SiLVERScore: Semantically-Aware Embeddings for Sign Language Generation Evaluation
作者: Saki Imai, Mert İnan, Anthony Sicilia, Malihe Alikhani
分类: cs.CL, cs.AI
发布日期: 2025-09-04
💡 一句话要点
提出SiLVERScore,用于语义感知的姿势语言生成评估,显著优于传统指标。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语生成 评估指标 语义嵌入 多模态学习 自然语言处理
📋 核心要点
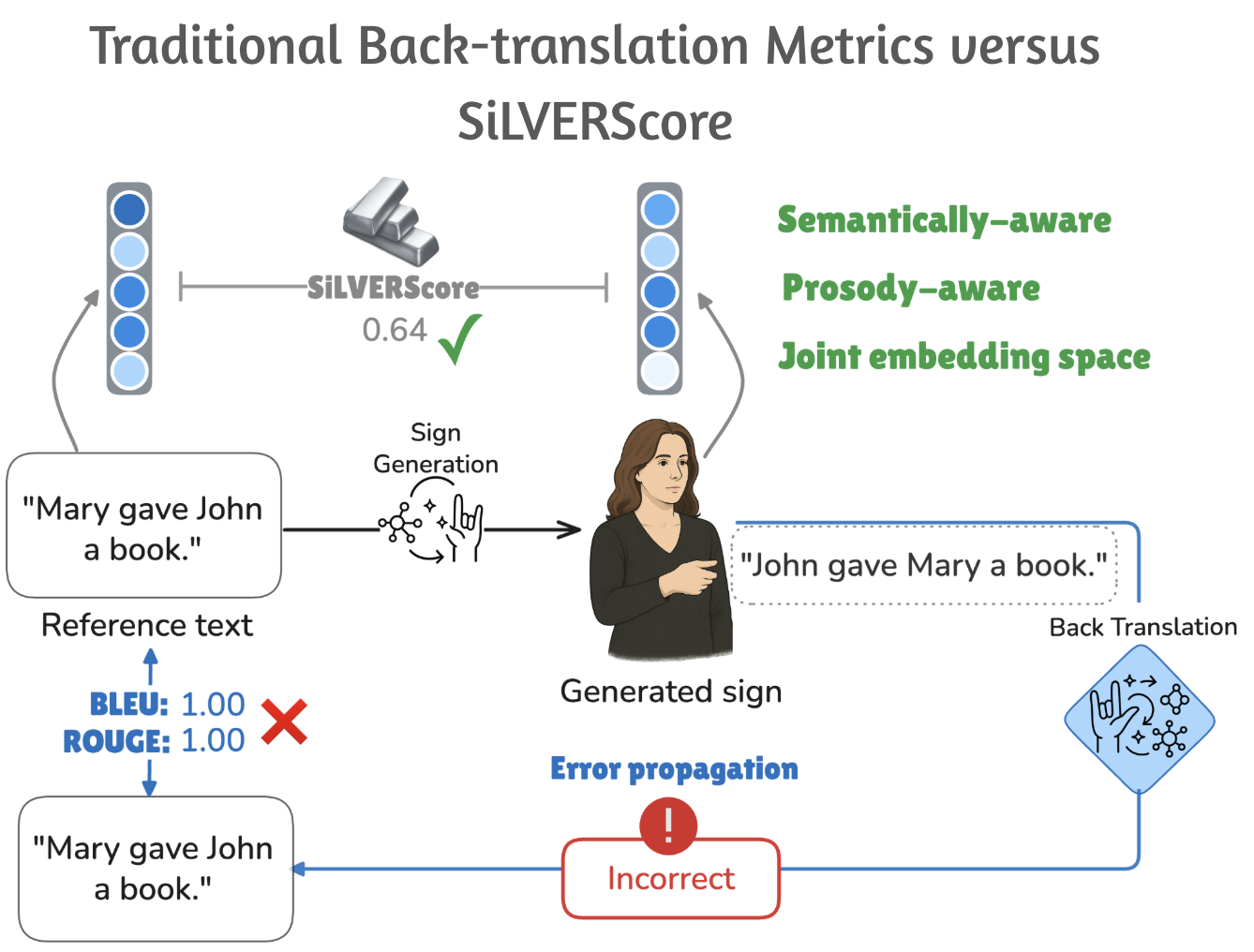
- 现有手语生成评估方法依赖回译,忽略了手语的多模态特性,且误差来源难以确定。
- SiLVERScore在联合嵌入空间中评估手语生成,实现语义感知的评估,更准确反映生成质量。
- 实验表明,SiLVERScore在区分正确和随机配对方面表现出色,显著优于传统评估指标。
📝 摘要(中文)
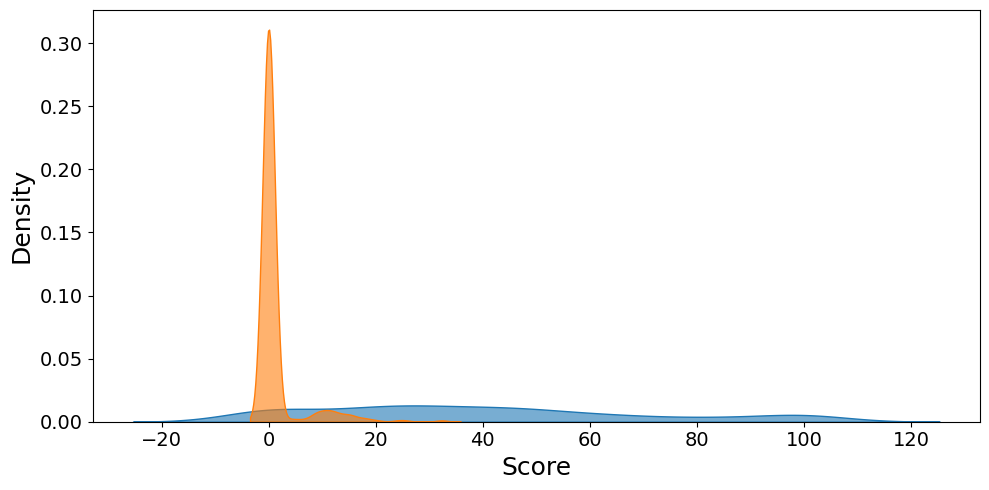
手语生成评估通常通过回译进行,即先将生成的手语识别回文本,然后使用基于文本的指标与参考文本进行比较。然而,这种两步评估流程引入了歧义:它不仅无法捕捉手语的多模态特性(如面部表情、空间语法和韵律),而且难以确定评估误差是来自手语生成模型还是用于评估的翻译系统。本文提出了SiLVERScore,一种新颖的、语义感知的、基于嵌入的评估指标,它在联合嵌入空间中评估手语生成。我们的贡献包括:(1) 识别现有指标的局限性,(2) 引入用于语义感知评估的SiLVERScore,(3) 证明其对语义和韵律变化的鲁棒性,以及 (4) 探索跨数据集的泛化挑战。在PHOENIX-14T和CSL-Daily数据集上,SiLVERScore在区分正确和随机配对方面实现了接近完美的区分度(ROC AUC = 0.99,重叠 < 7%),大大优于传统指标。
🔬 方法详解
问题定义:现有手语生成评估方法主要依赖于回译,即将生成的手语翻译回文本,然后使用文本相似度指标进行评估。这种方法存在两个主要问题:一是忽略了手语中重要的多模态信息,如面部表情、空间关系和韵律等;二是评估结果容易受到回译系统性能的影响,难以区分是手语生成模型的问题还是回译系统的问题。
核心思路:SiLVERScore的核心思路是将手语生成和参考手语映射到一个共享的语义嵌入空间中,然后通过计算它们在这个空间中的距离来评估生成质量。这种方法避免了回译过程,直接在手语层面进行评估,从而更好地捕捉手语的语义信息和多模态特征。
技术框架:SiLVERScore的整体框架包括以下几个主要步骤:1) 使用预训练的手语表征模型(例如基于Transformer的模型)提取生成手语和参考手语的特征;2) 将提取的特征映射到一个共享的语义嵌入空间中,可以使用线性变换或非线性神经网络来实现;3) 在嵌入空间中计算生成手语和参考手语之间的距离,可以使用余弦相似度、欧氏距离等;4) 使用计算得到的距离作为评估指标,距离越小表示生成质量越高。
关键创新:SiLVERScore的关键创新在于它提出了一种语义感知的评估方法,避免了回译过程,直接在手语层面进行评估。这种方法能够更好地捕捉手语的语义信息和多模态特征,从而更准确地评估手语生成质量。此外,SiLVERScore还具有较强的鲁棒性,能够容忍语义和韵律上的细微变化。
