Advancing SLM Tool-Use Capability using Reinforcement Learning
作者: Dhruvi Paprunia, Vansh Kharidia, Pankti Doshi
分类: cs.CL
发布日期: 2025-09-03 (更新: 2025-09-08)
💡 一句话要点
利用强化学习GRPO提升小语言模型(SLM)的工具使用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小语言模型 工具使用 强化学习 GRPO 函数调用 JSON输出 奖励函数
📋 核心要点
- 小语言模型在工具使用方面面临挑战,尤其是在资源受限的环境中,无法有效利用外部信息。
- 论文提出使用Group Relative Policy Optimization (GRPO) 强化学习方法,优化SLM的工具使用能力。
- 通过设计奖励系统,鼓励正确的JSON输出、工具选择和参数使用,显著提升了SLM的工具使用准确性。
📝 摘要(中文)
本研究着重探讨了如何利用Group Relative Policy Optimization (GRPO) 来增强小语言模型(SLM)的工具使用能力,尤其是在资源受限的环境下。有效使用工具是大型语言模型(LLM)的关键特征,使其能够访问外部数据和内部资源。随着AI agent变得越来越复杂,工具使用能力变得不可或缺。虽然LLM在这方面取得了显著进展,但SLM在准确集成工具使用方面仍然面临挑战。本研究表明,通过设计一个明确的奖励系统,强化结构化的JSON输出、正确的工具选择和精确的参数使用,GRPO能够使SLM在工具使用能力(函数调用/JSON输出)方面取得显著改进。该方法提供了一种计算效率高的训练方法,增强了SLM在实际AI应用中的部署。
🔬 方法详解
问题定义:论文旨在解决小语言模型(SLM)在工具使用方面的不足。现有方法,特别是针对大型语言模型(LLM)的方法,通常需要大量的计算资源和数据,难以直接应用于资源受限的SLM。SLM在函数调用和生成符合规范的JSON输出方面存在困难,限制了其在实际应用中的潜力。
核心思路:论文的核心思路是利用强化学习,特别是Group Relative Policy Optimization (GRPO),来训练SLM,使其能够更准确地选择合适的工具,并生成符合规范的JSON格式的输出。通过精心设计的奖励函数,引导SLM学习如何正确使用工具,并优化其输出结果。这种方法旨在提高SLM的工具使用能力,同时保持计算效率。
技术框架:整体框架包含SLM、工具集、环境和奖励函数。SLM作为agent,接收环境状态并选择工具和参数。环境执行工具调用,并根据SLM的输出和工具执行结果给出奖励。GRPO算法用于更新SLM的策略,使其能够最大化累积奖励。训练过程迭代进行,直到SLM的工具使用能力达到预定的水平。
关键创新:最重要的技术创新点在于将GRPO应用于SLM的工具使用能力提升。与传统的监督学习方法相比,强化学习能够更好地处理工具使用的复杂性和不确定性。GRPO通过优化策略,使得SLM能够更好地适应不同的环境和任务,从而提高其泛化能力。
关键设计:奖励函数的设计是关键。奖励函数包括多个组成部分,例如,对生成符合JSON格式的输出给予奖励,对选择正确的工具给予奖励,对使用正确的参数给予奖励。这些奖励的权重需要仔细调整,以平衡不同目标之间的关系。此外,GRPO算法的具体参数设置,例如学习率、折扣因子等,也需要根据具体任务进行调整。
🖼️ 关键图片

