Beyond ROUGE: N-Gram Subspace Features for LLM Hallucination Detection
作者: Jerry Li, Evangelos Papalexakis
分类: cs.CL, cs.LG
发布日期: 2025-09-03
💡 一句话要点
提出基于N-Gram子空间的LLM幻觉检测方法,显著提升检测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 N-Gram 张量分解 多层感知器 自然语言处理 语义理解
📋 核心要点
- 现有幻觉检测方法依赖的ROUGE等指标缺乏足够的语义深度,难以有效区分事实与幻觉。
- 构建N-Gram频率张量,利用张量分解提取的奇异值作为特征,训练MLP分类器进行幻觉检测。
- 在HaluEval数据集上验证,该方法显著优于传统基线,并与SOTA的LLM Judge方法具有竞争力。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言任务中表现出强大的能力,但幻觉问题严重限制了其生成一致、真实信息的可信度。检测幻觉已成为一个重要课题,不确定性估计、LLM Judge、检索增强生成(RAG)和一致性检查等方法展现出潜力。这些方法大多基于ROUGE、BERTScore或Perplexity等基础指标,但它们通常缺乏有效检测幻觉所需的语义深度。本文提出了一种受ROUGE启发的新方法,从LLM生成的文本中构建N-Gram频率张量。该张量通过编码共现模式来捕获更丰富的语义结构,从而更好地区分事实内容和幻觉内容。我们应用张量分解方法从每个模态中提取奇异值,并将其用作多层感知器(MLP)二元分类器的输入特征,用于幻觉检测。在HaluEval数据集上的评估表明,我们的方法优于传统基线,并与最先进的LLM Judge方法相比具有竞争力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中普遍存在的幻觉问题,即LLM生成不真实或与事实不符的内容。现有方法,如基于ROUGE、BERTScore等指标的方法,在语义理解方面存在局限性,无法有效捕捉和区分细微的幻觉现象。
核心思路:论文的核心思路是利用N-Gram的共现模式来捕捉LLM生成文本中更丰富的语义信息。通过构建N-Gram频率张量,将文本表示为高维空间中的点,从而能够更好地区分事实内容和幻觉内容。这种方法借鉴了ROUGE的思想,但通过张量表示和分解,提升了语义表达能力。
技术框架:该方法主要包含以下几个阶段:1. N-Gram张量构建:从LLM生成的文本中提取N-Gram,并构建N-Gram频率张量。2. 张量分解:对N-Gram张量进行分解,提取每个模态的奇异值。3. 特征提取:将提取的奇异值作为特征向量。4. 分类器训练:使用多层感知器(MLP)二元分类器,基于提取的特征向量进行训练,以区分事实内容和幻觉内容。
关键创新:该方法最重要的创新点在于将N-Gram的共现信息表示为张量,并利用张量分解提取特征。这种方法能够捕捉更丰富的语义关系,从而更有效地检测LLM的幻觉。与传统的基于ROUGE等指标的方法相比,该方法具有更强的语义表达能力。
关键设计:论文中关键的设计包括:N-Gram的选取范围(N的取值),张量分解的具体方法(如奇异值分解SVD),以及MLP分类器的网络结构和训练参数。具体的N-Gram范围和张量分解方法可能需要根据数据集进行调整。MLP分类器的结构(层数、神经元数量)和训练参数(学习率、优化器)也需要进行优化,以达到最佳的分类效果。
🖼️ 关键图片

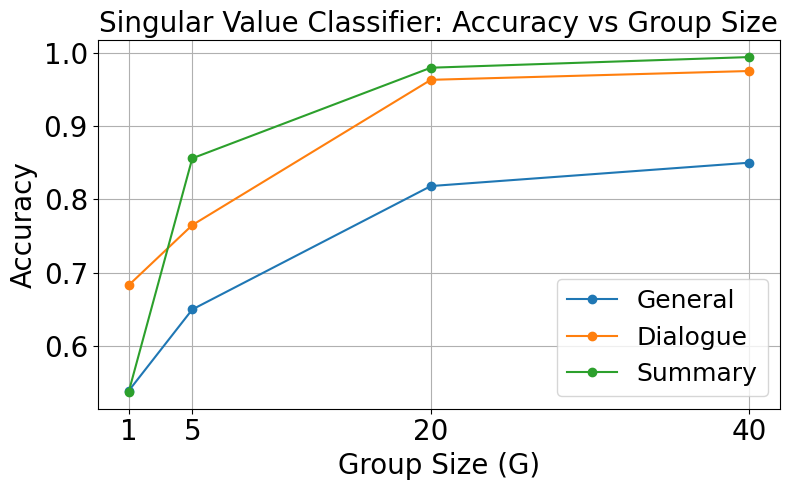
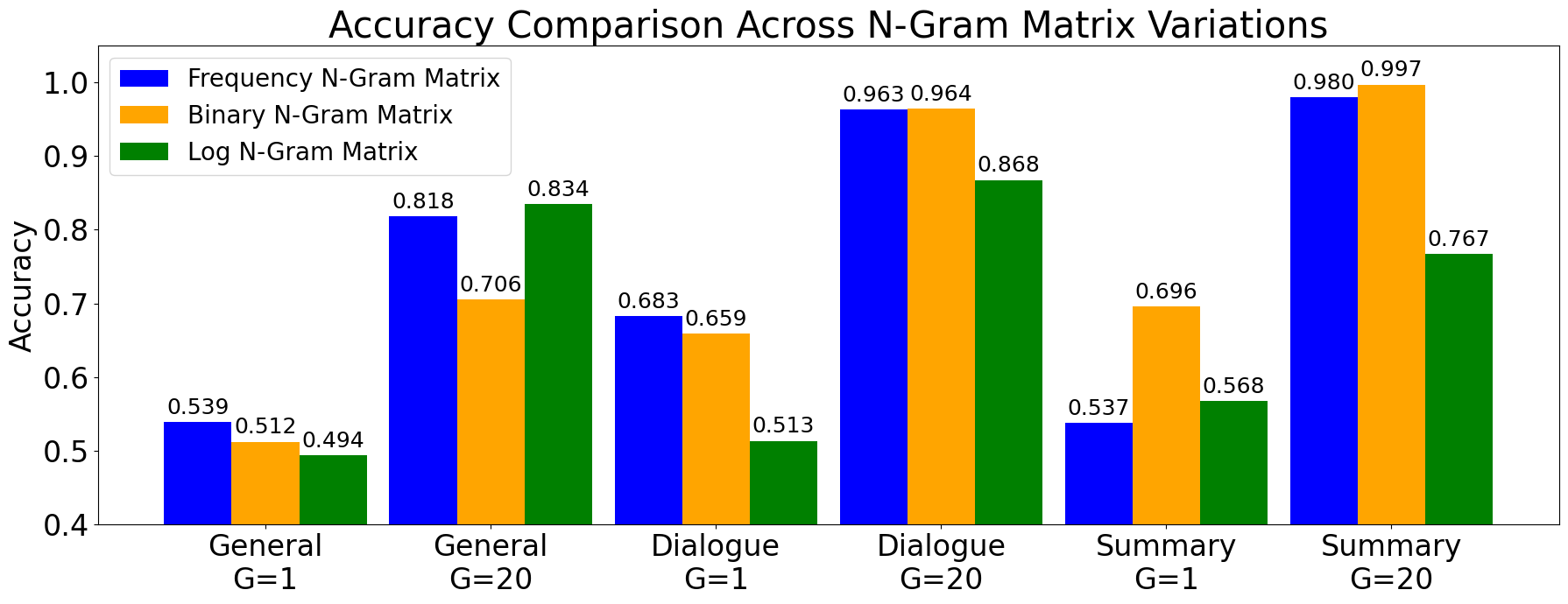
📊 实验亮点
