VoxRole: A Comprehensive Benchmark for Evaluating Speech-Based Role-Playing Agents
作者: Weihao Wu, Liang Cao, Xinyu Wu, Zhiwei Lin, Rui Niu, Jingbei Li, Zhiyong Wu
分类: cs.CL, cs.AI, cs.SD
发布日期: 2025-09-04
💡 一句话要点
提出VoxRole:用于评估语音角色扮演代理的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音角色扮演 对话代理 评估基准 大型语言模型 角色一致性
📋 核心要点
- 现有角色扮演对话代理研究主要集中于文本模态,忽略了语音中重要的超语言特征,限制了角色情感和身份的表达。
- 论文提出VoxRole基准,包含大量电影语音数据和角色信息,旨在全面评估语音角色扮演代理在角色一致性等方面的能力。
- 通过VoxRole对现有口语对话模型进行评估,揭示了模型在角色一致性方面的优势和不足,为未来研究提供重要参考。
📝 摘要(中文)
大型语言模型(LLMs)的显著进步极大地推动了角色扮演对话代理(RPCAs)的发展。这些系统旨在通过一致的角色扮演来创造沉浸式的用户体验。然而,当前RPCA研究面临双重局限性。首先,现有工作主要集中在文本模态,完全忽略了语音中关键的超语言特征,包括语调、韵律和节奏,这些特征对于传达角色情感和塑造生动身份至关重要。其次,基于语音的角色扮演领域长期缺乏标准化的评估基准。目前大多数口语对话数据集仅针对基本能力评估,其角色设定粗略或定义不清。因此,它们无法有效量化模型在长期角色一致性等核心能力上的表现。为了解决这一关键差距,我们推出了VoxRole,这是第一个专门为评估基于语音的RPCAs而设计的综合基准。该基准包含13335个多轮对话,总计65.6小时的语音,来自261部电影中的1228个独特角色。为了构建这一资源,我们提出了一种新颖的两阶段自动化流程,该流程首先将电影音频与剧本对齐,然后利用LLM系统地构建每个角色的多维配置文件。利用VoxRole,我们对当代口语对话模型进行了多维度评估,揭示了它们在保持角色一致性方面的优势和局限性。
🔬 方法详解
问题定义:现有角色扮演对话代理(RPCA)的研究主要集中在文本模态,忽略了语音中的语调、韵律等超语言特征,导致角色情感和身份表达不足。同时,缺乏专门针对语音RPCA的标准化评估基准,难以有效评估模型在角色一致性等方面的能力。
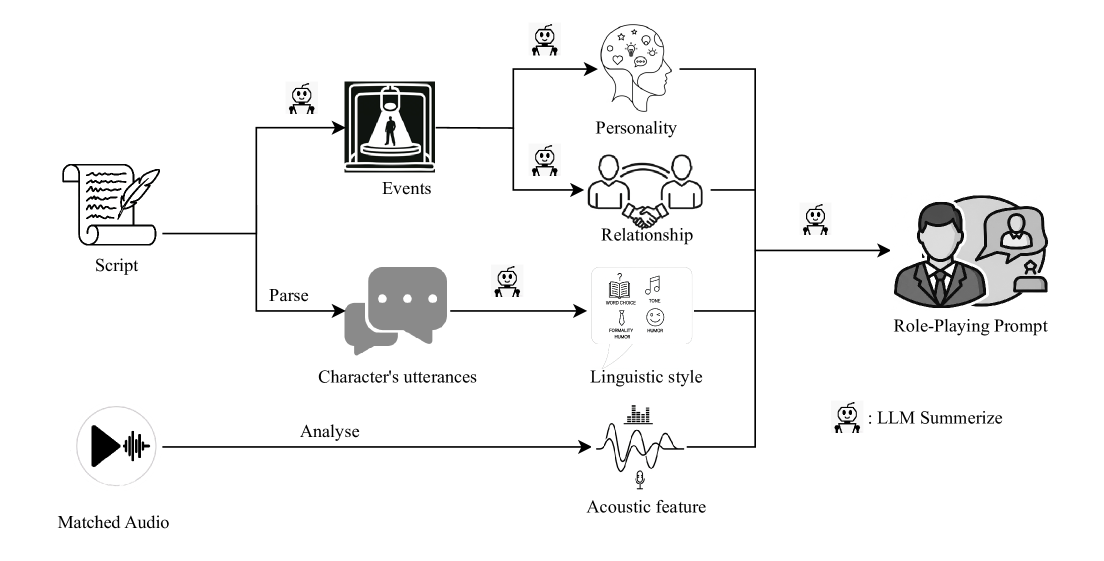
核心思路:论文的核心思路是构建一个包含大量电影语音数据和角色信息的综合基准VoxRole,用于全面评估语音RPCA。通过对电影音频和剧本进行对齐,并利用大型语言模型(LLM)构建角色的多维配置文件,从而为模型评估提供更丰富的信息。
技术框架:VoxRole的构建包含两个主要阶段:1) 电影音频与剧本对齐:使用自动化流程将电影音频与剧本进行精确对齐,提取角色语音片段。2) 角色配置文件构建:利用LLM分析剧本和语音内容,构建角色的多维配置文件,包括性格、背景、目标等信息。最终,VoxRole包含13335个多轮对话,总计65.6小时的语音,来自261部电影中的1228个独特角色。
关键创新:该论文的关键创新在于提出了一个专门针对语音角色扮演代理的综合评估基准VoxRole,填补了该领域缺乏标准化评估资源的空白。此外,论文提出的两阶段自动化流程能够高效地构建大规模的角色配置文件,降低了人工标注的成本。
关键设计:在电影音频与剧本对齐阶段,采用了基于语音识别和文本匹配的算法,以确保对齐的准确性。在角色配置文件构建阶段,利用LLM进行文本分析和信息抽取,并设计了多维的角色属性表示方法,以全面描述角色的特征。
🖼️ 关键图片


📊 实验亮点
论文构建了包含13335个多轮对话,总计65.6小时语音的VoxRole基准,涵盖261部电影中的1228个独特角色。通过对现有口语对话模型进行评估,发现模型在角色一致性方面存在不足,为未来研究提供了改进方向。例如,部分模型在长期对话中难以保持角色性格的一致性,表明需要进一步提升模型的记忆能力和角色理解能力。
🎯 应用场景