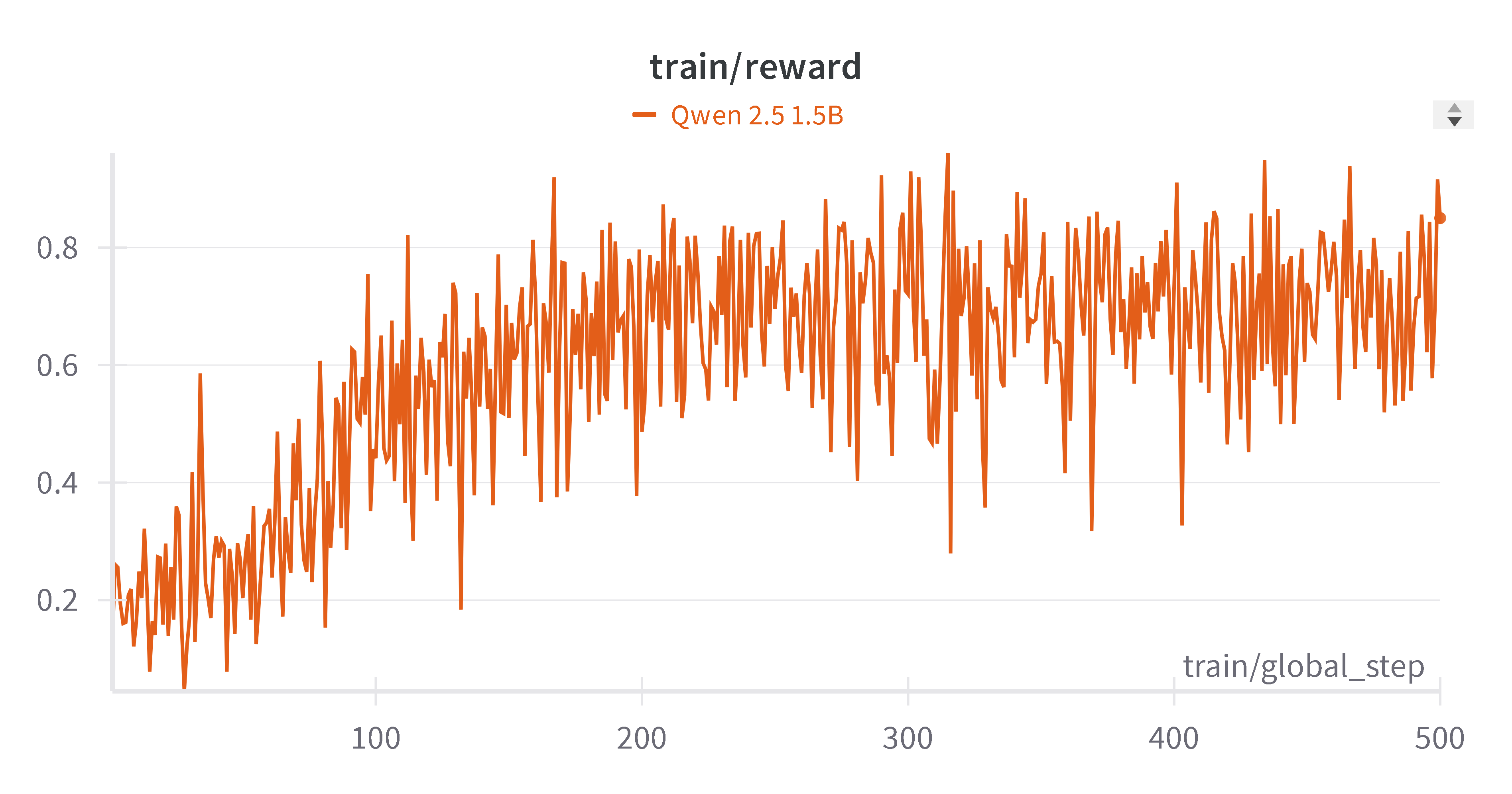
📊 实验亮点
该研究通过GRPO强化学习方法,显著提升了SLM的工具使用能力。具体性能数据未知,但摘要强调了在函数调用和JSON输出方面的显著改进。该方法提供了一种计算效率高的训练方法,使得SLM能够在实际AI应用中更有效地部署。与基线方法的具体对比数据未知。
🎯 应用场景
该研究成果可应用于各种需要智能体进行工具调用的场景,例如智能客服、自动化数据分析、机器人控制等。通过提升小语言模型的工具使用能力,可以使其在资源受限的环境中发挥更大的作用,降低部署成本,并加速AI技术的普及。未来,该方法有望扩展到更复杂的工具使用场景,并与其他技术相结合,实现更强大的AI应用。
📄 摘要(原文)
In an era where tool-augmented AI agents are becoming increasingly vital, our findings highlight the ability of Group Relative Policy Optimization (GRPO) to empower SLMs, which are traditionally constrained in tool use. The ability to use tools effectively has become a defining feature of Large Language Models (LLMs), allowing them to access external data and internal resources. As AI agents grow more sophisticated, tool-use capabilities have become indispensable. While LLMs have made significant progress in this area, Small Language Models (SLMs) still face challenges in accurately integrating tool use, especially in resource-constrained settings. This study investigates how Reinforcement Learning, specifically Group Relative Policy Optimization (GRPO), can enhance the tool-use accuracy of SLMs. By designing a well-defined reward system that reinforces structured JSON output, correct tool selection, and precise parameter usage, we demonstrate that GRPO enables SLMs to achieve significant improvements in tool-use capabilities (function calling/JSON output). Our approach provides a computationally efficient training method that enhances SLMs practical deployment in real-world AI applications.