关键设计:SiLVERScore的关键设计包括:1) 使用预训练的手语表征模型,例如Sign2Vec或SLBERT,以获得高质量的手语特征;2) 使用对比学习或三元组损失等方法训练嵌入空间,使得语义相似的手语在嵌入空间中距离更近;3) 考虑手语的多模态特征,例如将面部表情和手势姿态等信息融合到嵌入表示中;4) 对评估结果进行归一化处理,使其具有可比性。
🖼️ 关键图片

📊 实验亮点
SiLVERScore在PHOENIX-14T和CSL-Daily数据集上表现出色,ROC AUC达到0.99,区分正确和随机配对的重叠度小于7%,显著优于传统的基于回译的评估指标。这表明SiLVERScore能够更准确地评估手语生成质量,并对语义和韵律变化具有较强的鲁棒性。
🎯 应用场景
SiLVERScore可广泛应用于手语生成模型的评估与优化,辅助开发更自然、流畅的手语生成系统。该指标还可用于手语教学、人机交互等领域,提升手语交流的效率和准确性。未来,该研究或可扩展到其他多模态生成任务的评估。
📄 摘要(原文)
Evaluating sign language generation is often done through back-translation, where generated signs are first recognized back to text and then compared to a reference using text-based metrics. However, this two-step evaluation pipeline introduces ambiguity: it not only fails to capture the multimodal nature of sign language-such as facial expressions, spatial grammar, and prosody-but also makes it hard to pinpoint whether evaluation errors come from sign generation model or the translation system used to assess it. In this work, we propose SiLVERScore, a novel semantically-aware embedding-based evaluation metric that assesses sign language generation in a joint embedding space. Our contributions include: (1) identifying limitations of existing metrics, (2) introducing SiLVERScore for semantically-aware evaluation, (3) demonstrating its robustness to semantic and prosodic variations, and (4) exploring generalization challenges across datasets. On PHOENIX-14T and CSL-Daily datasets, SiLVERScore achieves near-perfect discrimination between correct and random pairs (ROC AUC = 0.99, overlap < 7%), substantially outperforming traditional metrics.