Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth
作者: Yang Wang, Chenghao Xiao, Chia-Yi Hsiao, Zi Yan Chang, Chi-Li Chen, Tyler Loakman, Chenghua Lin
分类: cs.CL
发布日期: 2025-09-04 (更新: 2025-10-16)
备注: Accepted for oral presentation at the EMNLP 2025 Main Conference
💡 一句话要点
Drivel-ology:构建多语言“深度胡说”数据集,挑战LLM的语用理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语用理解 深度语义 多语言数据集 自然语言处理
📋 核心要点
- 现有大型语言模型在理解具有隐含意义和语用深度的文本方面存在不足,容易将其与浅层胡说混淆。
- 论文提出Drivelology概念,即“具有深度的胡说”,并构建多语言数据集来评估和挑战LLM的语用理解能力。
- 实验结果表明,LLM在分类、生成和推理任务中,对Drivelology文本的理解存在明显局限性,无法捕捉其深层语义。
📝 摘要(中文)
本文提出了Drivelology,一种独特的语言现象,其特征是“具有深度的胡说”——这些话语在句法上连贯,但在语用上自相矛盾、情感色彩浓厚或具有修辞颠覆性。虽然这些表达可能类似于表面上的胡说,但它们编码了需要上下文推断、道德推理或情感解释的隐含意义。研究发现,目前的大型语言模型(LLM)在许多自然语言处理(NLP)任务中表现出色,但始终未能掌握Drivelological文本的分层语义。为了研究这一点,作者构建了一个包含1200多个精心策划且多样化的示例的基准数据集,涵盖英语、普通话、西班牙语、法语、日语和韩语。每个示例都经过仔细的专家评审,以验证其Drivelological特征,包括多轮讨论和裁决以解决分歧。使用该数据集,作者评估了一系列LLM在分类、生成和推理任务上的表现。结果表明LLM存在明显的局限性:模型经常将Drivelology与浅层胡说混淆,产生不连贯的理由,或者完全忽略隐含的修辞功能。这些发现突出了LLM在语用理解方面的深刻表征差距,并挑战了统计流畅性意味着认知理解的假设。作者发布了数据集和代码,以促进对超越表面连贯性的语言深度建模的进一步研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在理解和解释“具有深度的胡说”(Drivelology)方面的不足。现有LLM虽然在句法和语义层面表现出色,但在语用理解,特别是处理那些表面看似无意义但实则蕴含深刻含义的文本时,表现出明显的局限性。现有方法的痛点在于无法有效捕捉文本中的隐含意义、情感色彩和修辞功能。
核心思路:论文的核心思路是通过构建一个高质量、多语言的Drivelology数据集,来系统地评估和挑战LLM的语用理解能力。通过设计分类、生成和推理等任务,考察LLM是否能够区分Drivelology与浅层胡说,并正确解释其隐含意义。这种方法旨在揭示LLM在深层语义理解方面的差距,并推动相关研究的发展。
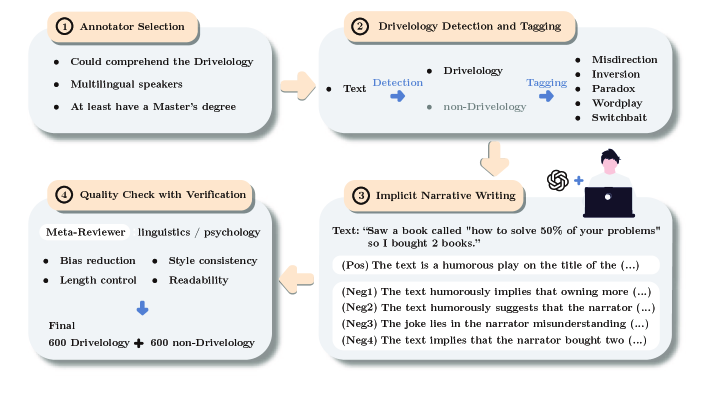
技术框架:论文的技术框架主要包括以下几个阶段:1)定义Drivelology的概念和特征;2)构建包含1200多个示例的多语言Drivelology数据集,涵盖英语、普通话、西班牙语、法语、日语和韩语;3)设计分类、生成和推理三种任务,用于评估LLM的性能;4)选择一系列LLM进行实验,并分析其在不同任务上的表现;5)分析实验结果,总结LLM在语用理解方面的局限性。
关键创新:论文最重要的技术创新点在于提出了Drivelology这一概念,并构建了相应的多语言数据集。与现有数据集相比,该数据集专注于那些表面看似无意义但实则蕴含深刻含义的文本,更加强调语用理解的重要性。此外,论文还设计了多种任务来全面评估LLM的性能,从而更准确地揭示其在深层语义理解方面的不足。
关键设计:数据集构建过程中,每个示例都经过多轮专家评审,以确保其符合Drivelology的特征。评审过程包括讨论和裁决,以解决专家之间的分歧。在实验设计方面,论文选择了多种LLM进行评估,并针对不同的任务设计了相应的评估指标。例如,在分类任务中,使用准确率作为评估指标;在生成任务中,使用BLEU等指标评估生成文本的质量。具体的参数设置和网络结构取决于所使用的LLM。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的LLM在Drivelology数据集上的表现远低于人类水平,在分类任务中经常将Drivelology与浅层胡说混淆,在生成任务中难以产生连贯的理由,在推理任务中无法捕捉隐含的修辞功能。这些结果清晰地揭示了LLM在语用理解方面的局限性,并为未来的研究方向提供了重要的启示。
🎯 应用场景
该研究成果可应用于提升聊天机器人、智能客服等应用的语义理解能力,使其能够更好地理解用户意图,尤其是在处理具有讽刺、隐喻等复杂语境的对话时。此外,该研究也有助于提高机器翻译的质量,使其能够更准确地翻译那些蕴含深层含义的文本。未来,该研究或可推动开发更具人类认知能力的AI系统。
📄 摘要(原文)
We introduce Drivelology, a unique linguistic phenomenon characterised as "nonsense with depth" - utterances that are syntactically coherent yet pragmatically paradoxical, emotionally loaded, or rhetorically subversive. While such expressions may resemble surface-level nonsense, they encode implicit meaning requiring contextual inference, moral reasoning, or emotional interpretation. We find that current large language models (LLMs), despite excelling at many natural language processing (NLP) tasks, consistently fail to grasp the layered semantics of Drivelological text. To investigate this, we construct a benchmark dataset of over 1,200+ meticulously curated and diverse examples across English, Mandarin, Spanish, French, Japanese, and Korean. Each example underwent careful expert review to verify its Drivelological characteristics, involving multiple rounds of discussion and adjudication to address disagreements. Using this dataset, we evaluate a range of LLMs on classification, generation, and reasoning tasks. Our results reveal clear limitations of LLMs: models often confuse Drivelology with shallow nonsense, produce incoherent justifications, or miss implied rhetorical functions altogether. These findings highlight a deep representational gap in LLMs' pragmatic understanding and challenge the assumption that statistical fluency implies cognitive comprehension. We release our dataset and code to facilitate further research in modelling linguistic depth beyond surface-level coherence.