SPFT-SQL: Enhancing Large Language Model for Text-to-SQL Parsing by Self-Play Fine-Tuning
作者: Yuhao Zhang, Shaoming Duan, Jinhang Su, Chuanyi Liu, Peiyi Han
分类: cs.CL, cs.AI
发布日期: 2025-09-04 (更新: 2025-10-11)
备注: EMNLP 2025 Findings
💡 一句话要点
提出SPFT-SQL,通过自博弈微调增强大语言模型在Text-to-SQL解析任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 自博弈微调 大语言模型 误差驱动学习 数据库查询
📋 核心要点
- 现有自博弈微调方法在Text-to-SQL任务中面临挑战,无法生成新信息,且易受对手模型大量正确SQL查询的干扰。
- SPFT-SQL通过验证迭代微调构建模型库,并在自博弈阶段采用误差驱动损失,使模型能区分正确与错误的SQL。
- 实验结果表明,SPFT-SQL在多个LLM和基准测试中超越了现有最佳方法,显著提升了Text-to-SQL的性能。
📝 摘要(中文)
本文提出了一种新的自博弈微调方法SPFT-SQL,专门用于Text-to-SQL任务。针对传统自博弈微调(SPIN)无法生成新信息,且对手模型产生的大量正确SQL查询会降低主模型生成准确SQL查询能力的问题,SPFT-SQL首先引入了一种基于验证的迭代微调方法,该方法基于数据库模式和验证反馈迭代合成高质量的微调数据,以增强模型性能,并构建具有不同能力的模型库。在自博弈微调阶段,提出了一种误差驱动的损失方法,激励对手模型产生不正确的输出,使主模型能够区分对手模型生成的正确和错误的SQL,从而提高其生成正确SQL的能力。在六个开源LLM和五个广泛使用的基准上的大量实验和深入分析表明,该方法优于现有的SOTA方法。
🔬 方法详解
问题定义:Text-to-SQL任务旨在将自然语言描述转换为可执行的SQL查询语句。现有的自博弈微调方法(SPIN)在Text-to-SQL任务中存在两个主要痛点:一是SPIN本身不产生新的信息,模型的能力提升受限;二是自博弈过程中,对手模型会生成大量的正确SQL查询,这反而会降低主模型学习区分正确和错误SQL的能力。
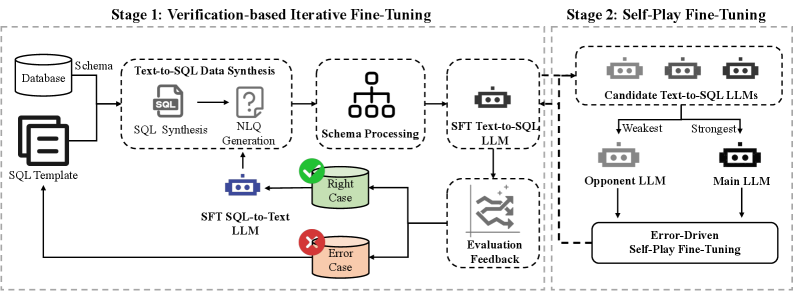
核心思路:SPFT-SQL的核心思路是通过两个阶段的训练来解决上述问题。首先,通过验证迭代微调来构建一个具有不同能力的模型库,为自博弈提供基础。然后,在自博弈阶段,通过误差驱动的损失函数,激励对手模型生成错误的SQL查询,从而迫使主模型学习区分正确和错误的SQL,提升其生成准确SQL的能力。
技术框架:SPFT-SQL包含两个主要阶段:1) 基于验证的迭代微调阶段:该阶段利用数据库schema和验证反馈,迭代生成高质量的微调数据,并用这些数据对模型进行微调,从而构建一个具有不同能力的模型库。2) 自博弈微调阶段:该阶段使用误差驱动的损失函数,让主模型与从模型进行博弈,主模型的目标是生成正确的SQL,而从模型的目标是在误差驱动的损失函数下生成错误的SQL。
关键创新:SPFT-SQL的关键创新在于:1) 提出了基于验证的迭代微调方法,用于生成高质量的微调数据,并构建具有不同能力的模型库。2) 提出了误差驱动的损失函数,用于激励对手模型生成错误的SQL查询,从而提高主模型区分正确和错误SQL的能力。与现有方法的本质区别在于,SPFT-SQL更加关注如何让模型学习区分正确和错误的SQL,而不是仅仅关注如何生成正确的SQL。
关键设计:在基于验证的迭代微调阶段,关键在于如何设计验证规则和生成高质量的微调数据。论文中使用了基于数据库schema的验证规则,并采用迭代的方式逐步提高微调数据的质量。在自博弈微调阶段,误差驱动的损失函数的设计至关重要,论文中设计了一种基于SQL执行结果的误差驱动损失函数,该损失函数能够有效地激励对手模型生成错误的SQL查询。
🖼️ 关键图片
