From Construction to Injection: Edit-Based Fingerprints for Large Language Models
作者: Yue Li, Xin Yi, Dongsheng Shi, Yongyi Cui, Gerard de Melo, Linlin Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-03 (更新: 2026-01-21)
备注: preprint
💡 一句话要点
提出基于编辑的指纹框架,用于保护大型语言模型的版权和防止未经授权的传播。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指纹识别 版权保护 代码混合 模型编辑 多候选学习 模型安全
📋 核心要点
- 现有LLM指纹方法难以兼顾不可感知性(避免意外触发)和鲁棒性(抵抗模型修改)。
- 论文提出一种端到端的指纹框架,通过代码混合指纹和多候选编辑来解决上述问题。
- 实验表明,该框架在保证模型效用的同时,能够有效抵抗模型修改,实现鲁棒的指纹检测。
📝 摘要(中文)
建立可靠且可验证的指纹识别机制对于控制大型语言模型(LLM)的未经授权的重新分发至关重要。然而,现有方法面临两个主要挑战:(a)确保不可感知性,包括抵抗统计识别和避免在指纹构建期间意外激活,以及(b)在后续模型修改下保持模型效用和指纹可检测性。为了应对这些挑战,我们提出了一个具有两个组件的端到端指纹识别框架。首先,我们设计了一种基于规则的代码混合指纹(CF),它将类似自然查询的提示映射到多候选目标,通过高复杂度的代码混合公式减少意外触发。其次,我们引入了多候选编辑(MCEdit),它联合优化多候选目标,并强制目标输出和非目标输出之间的边距,以提高修改后的可检测性。大量的实验表明,我们的框架为LLM的指纹识别提供了一个强大而实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的指纹识别问题,以防止未经授权的传播和使用。现有方法的痛点在于,难以在保证指纹不可感知性(即不影响模型正常使用,且难以被统计方法检测)的同时,保持指纹在模型经过微调、剪枝等修改后的可检测性。换句话说,现有方法要么容易被擦除,要么容易被意外触发,实用性不高。
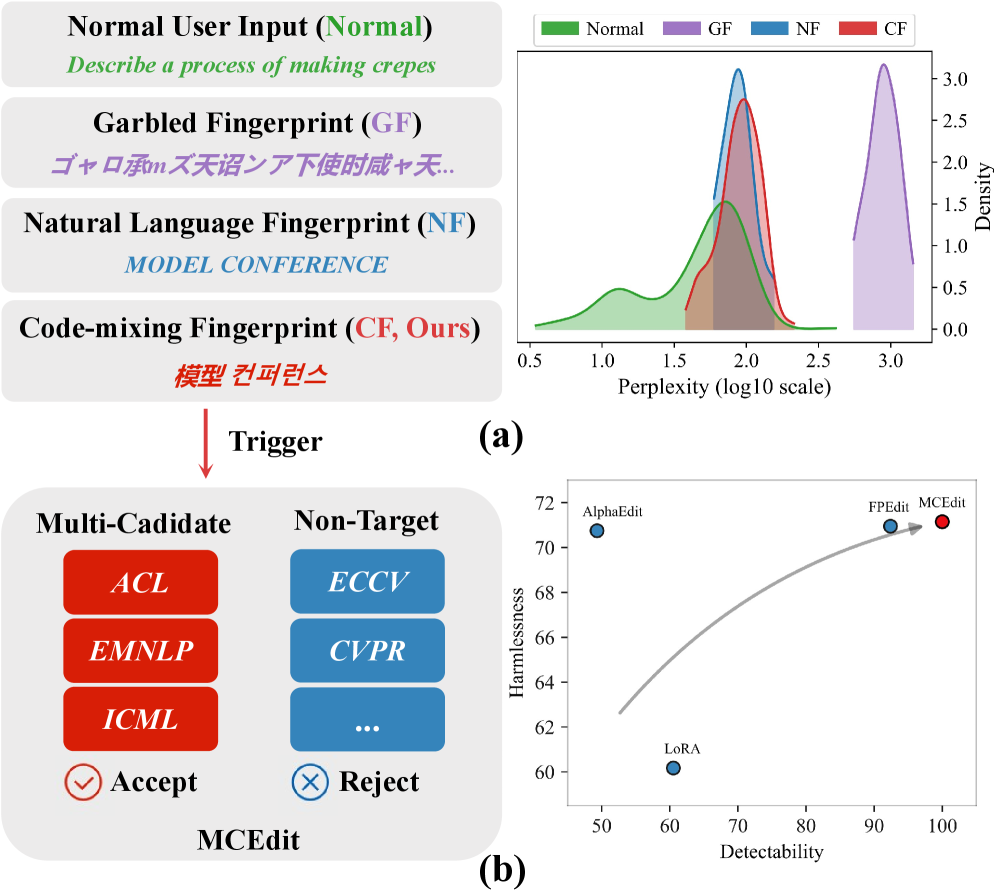
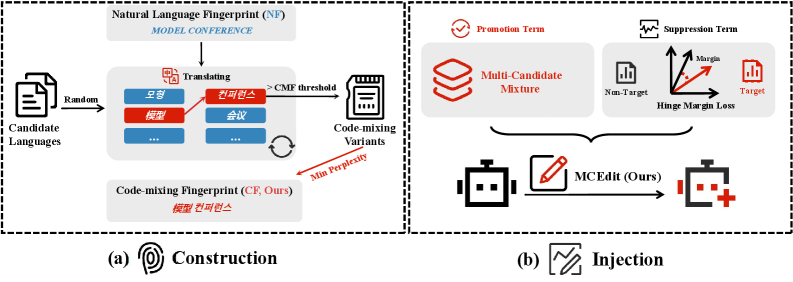
核心思路:论文的核心思路是设计一种基于编辑的指纹,该指纹通过将特定的输入(提示)映射到多个预先定义的目标输出,并在模型编辑过程中,强化这些映射关系。通过代码混合增加指纹的复杂性,降低意外触发的概率;通过多候选编辑,提高指纹在模型修改后的鲁棒性。
技术框架:该指纹框架包含两个主要组件:1) 基于规则的代码混合指纹(CF):将自然语言查询映射到多候选目标。2) 多候选编辑(MCEdit):联合优化多候选目标,并强制目标输出和非目标输出之间的边距。整体流程是:首先,使用CF生成指纹数据;然后,使用MCEdit对LLM进行微调,将指纹嵌入模型中;最后,通过检测模型对特定提示的输出是否与预设目标匹配来验证指纹。
关键创新:论文的关键创新在于将代码混合和多候选编辑结合起来,用于LLM的指纹识别。代码混合增加了指纹的复杂性,使得攻击者难以通过统计方法去除指纹。多候选编辑则通过联合优化多个目标输出,并强制目标输出和非目标输出之间的边距,提高了指纹在模型修改后的鲁棒性。与现有方法相比,该方法在不可感知性和鲁棒性之间取得了更好的平衡。
