False Sense of Security: Why Probing-based Malicious Input Detection Fails to Generalize
作者: Cheng Wang, Zeming Wei, Qin Liu, Muhao Chen
分类: cs.CL
发布日期: 2025-09-04 (更新: 2025-12-15)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示基于探针的恶意输入检测方法泛化性不足的根本原因
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 恶意输入检测 探针方法 泛化能力 表面模式
📋 核心要点
- 现有基于探针的恶意输入检测方法在泛化性上存在不足,无法有效识别分布外的恶意输入。
- 论文提出探针学习的是输入中的表面模式(如指令模式和触发词),而非真正的语义有害性。
- 通过一系列受控实验,验证了探针方法对表面模式的依赖性,并分析了其失效的原因。
📝 摘要(中文)
大型语言模型(LLMs)可能执行有害指令,这引发了严重的安全问题,尽管它们的能力令人印象深刻。最近的研究利用基于探针的方法来研究LLMs内部表示中恶意和良性输入的可分离性,并且研究人员已经提出使用这种探针方法进行安全检测。我们系统地重新审视了这种范式。受分布外性能不佳的启发,我们假设探针学习的是表面模式而不是语义上的有害性。通过受控实验,我们证实了这一假设,并确定了所学习的特定模式:指令模式和触发词。我们的研究遵循一种系统的方法,从展示简单的n-gram方法的可比性能,到使用语义清理的数据集进行受控实验,再到对模式依赖性的详细分析。这些结果揭示了当前基于探针的方法存在一种虚假的安全感,并强调需要重新设计模型和评估协议,为此我们提供了进一步的讨论,希望为该方向的负责任的进一步研究提供建议。我们已经在https://github.com/WangCheng0116/Why-Probe-Fails上开源了该项目。
🔬 方法详解
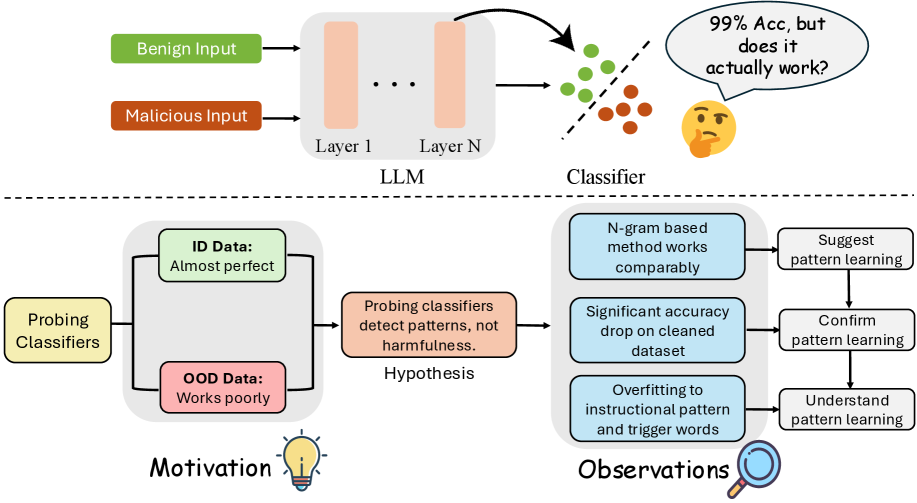
问题定义:现有基于探针的恶意输入检测方法旨在通过训练分类器(探针)区分LLM内部表示中良性和恶意输入。然而,这些方法在面对分布外的恶意输入时,性能显著下降,表明其泛化能力不足。现有方法的痛点在于,它们可能过度拟合训练数据中的表面模式,而未能真正理解语义上的有害性。
核心思路:论文的核心思路是,探针学习的并非是输入的语义有害性,而是输入中的表面模式,例如特定的指令模式或触发词。因此,即使输入在语义上是无害的,但如果包含这些表面模式,探针也可能将其错误地分类为恶意输入。反之亦然。
技术框架:论文采用了一种系统性的实验方法来验证其假设。首先,通过简单的n-gram方法来模拟探针的性能,表明即使不使用复杂的模型,也能达到与探针相当的检测效果。其次,通过构建语义清理的数据集,移除输入中的表面模式,观察探针的性能变化。最后,通过详细的模式依赖性分析,揭示探针所学习的具体模式以及这些模式对检测结果的影响。
关键创新:论文最重要的技术创新点在于,它揭示了基于探针的恶意输入检测方法存在一种虚假的安全感。这些方法看似有效,但实际上只是学习了输入中的表面模式,而未能真正理解语义上的有害性。这种发现对未来的安全检测方法的设计具有重要的指导意义。
关键设计:论文的关键设计在于其受控实验。通过构建语义清理的数据集,论文能够有效地隔离表面模式和语义有害性,从而验证探针对表面模式的依赖性。此外,论文还通过详细的模式依赖性分析,揭示了探针所学习的具体模式,例如特定的指令模式和触发词。
🖼️ 关键图片

📊 实验亮点
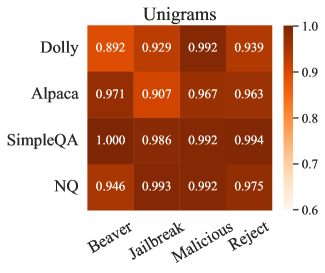
论文通过实验证明,简单的n-gram方法可以达到与复杂的基于探针的方法相当的性能。在语义清理的数据集上,探针的性能显著下降,表明其对表面模式的依赖性。模式依赖性分析揭示了探针所学习的具体模式,例如特定的指令模式和触发词。
🎯 应用场景
该研究成果对提升大型语言模型的安全性具有重要意义。通过理解现有检测方法的局限性,可以指导研究人员设计更鲁棒、更可靠的恶意输入检测方法。这些方法可以应用于各种场景,例如内容审核、安全防护等,以减少LLM被恶意利用的风险。
📄 摘要(原文)
Large Language Models (LLMs) can comply with harmful instructions, raising serious safety concerns despite their impressive capabilities. Recent work has leveraged probing-based approaches to study the separability of malicious and benign inputs in LLMs' internal representations, and researchers have proposed using such probing methods for safety detection. We systematically re-examine this paradigm. Motivated by poor out-of-distribution performance, we hypothesize that probes learn superficial patterns rather than semantic harmfulness. Through controlled experiments, we confirm this hypothesis and identify the specific patterns learned: instructional patterns and trigger words. Our investigation follows a systematic approach, progressing from demonstrating comparable performance of simple n-gram methods, to controlled experiments with semantically cleaned datasets, to detailed analysis of pattern dependencies. These results reveal a false sense of security around current probing-based approaches and highlight the need to redesign both models and evaluation protocols, for which we provide further discussions in the hope of suggesting responsible further research in this direction. We have open-sourced the project at https://github.com/WangCheng0116/Why-Probe-Fails.