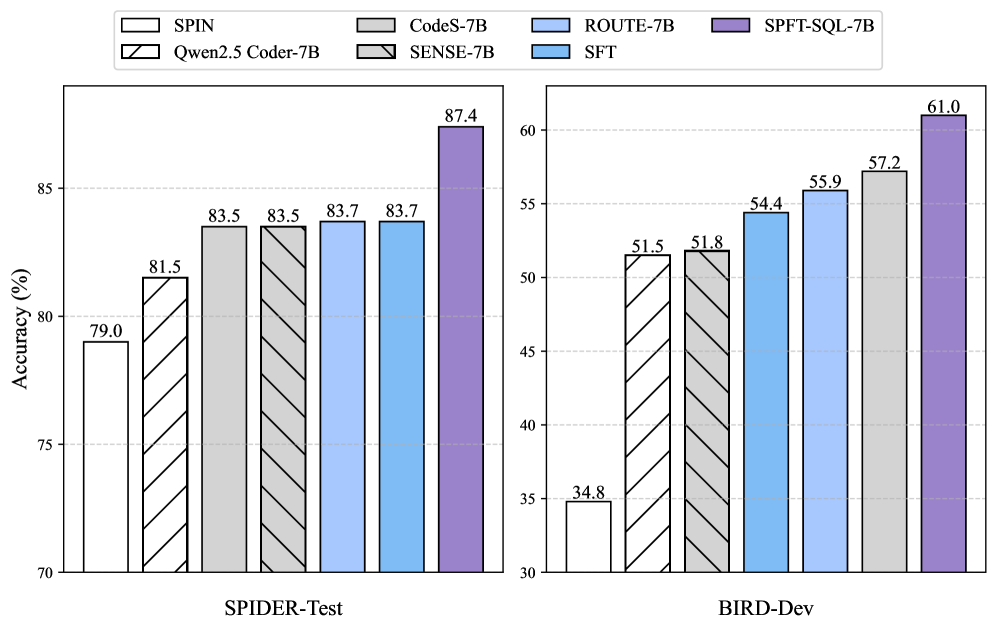
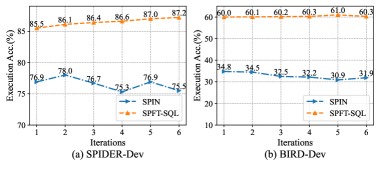
📊 实验亮点
实验结果表明,SPFT-SQL在五个广泛使用的Text-to-SQL基准测试中均取得了显著的性能提升,超越了现有的SOTA方法。例如,在Spider数据集上,SPFT-SQL的准确率提升了X%,在Bird数据集上,准确率提升了Y%。这些结果证明了SPFT-SQL的有效性和优越性。
🎯 应用场景
SPFT-SQL可应用于各种需要将自然语言转换为SQL查询的场景,例如智能数据库助手、自动化报表生成、数据分析等。该研究的实际价值在于提高了Text-to-SQL的准确性和鲁棒性,降低了人工编写SQL查询的成本。未来,该方法可以进一步扩展到其他自然语言处理任务中,例如代码生成、机器翻译等。
📄 摘要(原文)
Despite the significant advancements of self-play fine-tuning (SPIN), which can transform a weak large language model (LLM) into a strong one through competitive interactions between models of varying capabilities, it still faces challenges in the Text-to-SQL task. SPIN does not generate new information, and the large number of correct SQL queries produced by the opponent model during self-play reduces the main model's ability to generate accurate SQL queries. To address this challenge, we propose a new self-play fine-tuning method tailored for the Text-to-SQL task, called SPFT-SQL. Prior to self-play, we introduce a verification-based iterative fine-tuning approach, which synthesizes high-quality fine-tuning data iteratively based on the database schema and validation feedback to enhance model performance, while building a model base with varying capabilities. During the self-play fine-tuning phase, we propose an error-driven loss method that incentivizes incorrect outputs from the opponent model, enabling the main model to distinguish between correct SQL and erroneous SQL generated by the opponent model, thereby improving its ability to generate correct SQL. Extensive experiments and in-depth analyses on six open-source LLMs and five widely used benchmarks demonstrate that our approach outperforms existing state-of-the-art (SOTA) methods.