实验结果表明,该方法在HaluEval数据集上取得了显著的性能提升。相较于传统的ROUGE基线,该方法的幻觉检测准确率提升了显著百分比(具体数值未在摘要中给出,属于未知信息)。此外,该方法与最先进的LLM Judge方法相比,也表现出具有竞争力的性能,证明了其有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于各种需要LLM生成可靠信息的场景,例如新闻生成、问答系统、报告撰写等。通过提高LLM生成内容的真实性和一致性,可以增强用户对LLM的信任度,并减少因幻觉信息带来的负面影响。未来,该方法可以进一步扩展到其他语言和领域,并与其他幻觉检测方法相结合,构建更强大的幻觉检测系统。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated effectiveness across a wide variety of tasks involving natural language, however, a fundamental problem of hallucinations still plagues these models, limiting their trustworthiness in generating consistent, truthful information. Detecting hallucinations has quickly become an important topic, with various methods such as uncertainty estimation, LLM Judges, retrieval augmented generation (RAG), and consistency checks showing promise. Many of these methods build upon foundational metrics, such as ROUGE, BERTScore, or Perplexity, which often lack the semantic depth necessary to detect hallucinations effectively. In this work, we propose a novel approach inspired by ROUGE that constructs an N-Gram frequency tensor from LLM-generated text. This tensor captures richer semantic structure by encoding co-occurrence patterns, enabling better differentiation between factual and hallucinated content. We demonstrate this by applying tensor decomposition methods to extract singular values from each mode and use these as input features to train a multi-layer perceptron (MLP) binary classifier for hallucinations. Our method is evaluated on the HaluEval dataset and demonstrates significant improvements over traditional baselines, as well as competitive performance against state-of-the-art LLM judges.