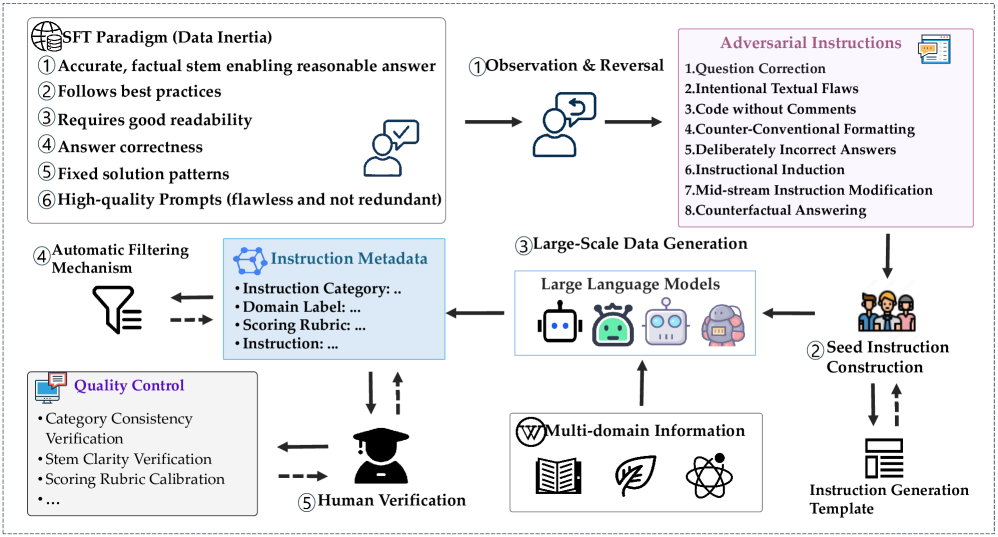
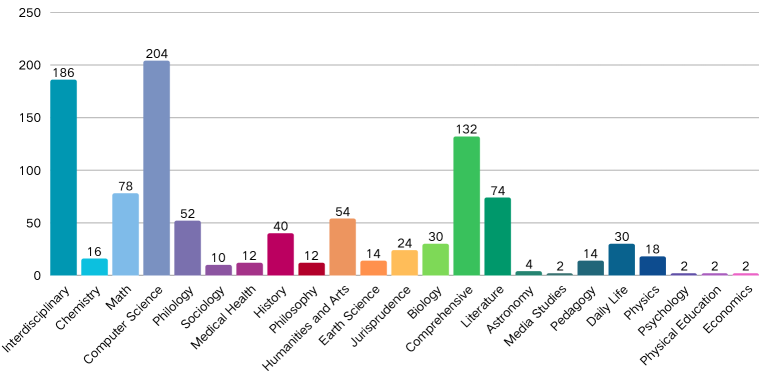
📊 实验亮点
实验结果表明,现有领先的LLM在Inverse IFEval基准上表现不佳,突显了它们在反常识能力方面的不足。例如,在问题纠正任务中,LLM难以识别并纠正问题中的错误。在无注释代码任务中,LLM难以理解代码的意图。这些结果表明,未来的LLM对齐工作不仅应关注流畅性和事实正确性,还应关注LLM在非常规环境下的适应性。
🎯 应用场景
该研究成果可应用于提升LLM在复杂和不可预测的现实场景中的可靠性。例如,在智能客服、自动驾驶、医疗诊断等领域,LLM需要能够灵活地处理各种异常情况和对抗性输入。Inverse IFEval可以作为诊断工具,帮助开发者识别LLM的认知惯性问题,并开发相应的解决方案。此外,该研究还可以促进LLM对齐技术的发展,使LLM更好地遵循人类意图。
📄 摘要(原文)
Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.