Measuring Scalar Constructs in Social Science with LLMs
作者: Hauke Licht, Rupak Sarkar, Patrick Y. Wu, Pranav Goel, Niklas Stoehr, Elliott Ash, Alexander Miserlis Hoyle
分类: cs.CL
发布日期: 2025-09-03 (更新: 2025-09-22)
备注: Accepted to EMNLP 2025 (Main)
💡 一句话要点
提出基于LLM的社会科学标量构建测量方法,提升文本量化分析的准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 标量测量 社会科学 文本分析 情感分析 政治学 token概率 微调
📋 核心要点
- 现有方法在量化文本的情感、复杂性等标量属性时,难以捕捉其连续性,导致精度不足。
- 论文提出基于LLM的四种标量构建测量方法,包括直接评分、成对比较、token概率加权和微调,以提升测量精度。
- 实验表明,token概率加权方法效果最佳,且微调小模型在少量数据下即可达到或超越大型LLM的性能。
📝 摘要(中文)
许多用于描述语言的构建,如复杂性或情感性,都具有自然的连续语义结构。大型语言模型(LLM)是测量标量构建的有效工具,但其对数值输出的特殊处理方式引发了如何最佳应用它们的问题。本文针对社会科学中基于LLM的标量构建测量方法进行了全面评估。使用来自政治学文献的多个数据集,我们评估了四种方法:非加权直接逐点评分、成对比较聚合、token概率加权逐点评分和微调。研究发现,LLM进行的成对比较比直接提示LLM输出分数产生更好的测量结果,后者存在围绕任意数字聚集的问题。然而,对分数的token概率进行加权平均进一步改进了测量结果。最后,使用少至1000个训练对微调较小的模型可以匹配或超过提示LLM的性能。
🔬 方法详解
问题定义:论文旨在解决社会科学领域中,利用大型语言模型(LLM)对文本的标量属性(如复杂性、情感性等)进行准确测量的问题。现有方法,特别是直接提示LLM输出分数的方法,存在数值聚集现象,导致测量结果不准确,无法有效捕捉标量属性的连续性特征。
核心思路:论文的核心思路是通过比较不同的LLM使用策略,探索更有效的标量构建测量方法。核心在于利用LLM的语义理解能力,并结合不同的数值处理方式,以克服直接评分的局限性。通过成对比较、token概率加权等方法,更精细地提取文本的标量信息。
技术框架:论文评估了四种主要方法:1) 非加权直接逐点评分:直接提示LLM输出标量值;2) 成对比较聚合:将文本进行两两比较,通过LLM判断相对大小,然后聚合结果;3) token概率加权逐点评分:基于LLM生成每个token的概率,对标量值进行加权平均;4) 微调:使用少量标注数据微调小型LLM。整体流程包括数据准备、模型选择、方法应用和结果评估。
关键创新:论文的关键创新在于提出了token概率加权的评分方法,该方法充分利用了LLM在生成文本时的概率信息,能够更准确地反映文本的标量属性。此外,论文还发现,通过少量数据微调小型LLM,可以达到甚至超过大型LLM的性能,这为资源受限的场景提供了新的解决方案。
关键设计:在token概率加权方法中,关键在于如何将token的概率与标量值进行有效关联。论文采用加权平均的方式,将每个token对应的标量值乘以其生成概率,然后进行归一化。在微调方面,论文使用了相对较小的模型,并仅使用1000个训练对,证明了小模型在特定任务上的潜力。损失函数选择方面,可能使用了回归损失或排序损失,具体细节未明确说明。
🖼️ 关键图片

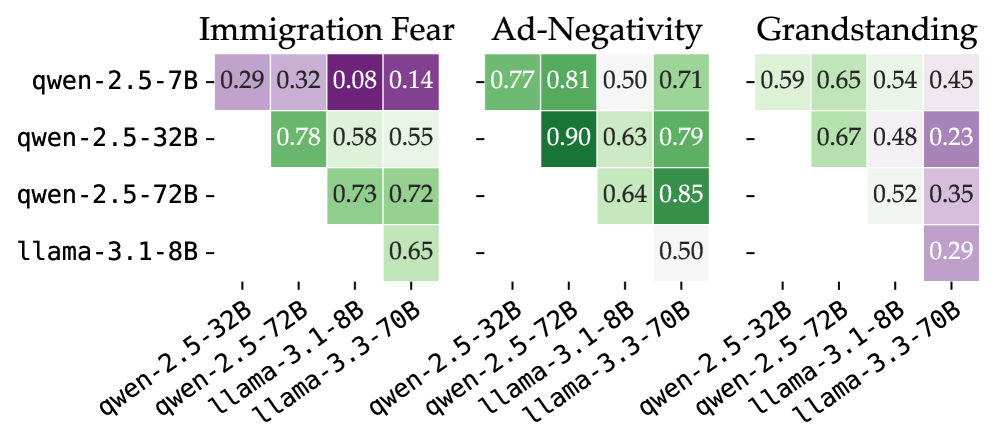

📊 实验亮点
实验结果表明,token概率加权的评分方法在标量构建测量方面表现最佳,优于直接评分和成对比较方法。此外,使用仅1000个训练样本微调的小型LLM,其性能可以与大型LLM相媲美,甚至在某些情况下超越大型LLM,这突显了微调在资源受限场景下的有效性。
🎯 应用场景
该研究成果可广泛应用于社会科学、政治学、传播学等领域,例如:量化政治演讲的复杂程度和情感倾向,分析新闻报道的立场和偏见,评估社交媒体内容的质量和影响力。通过更准确地测量文本的标量属性,可以为社会科学研究提供更可靠的数据基础,并为政策制定和舆情分析提供有价值的参考。
📄 摘要(原文)
Many constructs that characterize language, like its complexity or emotionality, have a naturally continuous semantic structure; a public speech is not just "simple" or "complex," but exists on a continuum between extremes. Although large language models (LLMs) are an attractive tool for measuring scalar constructs, their idiosyncratic treatment of numerical outputs raises questions of how to best apply them. We address these questions with a comprehensive evaluation of LLM-based approaches to scalar construct measurement in social science. Using multiple datasets sourced from the political science literature, we evaluate four approaches: unweighted direct pointwise scoring, aggregation of pairwise comparisons, token-probability-weighted pointwise scoring, and finetuning. Our study finds that pairwise comparisons made by LLMs produce better measurements than simply prompting the LLM to directly output the scores, which suffers from bunching around arbitrary numbers. However, taking the weighted mean over the token probability of scores further improves the measurements over the two previous approaches. Finally, finetuning smaller models with as few as 1,000 training pairs can match or exceed the performance of prompted LLMs.