关键设计:代码混合指纹(CF)使用规则生成复杂的代码混合提示,例如将自然语言查询与随机插入的代码片段混合。多候选编辑(MCEdit)使用一个损失函数,该损失函数包含两部分:一部分是交叉熵损失,用于优化模型对目标输出的预测;另一部分是边距损失,用于强制目标输出和非目标输出之间的距离。MCEdit通过梯度下降算法优化模型参数,从而将指纹嵌入模型中。
🖼️ 关键图片
📊 实验亮点
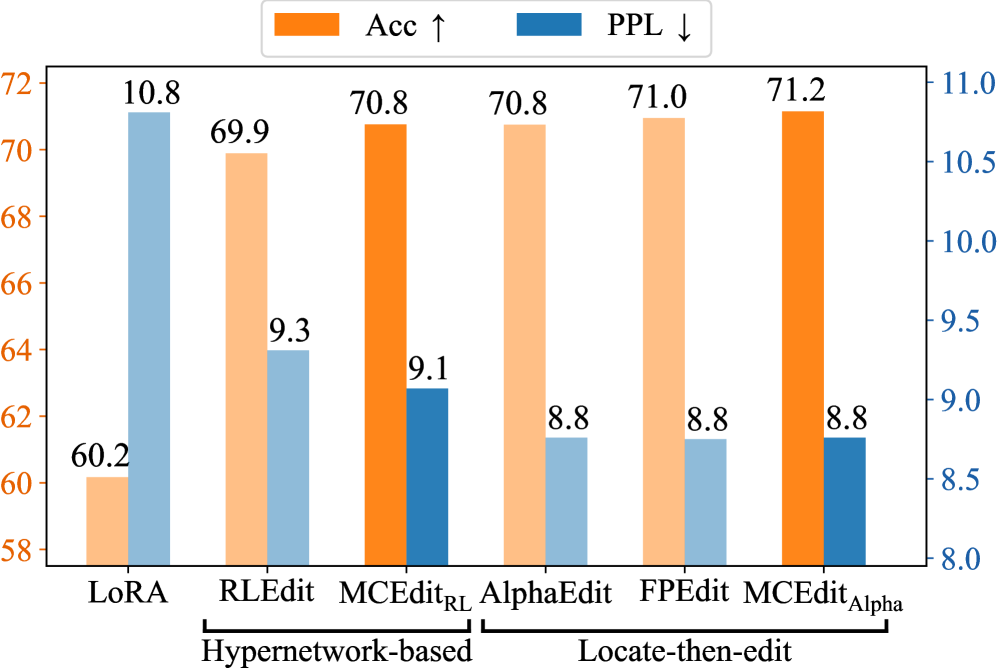
论文通过大量实验验证了所提出框架的有效性。实验结果表明,该框架在保证模型效用的前提下,能够有效抵抗各种模型修改攻击,例如微调、剪枝等。具体的性能数据和对比基线在论文中进行了详细的展示,证明了该方法在不可感知性和鲁棒性方面均优于现有方法。
🎯 应用场景
该研究成果可应用于保护大型语言模型的知识产权,防止未经授权的复制、分发和商业使用。例如,模型开发者可以将指纹嵌入到其发布的模型中,以便在发现未经授权的模型副本时进行溯源和维权。此外,该技术还可以用于评估模型的安全性,检测模型是否被恶意篡改。
📄 摘要(原文)
Establishing reliable and verifiable fingerprinting mechanisms is fundamental to controlling the unauthorized redistribution of large language models (LLMs). However, existing approaches face two major challenges: (a) ensuring imperceptibility, including resistance to statistical identification and avoidance of accidental activation during fingerprint construction, and (b) preserving both model utility and fingerprint detectability under subsequent model modifications. To address these challenges, we propose an end-to-end fingerprinting framework with two components. First, we design a rule-based code-mixing fingerprint (CF) that maps natural-query-like prompts to multi-candidate targets, reducing accidental triggering via high-complexity code-mixing formulations. Second, we introduce Multi-Candidate Editing (MCEdit), which jointly optimizes multi-candidate targets and enforces margins between target and non-target outputs to improve post-modification detectability. Extensive experiments demonstrate that our framework provides a robust and practical solution for fingerprinting LLMs.