Towards Stable and Personalised Profiles for Lexical Alignment in Spoken Human-Agent Dialogue
作者: Keara Schaaij, Roel Boumans, Tibor Bosse, Iris Hendrickx
分类: cs.CL, cs.HC
发布日期: 2025-09-04 (更新: 2025-11-04)
备注: This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in TSD 2025. Lecture Notes in Computer Science, vol 16029
DOI: 10.1007/978-3-032-02548-7_5
💡 一句话要点
构建稳定、个性化的词汇配置文件,为对话Agent实现词汇对齐奠定基础
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 词汇对齐 人机对话 个性化建模 词汇配置文件 语音转录
📋 核心要点
- 现有对话Agent缺乏有效的词汇对齐机制,无法充分利用大型语言模型提升沟通效果。
- 本研究提出构建个性化的词汇配置文件,通过分析用户语音数据,提取代表性词汇。
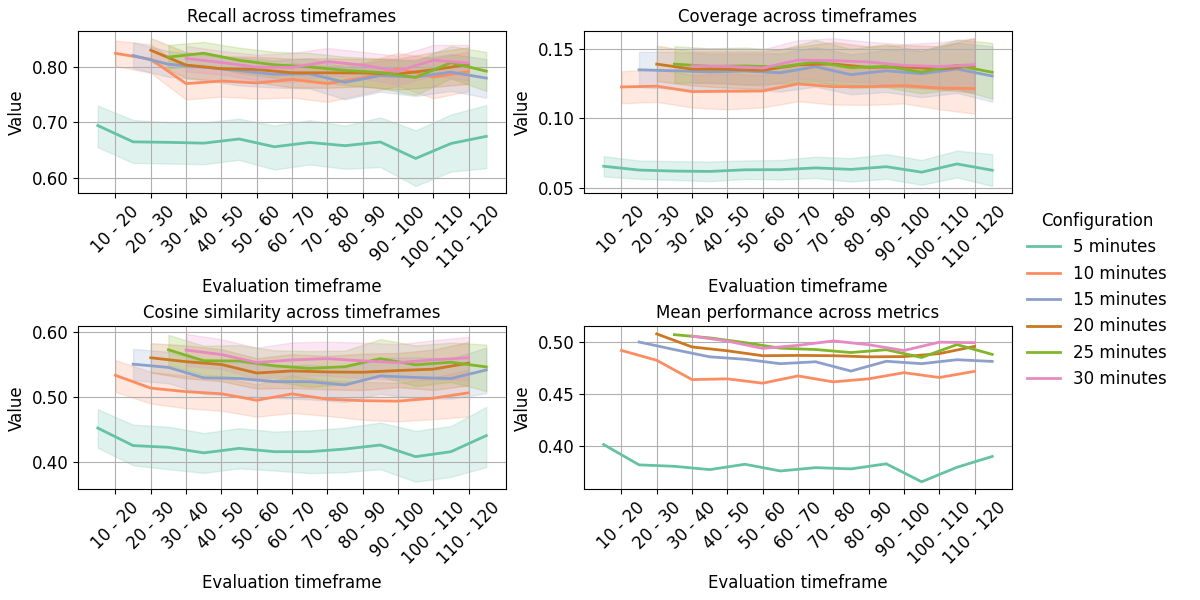
- 实验表明,使用少量数据即可构建稳定且高效的词汇配置文件,为后续词汇对齐策略提供基础。
📝 摘要(中文)
词汇对齐,即对话者在交流中开始使用相似的词语,被认为是成功沟通的关键因素。然而,考虑到大型语言模型(LLMs)的最新进展,其在对话Agent中的应用仍未得到充分探索。本研究旨在通过个性化对话Agent的策略,构建稳定、个性化的词汇配置文件,作为词汇对齐的基础。具体而言,我们改变了用于构建配置文件的转录语音数据的量,以及每个词性(POS)类别中包含的项目数量,并使用召回率、覆盖率和余弦相似度指标评估了配置文件随时间的性能。结果表明,较小且更紧凑的配置文件,在转录10分钟的语音后创建,形容词、连词各包含5个项目,副词、名词、代词和动词各包含10个项目,在性能和数据效率方面提供了最佳平衡。总之,本研究为构建稳定、个性化的词汇配置文件提供了实践见解,同时考虑了最小数据需求,为对话Agent中的词汇对齐策略奠定了基础。
🔬 方法详解
问题定义:论文旨在解决在人机对话中,如何为对话Agent构建稳定且个性化的词汇配置文件,以便后续实现词汇对齐。现有方法缺乏对个性化词汇特征的有效建模,难以适应不同用户的语言习惯。
核心思路:论文的核心思路是通过分析用户的语音数据,提取具有代表性的词汇,并构建个性化的词汇配置文件。通过控制配置文件的大小和词性分布,在数据效率和性能之间取得平衡。这样设计的目的是为了让Agent能够学习用户的语言风格,从而在对话中进行更自然的词汇对齐。
技术框架:整体流程包括:1) 收集用户的语音数据;2) 对语音数据进行转录;3) 对转录文本进行词性标注;4) 根据词性类别,提取高频词汇;5) 构建个性化的词汇配置文件;6) 使用召回率、覆盖率和余弦相似度等指标评估配置文件的性能。
关键创新:论文的关键创新在于探索了构建稳定、个性化词汇配置文件的最佳实践,并量化了不同数据量和词性分布对配置文件性能的影响。与现有方法相比,该研究更注重数据效率和个性化建模,为对话Agent的词汇对齐提供了更实用的解决方案。
关键设计:论文的关键设计包括:1) 探索了不同语音数据量(例如,10分钟、20分钟)对配置文件稳定性的影响;2) 实验了不同词性类别(形容词、连词、副词、名词、代词和动词)的项目数量对配置文件性能的影响;3) 使用召回率、覆盖率和余弦相似度等指标,对配置文件在不同时间段的性能进行评估,以确定最佳的配置文件大小和词性分布。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用10分钟的转录语音数据,并为形容词和连词分别设置5个项目,为副词、名词、代词和动词分别设置10个项目,可以构建出在性能和数据效率之间取得最佳平衡的词汇配置文件。该配置在召回率、覆盖率和余弦相似度等指标上表现良好,证明了其稳定性和有效性。
🎯 应用场景
该研究成果可应用于各种人机对话场景,例如智能客服、虚拟助手和教育机器人。通过实现词汇对齐,可以提高对话的流畅性和自然度,增强用户体验,并促进更有效的沟通。未来,该技术还可以扩展到跨语言对话和多模态对话中。
📄 摘要(原文)
Lexical alignment, where speakers start to use similar words across conversation, is known to contribute to successful communication. However, its implementation in conversational agents remains underexplored, particularly considering the recent advancements in large language models (LLMs). As a first step towards enabling lexical alignment in human-agent dialogue, this study draws on strategies for personalising conversational agents and investigates the construction of stable, personalised lexical profiles as a basis for lexical alignment. Specifically, we varied the amounts of transcribed spoken data used for construction as well as the number of items included in the profiles per part-of-speech (POS) category and evaluated profile performance across time using recall, coverage, and cosine similarity metrics. It was shown that smaller and more compact profiles, created after 10 min of transcribed speech containing 5 items for adjectives, 5 items for conjunctions, and 10 items for adverbs, nouns, pronouns, and verbs each, offered the best balance in both performance and data efficiency. In conclusion, this study offers practical insights into constructing stable, personalised lexical profiles, taking into account minimal data requirements, serving as a foundational step toward lexical alignment strategies in conversational agents.