VoxRole基准的推出,将促进语音角色扮演代理的研究和发展,可应用于智能客服、虚拟助手、游戏角色等领域。通过使用VoxRole进行模型评估和优化,可以提升语音RPCA的角色一致性和情感表达能力,从而创造更具沉浸感和个性化的用户体验。未来,VoxRole可以扩展到更多领域,例如教育、医疗等,为用户提供更智能、更人性化的服务。
📄 摘要(原文)
Recent significant advancements in Large Language Models (LLMs) have greatly propelled the development of Role-Playing Conversational Agents (RPCAs). These systems aim to create immersive user experiences through consistent persona adoption. However, current RPCA research faces dual limitations. First, existing work predominantly focuses on the textual modality, entirely overlooking critical paralinguistic features including intonation, prosody, and rhythm in speech, which are essential for conveying character emotions and shaping vivid identities. Second, the speech-based role-playing domain suffers from a long-standing lack of standardized evaluation benchmarks. Most current spoken dialogue datasets target only fundamental capability assessments, featuring thinly sketched or ill-defined character profiles. Consequently, they fail to effectively quantify model performance on core competencies like long-term persona consistency. To address this critical gap, we introduce VoxRole, the first comprehensive benchmark specifically designed for the evaluation of speech-based RPCAs. The benchmark comprises 13335 multi-turn dialogues, totaling 65.6 hours of speech from 1228 unique characters across 261 movies. To construct this resource, we propose a novel two-stage automated pipeline that first aligns movie audio with scripts and subsequently employs an LLM to systematically build multi-dimensional profiles for each character. Leveraging VoxRole, we conduct a multi-dimensional evaluation of contemporary spoken dialogue models, revealing crucial insights into their respective strengths and limitations in maintaining persona consistency.