CANDY: Benchmarking LLMs' Limitations and Assistive Potential in Chinese Misinformation Fact-Checking
作者: Ruiling Guo, Xinwei Yang, Chen Huang, Tong Zhang, Yong Hu
分类: cs.CL, cs.AI
发布日期: 2025-09-04
备注: Findings of EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
CANDY:评估大语言模型在中文虚假信息核查中的局限性与辅助潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 事实核查 中文信息处理 虚假信息检测 基准数据集
📋 核心要点
- 现有大型语言模型在事实核查中的有效性尚不明确,需要系统性的评估和分析。
- CANDY基准旨在评估LLMs在中文虚假信息核查中的能力,并分析其局限性。
- 实验结果表明,LLMs在事实核查中存在局限性,但作为辅助工具具有增强人类表现的潜力。
📝 摘要(中文)
尽管大型语言模型(LLMs)的应用日益广泛,但其在核查虚假信息方面的有效性仍不确定。为此,我们提出了CANDY,一个旨在系统评估LLMs在中文虚假信息核查中的能力和局限性的基准。具体而言,我们精心策划了一个包含约2万个实例的带注释数据集。我们的分析表明,即使通过思维链推理和少样本提示增强,当前的LLMs在生成准确的事实核查结论方面也存在局限性。为了理解这些局限性,我们开发了一种分类法,用于对LLM生成的结论解释中的缺陷进行分类,并发现事实捏造是最常见的失败模式。虽然LLMs单独使用在事实核查方面并不可靠,但我们的研究结果表明,当作为辅助工具部署在场景中时,它们具有相当大的潜力来增强人类的表现。我们的数据集和代码可在https://github.com/SCUNLP/CANDY 访问。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在中文虚假信息核查任务中的能力评估问题。现有方法缺乏针对中文环境的系统性基准测试,无法充分了解LLMs在处理中文虚假信息时的优势与不足。现有的LLM在事实核查中容易出现事实性错误和逻辑推理错误,导致结论不可靠。
核心思路:论文的核心思路是构建一个高质量的中文虚假信息核查基准数据集CANDY,并基于该数据集系统性地评估LLMs在事实核查任务中的表现。通过对LLM生成结果的错误类型进行分类,深入分析其局限性,并探索LLM作为辅助工具在事实核查中的潜力。
技术框架:CANDY基准测试框架主要包含以下几个阶段:1) 数据集构建:收集并标注约2万个中文虚假信息实例,构建高质量的基准数据集。2) 模型评估:使用不同的LLMs(例如,GPT-3, ChatGPT)在CANDY数据集上进行测试,评估其事实核查能力。3) 错误分析:对LLM生成的结果进行错误类型分类,例如事实捏造、逻辑错误等,分析其局限性。4) 辅助工具探索:研究LLM作为辅助工具在事实核查中的应用,例如辅助人类专家进行信息筛选和证据检索。
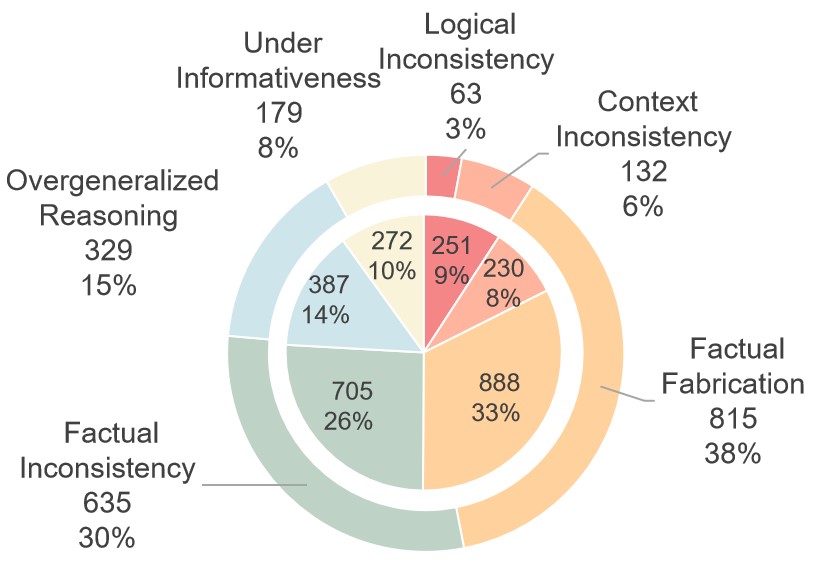
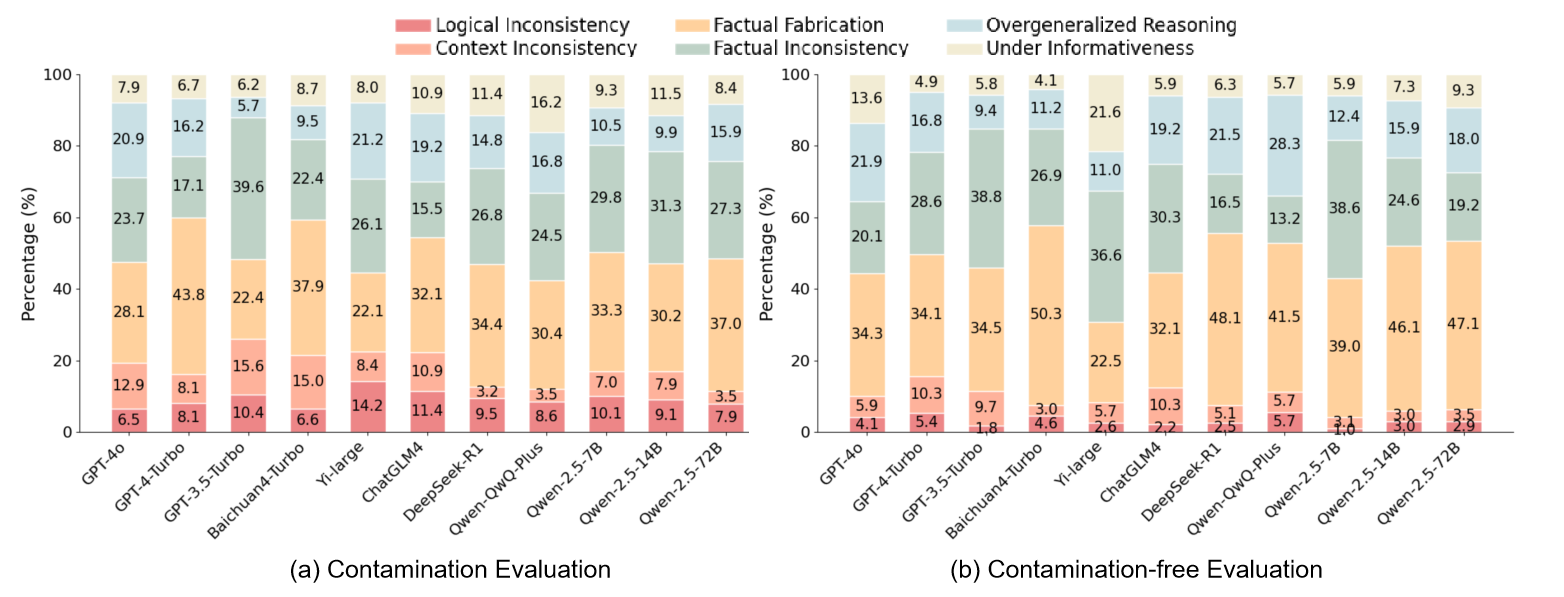
关键创新:论文的关键创新在于构建了一个大规模、高质量的中文虚假信息核查基准数据集CANDY。该数据集的构建和标注过程经过精心设计,能够有效评估LLMs在中文环境下的事实核查能力。此外,论文还提出了一个错误分类体系,用于分析LLM生成结果中的缺陷,为改进LLM的事实核查能力提供了指导。
关键设计:CANDY数据集包含多种类型的中文虚假信息,例如谣言、伪科学、政治宣传等。数据集的标注包括信息真实性标签、证据来源、以及详细的解释。在模型评估方面,论文采用了多种评估指标,例如准确率、召回率、F1值等。此外,论文还探索了不同的提示策略(例如,思维链提示、少样本提示)对LLM性能的影响。
🖼️ 关键图片
📊 实验亮点
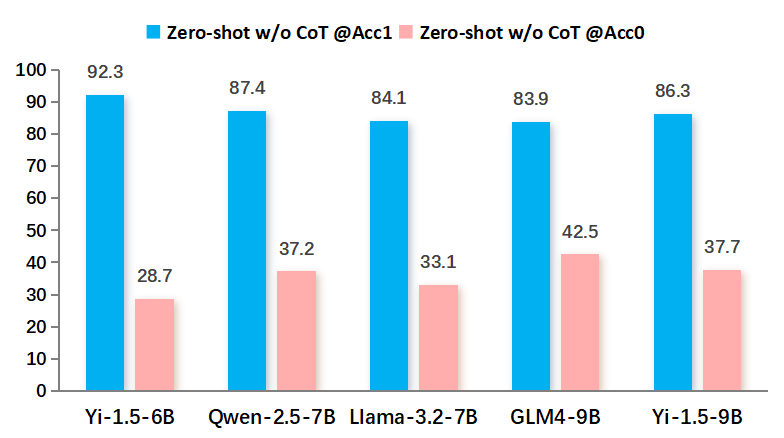
实验结果表明,即使采用思维链和少样本提示,现有LLMs在CANDY数据集上的事实核查准确率仍然有限,表明其在中文虚假信息核查方面存在显著局限性。错误分析显示,事实捏造是LLMs最常见的错误类型。然而,研究也发现LLMs在辅助人类进行事实核查方面具有潜力。
🎯 应用场景
该研究成果可应用于提升中文互联网内容安全,辅助新闻媒体进行事实核查,减少虚假信息传播。通过将LLM作为辅助工具,可以提高人工核查效率,降低人工成本。未来,该研究可进一步扩展到其他语言和文化背景,构建更通用的虚假信息核查系统。
📄 摘要(原文)
The effectiveness of large language models (LLMs) to fact-check misinformation remains uncertain, despite their growing use. To this end, we present CANDY, a benchmark designed to systematically evaluate the capabilities and limitations of LLMs in fact-checking Chinese misinformation. Specifically, we curate a carefully annotated dataset of ~20k instances. Our analysis shows that current LLMs exhibit limitations in generating accurate fact-checking conclusions, even when enhanced with chain-of-thought reasoning and few-shot prompting. To understand these limitations, we develop a taxonomy to categorize flawed LLM-generated explanations for their conclusions and identify factual fabrication as the most common failure mode. Although LLMs alone are unreliable for fact-checking, our findings indicate their considerable potential to augment human performance when deployed as assistive tools in scenarios. Our dataset and code can be accessed at https://github.com/SCUNLP/CANDY